李兵++吴伟明


摘要:21世纪以来,伴随着互联网和通信技术的不断发展以及电子商务实践的不断深入,电子商务平台正在展现出前所未有广阔的前景。同时,网络购物快速发展的同时也出现了一些亟待解决的实际难题,用户的增多,商品的繁多,电商平台模式已经进入了大数据时代,及时再强大的单个数据库也无法支持,解决方式就是分布式数据库,近几年分布式成为热门的话题,也成为大型Web应用系统必备良药,而在数据库方面应用更加广泛。通过采用普通廉价的设备构建出高可用性和高扩展的集群目的。从而摆脱了大型设备的依赖,一个好的分布式数据库架构可以比较方便达到高可用性有可以达到向外扩展的能力。但是分布式存储就必须面临分布式事务,本文提出一种方法能够避免分布式事务带来的效率问题。
关键词:分布式事务;分布式存储;消息队列;数据冗余
中图分类号:TP311.13
文献标识码:A
DOI: 10.3969/j.issn.1003-6970.2015.11.017
0 引言
在分布式数据库系统中,分布式事务管理是一个极其重要而复杂的过程事务管理的目标必须达到数据的正确性、执行的并发性以及任务完成的高效性。为此,分布式事务管理除了基本的保证外还要综合考虑效率指标,即维持合理的响应时间、控制通信成本、CPU和内存的利用率等等。由于电子商务的海量数据,大部分Web应用都需要部署多个数据库实例。分库分表的技术也被常常使用,不可避免地,一些操作就可能需要去修改多个数据库或者多个数据库表的实例中的数据。传统的解决方法是使用分布式事务保证数据的全局一致性。在分布式系统中,从理论上讲,两台机器理论上无法达到一致的状态,需要引入一个单点进行协调。事务管理器控制着全局事务,管理事务生命周期,并协调资源。资源管理器负责控制和管理实际资源(如数据库或JMS队列),经典的方法是使用两阶段提交协议。
1 分布式事务的缺点
长期以来,分布式事务提供的优雅的全局ACID保证麻醉了应用开发者的心灵,很多人都不敢越雷池一步,想像没有分布式事务的世界会是怎样。如今就如MySQL和Postgre SQL这类面向低端用户的开源数据库都支持分布式事务了,开发者更是沉醉其中,不去考虑分布式事务是否给系统带来了伤害。
事实上,有所得必有所失,分布式事务提供的ACID保证是以损害系统的可用性、性能与可伸缩性为代价的。
可用性:只有在参与分布式事务的各个数据库实例都能够正常工作的前提下,分布式事务才能够顺利完成,只要有一个工作不正常,整个事务就不能完成。这样,系统的可用性就相当于参加分布式事务的各实例的可用性之积,实例越多,可用性下降越明显。
性能:从性能和可伸缩性角度看,首先是事务的总持续时间通常是各实例操作时间之和,因为一个事务中的各个操作通常是顺序执行的,这样事务的响应时间就会增加很多;其次是一般Web应用的事务都不大,单机操作时间也就几毫秒甚至不到1毫秒,一但涉及到分布式事务,提交时节点间的网络通信往返过程也为毫秒级别,对事务响应时间的影响也不可忽视。
吞吐率:由于事务持续时间延长,事务对相关资源的锁定时间也相应增加,从而可能严重增加了并发冲突,影响到系统吞吐率和可伸缩性。
2 避免分布式事务的常用方法
业界现在最流行的是采用消息队列的方式消除分布式事务的,但是通常会引入一个消息分发功能的中间件,这就不可避免的会发生如果消息中间件出错后整个系统会不可用,如果是消息中间件集群的话,但是多个数据库实例以一个消息中间件为中心,中心崩溃,影响太大。
采用消息队列技术带来的好处是:由于异步通信,无论是发送方还是接收方都不用等待对方返回成功消息,就可以执行余下的代码,因而大大提高了事物处理的能力
3 数据冗余技术和消息队列的模型避免分布式
可以利用数据冗余技术和消息队列的模型把分布式事务划分为多个本地事务,性能大大提高,下面举例说明:
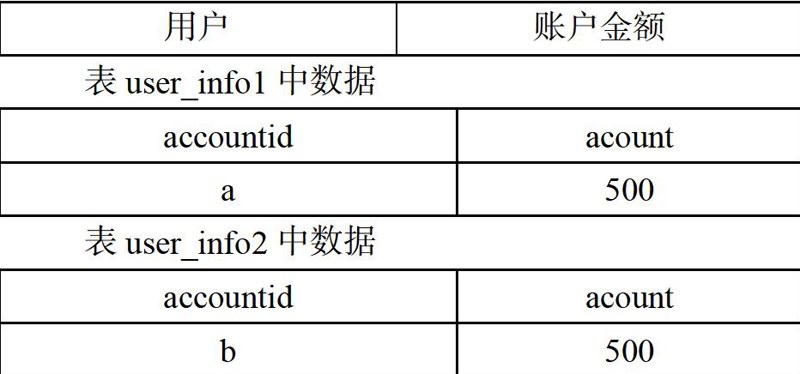
在数据库A、B有两个表,结构相同,同为:
假设有一个转账操作,用户A(账户有500元)向用户B(账户有500元)转账100元的操作,这就涉及了两个操作:
操作1:将A账户减100元Update user_infol setaount-100 where accounted=a:
操作2:将B账户加100元Update user_infol setaount+100 where accounted=a:
那么怎么操作这两个操作保证转账正确呢?
一般我们会在业务上这么做:
假设user_infol表和user_info2表存储在不同的节点上,那么上述事务就是一个分布式事务。要消除这一分布式事务,将它拆分成两个本地子事务,一个更新user_info1表,一个更新user_info2表是不行的,因为有可能user_info1表更新成功后,更新user_info2失败,系统将不能恢复到一致状态。
如何将它分解成两个本地事务呢?首先我们引入各在两个数据库中创建两个冗余表,格式如下:
意义:代表在表user_info1中操作的同时,要在user inf02中要做的操作
意义:代表在表user_info2中操作的同时,要在user_inf02_log中保存做过的记日志。
下面说一下具体怎么操作:
步骤1.在数据库A中操作执行以下语句:
执行结果为:
步骤2.
另外在一个异步事务时刻运行时,它执行:
1.查询数据库A中user_info1_log表中数据,假设查询到数据
2.查询数据库B中user_info2中是否存在UId=1的数据即执行语句
SELECT count(*)as count FROM uuser_infol_log WHERE uid='l';
3.如果count等于0则执行user_infol_log中数据中sqlstr字段值
即语句Update user_info2 set aount+100 whereaccounted=b:
同时执行:
insert to user_info2_log values(l,"Update user_info2 set aount+100 where accounted=b;"
执行结果为
如果count不等于0,则不执行任何操作
步骤3.
删除user_info1_log中数据即
DELETE FROM user_info1_log WHERE id=‘1;
步骤4.
删除user_info_log中数据
DELETE FROM user_info2_log WHERE uid=l;
4 最终一致性如何保证
数据最终一致性指在分布式数据库中各结点的数据,不要求每一时刻都严格保持一致,只保证最终的一致即可。
下面分析一下以上4步骤怎么保证一致性的
l、user infol表与user_info1_log表使用同一实例,因此在第一步中不涉及分布式操作;
2、user_info2与user_info2_log表在同一个实例中,也能保证一致性;
3、步骤2结束后,删除user_infol_log中记录之前系统可能出故障,出故障后系统会重新从user_infol_log中取出这一记录,但通过user_inf02_log表可以检查出来这一记录已经被执行过,跳过这一记录实现正确的行为;
4、最后将已经成功执行,且已经从user_infol_log中删除的记录从user_info2_log表中删除,可以将user_info2_log表保证在很小的状态(不清除也是可以的,不影响系统正确性)。由于user_infol_log与user_info2_log在不同实例上,删除user_infol_log记录之后,将对应user_info2_log记录删除之前可能出故障。一但这时出现故障,user_inf02_log表中会留下一些垃圾内容,但不影响系统正确性,另外这些垃圾内容也是可以正确清理的。
其中user_infol_log类似于消息队列,异步线程可以不断地从user_infol_log表中的数据,再根据判断user_inf02_log中是否存在来决定对user_info2的操作。系统中user_infol_log表、user_info2_log表是冗余数据,所以利用消息队列和两个冗余表可以把一个分布式事务分解成两个本地事务。
- 关注生活 抒写真情
- 考查关键能力和核心素养 引领高考语文内容改革
- 巧借生物学课堂培养学生理性思维
- 基于信息化视角下的中职数学教学策略
- 高中生生物实验能力培养策略
- 搭建“导”的平台提升化学教学参与度
- 培养学生数学思维能力的三种策略
- 高中数学教学中思维能力培养探究
- 信息技术在农村高中英语口语教学中的 有效应用
- 微课在高中英语教学中的应用
- 试论高中学生英语阅读 从“窄”到“宽”的引导
- 构建高效中职政治课堂的有效途径
- 艺术中职语文教学与地方戏曲融合探究
- 基于过程观的古典诗歌赏读能力培养
- 信息技术背景下的诗词教学探讨
- 农村高中英语口语教学存在的问题与对策
- 中职一年级学生幸福感状况调查与分析
- 广西职业院校中高职衔接合作办学 现状的调查与分析
- “校企融合、产训一体、一专多能” 人才培养模式的构建与实施
- 职业技能大赛 推动中职信息技术专业发展的实践探索
- 职业道德教育走出窘境的对策
- 基于核心素养理论的地理实践力培养
- 在宏观辨识与微观探析中培养化学核心素养
- 丰富实验类型培养化学核心素养
- 培养抽象思维能力 发展物理核心素养
- overtwisting
- overtwists
- overtype
- overurge
- overurged
- overurges
- overurging
- overused
- over-used
- overuses
- overusing
- overutilization
- overutilizations
- overutilize
- overutilized
- overutilizes
- overutilizing
- overvaliant
- overvaliantly
- overvaliantness
- overvaliantnesses
- overvaluable
- overvaluableness
- overvaluablenesses
- overvaluably
- 缩朒
- 缩栗
- 缩气
- 缩气音
- 缩水
- 缩水房
- 缩水楼
- 缩然
- 缩瑟
- 缩甲
- 缩略构词现象
- 缩略词
- 缩略语
- 缩略语词典
- 缩着头
- 缩着脖子
- 缩着脖子做人
- 缩着脖子挨刀
- 缩短
- 缩短寿命
- 缩砂密
- 缩编
- 缩缩
- 缩缩朒朒
- 缩缩蹑蹑