刘克礼

摘 要:在网络学习平台中,如何有效推荐学习资源具有重要意义。为进一步提高在数据稀疏情况下的关联规则推荐效率,从相似性角度出发,引入学习资源文本信息,通过构建学习资源相似度矩阵,提出一个基于资源相似度的关联规则扩展方法,从而在历史数据稀疏的情况下生成关联规则推荐。实践结果表明,基于同一数据对象进行研究,通过扩展关联规则方法可以提高推荐的有效性和实用性。
关键词:关联规则;Apriori;规则扩展;数据挖掘
DOI:10. 11907/rjdk. 201364 开放科学(资源服务)标识码(OSID):
中图分类号:TP391文献标识码:A 文章编号:1672-7800(2020)007-0158-03
Extension and Application of Association Rules in Data Sparse Cases
LIU Ke-li
(School of Information Engineering ,Anhui Open University,Hefei 230022,China)
Abstract: In the network learning platform, how to effectively recommend learning resources is of great significance. To further improve the efficiency of association rule recommendation in the case of sparse data, from the perspective of similarity, this paper introduces the text information of learning resources, and constructs a similarity matrix of learning resources to propose an association rule expansion method based on resource similarity. Correlation rule recommendation is generated when the data is sparse. The practical results show that the effectiveness and practicability of recommendation can be improved by extending association rules based on the same data.
Key Words: the association rule; Apriori; rule extension; data mining
0 引言
隨着网络学习的快速发展,学习资源的数字化程度不断提高,网络学习平台每天都会产生大量学习记录。如何对这些学习记录进行分析与处理,挖掘隐含在其中的学习规律,从而进一步提高网络学习效率和质量是目前教育研究中的热点问题。关联规则可用于发现隐藏在大型数据集中有意义的联系,是数据挖掘技术中的常用方法[1],已广泛应用于金融、建筑、铁路、航空、医疗等众多领域[2]。Agrawal等[3]在分析大量购物车商品信息的基础上,提出一种基于频繁项集的关联规则挖掘算法,用于分析商品之间的关联关系,其核心就是对频繁项集的挖掘[4-6]。
目前,网络学习平台不断有新的学习资源上线,这些新上线的学习资源由于缺少浏览记录,采用常规数据挖掘方法难以生成有效的关联规则。针对这种缺乏用户历史行为数据的情况,有研究者提出在关联规则基础上进行扩展。如李学明[7]认为关联规则模型中隐藏的肯定关系与否定关系同样重要,并将扩展型关联规则与原关联规则相结合,提高了扩展关联规则挖掘效率;董俊[8]提出利用多维关联规则的本体规则扩展方法进行关联规则扩展,发现该方法可以提高分类准确率和召回率;Abbache等[9]提出在数据挖掘中,除对历史行为数据进行挖掘外,还可以挖掘资源本身的信息。本文在研究学习平台中学习资源相似性的基础上,引入学习资源文本描述信息,以向量形式表示学习资源,通过计算向量之间的余弦相似度,构建相似度矩阵,通过扩展关联规则方法,实现在用户历史行为数据稀疏情况下对学习资源的高效推荐。
1 用户数据稀疏情况下关联规则扩展
通过数据收集、数据清理、关联分析与相似度计算等步骤生成关联规则。
1.1 数据收集与数据清理
1.1.1 数据收集
采用数据收集与数据存储技术可以积累海量数据。在线学习平台每天都有大量活跃用户,这些用户的网上学习行为会产生大量数据,包含用户浏览的视频、文本及课程论坛互动信息等,同时平台还记录了用户学习时长、资源点击频率等。这些快速积累的海量数据对于获得有价值的信息具有重要意义。
1.1.2 数据清理
学生在网络学习平台学习的过程中,也会产生随机、杂乱、无目的浏览记录[10]。其在学习中也不是一次性浏览课程所有资源,通常按照教学要求进行阶段性的学习。平台中存在部分学生为完成学习任务而随意点击的数据,也存在着为“挂学时”而产生的数据等[11],这也是无法避免的数据质量问题,因此需要对数据进行检测与纠正,也即进行数据清理。
1.2 关联规则挖掘
本文基于频繁项集理论[12],采用循环生成频繁项集的方法[13],通过基于支持度的剪枝技术去掉非频繁项[14],然后对频繁项集进行运算得到扩展的关联规则。
1.3 学习资源相似度计算及关联规则扩展
关联规则挖掘的目的就是找出具有相似属性的资源。通常关联规则挖掘算法需要根据用户历史行为和兴趣,预测用户未来的行为和兴趣,因此需要大量用户数据作为支撑。若用户历史行为数据不足,如刚上线的学习资源以及缺少浏览量的学习资源等,就会因缺乏置信度而无法生成关联规则。因此,针对相关学习资源,可通过构建资源相似度矩阵,同时以资源文本描述信息作为补充进行关联规则挖掘。用户在学习平台中浏览了资源A,通过计算资源的文本描述信息,若能发现资源B与资源A具有一定相似度,则推断用户可能会对学习资源B感兴趣,也即是说,资源B对其具有同样重要的学习价值。通过关联规则算法挖掘到的规则“资源A=>资源B”,若有一个学习资源C与资源B具有一定相似度,甚至在学习价值上可能超过资源B,则对于学习者来说,学习资源C和学习资源B给其带来的收获大致相同,甚至体验更好。说明在关联规则“资源A=>资源B”的基础上,如果学习资源C与学习资源B具备一定相似度,则“资源A=>资源C”可作为一条关联规则纳入频繁项集。
通过上述方法可构建学习资源相似度矩阵,对关联规则进行扩展,最终实现在历史数据稀疏条件下的学习资源推荐。要实现上述情况下的资源推荐,关键在于对关联规则进行扩展,其核心就是计算学习资源的相似度。
1.3.1 学习资源相似度计算
对于学习资源相似度计算,在增加学习资源文本信息的基础上,利用向量空间模型描述学习资源,将学习资源表示成一个关键词向量,然后通过余弦相似度计算构造相似度矩阵。具体步骤如下:首先把学习资源按特征维度进行划分,按文本分词形式处理权重。用维度向量表示学习资源,如学习资源d可表示成一个关键词向量:di={(e1,w1),(e2,w2),…(ei,wi )…}。其中,ei表示关键词,wi表示关键词对应权重。利用信息检索邻域的TU-IDF公式计算关键词权重:
[wi=TF(ei)logDF(ei)]
学习资源相似度可通过计算向量之间的余弦相似度得到,具体公式如下:
通过公式可计算出不同学习资源的相似度,并构造一个学习资源相似度矩阵,从而求得任意两学习资源之间的相似度。
1.3.2 关联规则扩展
为了更好地在数据稀疏的情况下计算学习资源相似度,并通过计算找出相似度高的学习资源,在进行规则扩展时,将规则置信度与学习资源相似度的乘积作为扩展后规则的置信度。针对已有规则<资源A=>资源B ,conf=x>,即对学习资源A感兴趣的用户有x的概率对学习资源B感兴趣,通过计算发现,学习资源C与学习资源B的相似度为y,且x与y的乘积符合置信度要求,从而得到新规则< 资源A=>资源C,conf=x*y >,即对学习资源A感兴趣的用户有x*y的概率对学习资源B感兴趣。采用这种计算方法,可实现对关联规则按置信度进行扩展。
2 实例分析验证
2.1 数据处理
本研究使用的數据来自某高校网络学习平台,该平台是以计算技术为基础的集约化一站式学习平台,每天都有海量学习记录数据产生,这些数据真实、可靠,可用于数据挖掘研究。本文主要采用《计算机应用基础》课程数据进行实证研究,该课程是一门公共基础课,每学期约有1万名学生选修该课程。课程网络资源丰富,包括文本辅导、精讲视频、经典案例、在线测验等,另外课程讨论区也有大量学习资源,如学生学习心得、问题回复等。选取2019春季学期学生的学习记录,剔除没有学习行为,以及学习行为数量较少的学习记录,得到有效选课数据8 578条。研究发现,96.68%的学习记录里包含的学习资源个数在30以内。参照数据挖掘中的数据清洗规则,剔除部分异常数据记录,最终得到21 251条学习记录。
2.2 关联规则挖掘及扩展
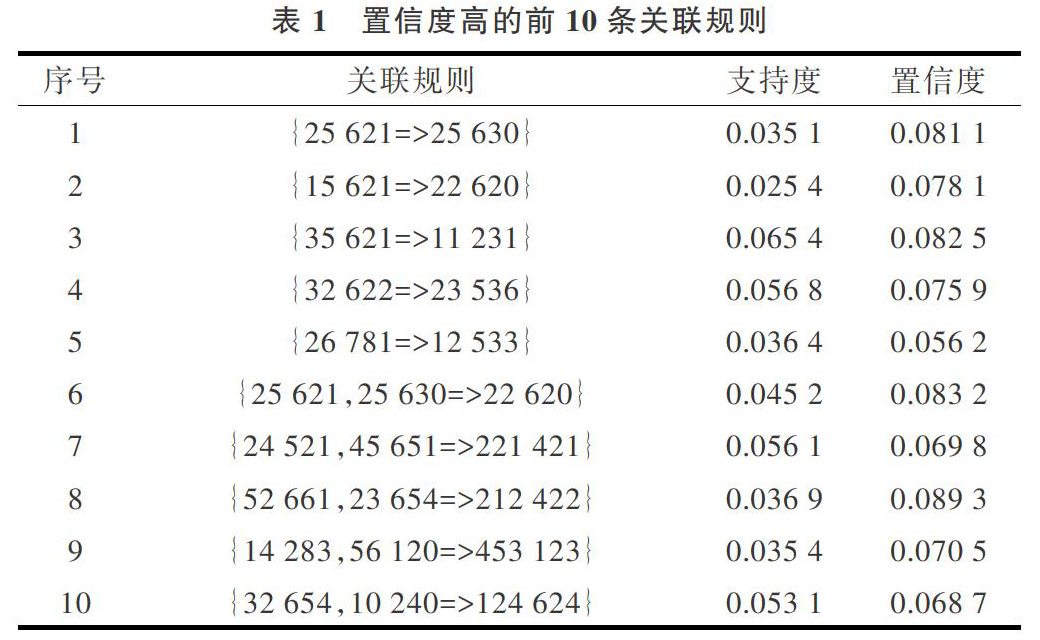
通过Apriori算法对上述步骤得到的21 251条学习记录进行关联规则分析。选取支持度大于0.03,同时置信度大于0.05的关联规则进行分析,共挖掘出104条关联规则。按置信度从高到低排序,选择前10条关联规则如表1所示。
在上述关联规则挖掘基础上,针对用户历史行为数据稀疏的情况,引入学习资源文本描述信息,以向量形式表示学习资源,通过计算向量之间的余弦相似度,得到扩展的关联规则。为了研究的需要,本文将扩展后关联规则的置信度从0.05提升到0.07,只保留置信度在0.07之上的学习资源。
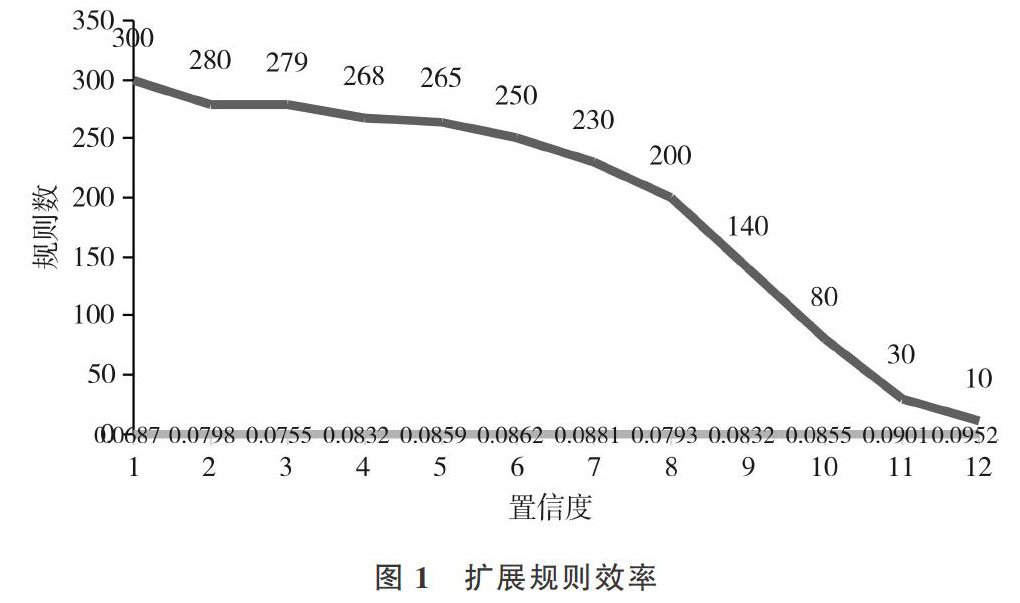
通过对比发现,利用Apriori算法挖掘到的关联规则数量与规则扩展后的数量都是随着置信度提高而逐渐下降的。当置信度小于0.085时,扩展得到的关联规则数量都比原关联规则数量多。随着置信度不断增加,扩展得到的关联规则数量则逐渐减少,如图1所示。
从图中可以发现,在置信度小于0.085时使用扩展规则,得到的关联规则数量随着置信度增加呈现平缓的态势,说明使用规则扩展方法能保持一个相对稳定的扩展效率。随着置信度不断增加,特别是当置信度大于0.085后,得到的扩展关联规则数量不断减少,说明高度相似的学习资源数量会随着相似度提高而逐渐减少。总体来看,规则扩展能实现在用户历史行为数据稀疏情况下生成关联规则,且提高数据关联的效率和实用性。
3 结语
本文从学习资源相似度角度出发,兼顾学习者历史行为数据和学习资源文本描述信息,在历史行为数据稀疏的情况下,通过构建学习资源相似度矩阵,提出一个基于学习资源相似度的关联规则扩展方法。最后依托在线学习平台真实的学习记录进行实验,证明扩展的关联规则能在历史行为数据稀疏的情况下,提高数据挖掘的效率和实用性。
在信息化快速发展的时代,先进的信息技术在教育领域的应用越来越广泛、深入,通过分析在线学习平台积累的各类数据,可挖掘出更多隐藏其中有价值的信息,这对于提高学习效率、提升教学质量具有重要意义。
参考文献:
[1] WU X, KUMAR V, QUINLAN J R, et al. Top?10 algorithms in data mining[J]. Knowledge & Information Systems,2007,14:1-37.
[2] 王晓丽,奚克敏,刘占波,等. 基于Apriori算法的关联规则分析[J]. 软件,2019,40(2):23-26.
[3] AGRAWAL R. Mining association rules between sets of items in large databases[C]. Proceedings of the ACM SIGMOD Conference on Management of Data,1993.
[4] CZIBULA G, MARIAN Z, CZIBULA I G. Detecting software design defects using relational association rule mining[J]. Knowledge & Information Systems, 2015, 42:545-577.
[5] LIU Z, HU L, WU C, et al. A novel process-based association rule approach through maximal frequent itemsets for big data processing[J]. Future Generation Computer Systems, 2017 ,81:414-424.
[6] RACHBUREE N,ARUNRERK J,PUNLUMJEAK W. Failure part mining using an association rules mining by FP-growth and apriori algorithms: case of ATM maintenance in Thailand[C].? International Conference on IT Convergence and Security, 2017.
[7] 李学明,刘勇国,彭军,等. 扩展型关联规则和原关联规则及其若干性质[J]. 计算机研究与发展,2002(12):1740-1750.
[8] 董俊,王锁萍,熊范纶,等. 基于多维关联规则的本体规则扩展方法[J]. 模式识别与人工智能,2009,22(5):756-762.
[9] ABBACHE A, MEZIANE F, BELALEM G, et al. Arabic query expansion using WordNet and association rules[J]. International Journal of Intelligent Information Technologies, 2016,12:51-64.
[10] 代红,吴文凯,任玲,等. 网络学习行为分析与预测的研究[J]. 通讯世界,2019,26(10):28-29.
[11] 刘培艳. 从资源共享视角探究开放大学数字化教育资源应用现状[J]. 天津职业院校联合学报,2018,20(6):100-105.
[12] 陈可嘉,赵政. 用戶交易数据不足情况下的商品关联规则扩展与应用[J]. 福州大学学报(哲学社会科学版),2019,33(1):42-47.
[13] 尹远,朱璐伟,文凯. 基于差异点集的频繁项集挖掘算法[J]. 计算机工程与设计,2020,41(3):716-720.
[14] 谢修娟,莫凌飞,朱林. 基于关联规则的滥用入侵检测系统的研究与实现[J]. 现代电子技术,2017,40(2):43-47.
(责任编辑:黄 健)
- 基于国外医保基金监管经验的我国医保基金监管完善对策研究
- 机械式立体车库的火灾特点分析及危险性探究
- 高校人力资源管理专业面临的机遇与挑战
- 计算机网络技术创新构建与研究
- 优化民航飞行程序降低机场噪声影响
- 建筑施工技术管理优化措施的探讨
- 内燃机车的检修和保养工作探讨
- 新地理信息时代的信息化测绘
- 创业胜任力与创业绩效关系研究综述
- 新型城镇化进程中的失地农民就业路径探索
- 地铁车辆受电弓及车顶状态在线检测系统
- 19100DWT浮箱吊臂相向锥度孔专用镗杆设计
- 论EPC模式下核电站运营方对工程文件电子文件接收过程中的前端控制思想
- 党员积分制管理的实践与体会
- 铁路客运产品优化设计探讨
- 生活垃圾焚烧发电厂运行与管理分析研究
- “双创时代”大学生创业教育的困境及对策研究
- 企业岗位薪酬体系设计
- 低碳环保技术在环境治理中的应用分析及阐述
- 95598工单质量提升方法
- 绿色建筑技术节能分类探讨
- CFB—FGD半干法脱硫技术的应用
- 故障诊断技术在矿山机电设备维修中的应用
- 影响企业创新能力的因素研究
- 综合物探技术在地质勘探中的应用分析
- disclaimed
- disclaimer
- disclaimers
- disclaiming
- disclaims
- disclass
- discless
- disclike
- discloister
- disclose
- disclosed
- discloser
- disclosers
- discloses
- disclosing
- disclosure
- disclosures
- disclosure's
- disco
- discoed
- discoing
- discolor
- discoloration
- discolorations
- discolorment
- 籑
- 籔
- 籙
- 籚
- 籚矜
- 籛
- 籜
- 籝
- 籟
- 籠
- 籢
- 籣
- 籥
- 籥口
- 籥牡
- 籥章
- 籧
- 籧篨
- 籩
- 籩巾
- 籩祭
- 籪
- 籬
- 籮
- 籰