王岩++王纯
摘要:伴随着互联网和移动互联网的发展,各种新兴应用层出不穷,对大数据处理的实时性和高并发能力要求也在不断提高。Apache Kafka,作为一种分布式的消息系统,具有可水平扩展和高吞吐率而被广泛的使用。对于数据业务的基础支撑系统,除了能够满足高并发度和实时性以外,数据的质量即数据可靠性也是关键的一环。但是,由Kafka原生提供的数据消费者不能够保障数据的可靠性。本文首先简单介绍了Kafka的组成、架构特性等技术背景,然后阐述了原生Consumer的原理和缺陷;最后,基于Kafka提出一个可靠的消费者的设计方案。本方案是基于Kafka的low-level的接口集,解决了Kafka原生Consumer由于将用户消费数据的动作与数据消费位置的记录独立而引起的数据质量问题,保障了数据的可靠性。最后,搭建Kafka集群测试环境,验证了方案的可行性和正确性。
关键词:Kafka;数据可靠性;zookeeper;实时
中图分类号:TP311.5
文献标识码:B
DOI: 10.3969/j.issn.1003-6970.2016.01.015
0 引言
随着互联网行业的不断发展,各种业务的数据量不断增多,在大数据处理环境下,对数据的实时性要求不断提高。笔者原有的技术环境采用ftp技术作为数据传输手段和传统关系型数据库和文件系统作为存储介质,效率较低,无法满足客户对数据实时性的要求。Apache KafkaⅢ,作为一种分布式的消息系统,具有可水平扩展、高吞吐率和实时性而被广泛的使用。笔者为迎合项目的需求采用Kaika作为数据订阅和发布系统,完成数据的传输和缓存功能。最初,由于初学Katka采用Kafka原生提供的High Level的Api,编写数据生产者和消费者。随着使用的深入和业务数据量的增大,发现数据质量不能得到保障,虽然偏差不大,但是对于某些敏感数据,对于数据质量要求十分严苛。
对于数据业务的基础支撑系统,除了能够满足高并发度和实时性以外,数据的质量,也即数据可靠性也是关键的一环。本文的研究目的在于基于Kafka的底层Api给出一种具有数据可靠性的数据消费者(Consumer)的设计方案。
1 技术背景简介
1.1 名词介绍
主题(topic)是Kafka用于区分所发布消息的类别或是名,即一个主题包含一类消息。
分区(partitions)是Kafka为于每一个主题维护了若干个队列,称为分区。
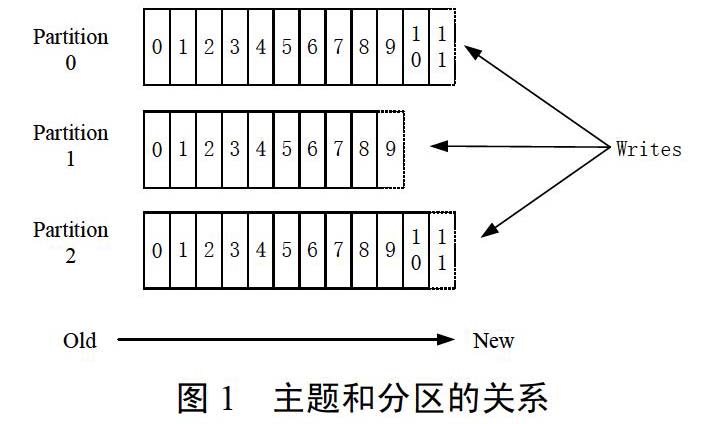
假设有一个拥有3个分区的主题,其中主题(topic)和分区关系如下图,
Kafka中每个主题的每一个分区是一个有序写入、不可变的消息序列,一个topic下可以拥有多个分区。
消息偏移量(offset)是Kafka赋予每个分区(partition)内的每条消息一个唯一的递增的序列号,称为消息偏移量(offset)。
生产者(producer)是根据对于主题的选择向Kafka的发布消息,即向broker push消息的一系列进程。生产者负责决定某一条消息该被被发往选定主题(topic)的哪一个分区(partition)。
消费者(consumer)是向主题注册,并且接收发布到这些主题的消息,即消费一类消息的进程或集群。
代理(broker)是组成Kafka集群的单元。Kafka以一个拥有一台或多台服务器的分布式集群形式运行着,每一台服务器称为broker。
副本(replications)即分区的备份,以便容错,分布在其他broker上,每个broker上只能有这个分区的0到1个副本,即最多只能有一个。
消费者群组(Consumer Group)是有若干个消费者组成的集体。每个Consumer属于一个特定的Consumer Group。Kafka采用将Consumer分组的方式实现一个主题(Topic)的消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)。
1.2 Kafka的基本架构
Kafka是一个分布式的消息订阅和发布的系统。消息的发布者称作producer,将消息的订阅者称consumer.将中间的存储阵列称作broker。
图2极为简要的描述了一个消息订阅和发布系统,所必须具备的角色和工作机制。生产者(producer)将数据生产出来,推送给代理者(broker)进行存储,消费者需要消费数据了,就从broker中拉取数据来,然后完成一系列对数据的处理。
图3展示了Kafka作为消息订阅和发布系统的典型系统架构模型。多个代理者(broker)协同合作,组成了Kafka集群。Kafka的集群架构采用p2p (peerto peer)模式。集群中没有主节点,所有节点都平等作为消息的处理节点。优点是没有单点问题,一部分节点宕机,服务仍能够正常,缺点是很难达成数据的一致性和多机备份,如果一部分节点宕机会导致数据的丢失。
Kafka为避免上述的问题采用主节点选举机制,利用zookeeper,对于每一个主题(topic)的分区(partitions),选出一个leader-broker(主节点),其余broker为followers(从节点),leader处理消息的写入和备份;当leader宕机,采用选举算法,从followers中选出新的leader,以保障服务的可用,同时保障了消息的备份和一致性。
生产者(producer)和消费者(consumer)部署在各个业务逻辑中被频繁的调用,三者通过zookeeper管理协调请求和转发。这样一个高性能的分布式消息发布与订阅系统就完成了。producer到broker的过程是push,也就是有数据就推送到broker,而consumer到broker的过程是pull,是通过consumer主动去拉取数据的,而不是broker把数据主动发送到consumer端的。
2 原生Kafka-Consumer的原理和缺陷
2.1 设计原理
图4就是Kafka原生的Consumer的架构的简要图示。zkConnector提供一些关于与zookeeper交互操作的API;FetchDataChunk只要是提供获取主题数据的API;ConsumerConnector即实现kakfa-Consumer的主体部分,即用户API的接口类,提供Consumer链接和主题(topic)数据访问的接口。
Kafka中的offset用于描述消息在一个分区中的位置偏移量,依从一个分区内的消息的达到顺序递增;同时,Kafka的Consumer利用消息的offset来记录在一个topic中每个分区中的消费的水位线。在kakfa-Consumer中, 对于offset的处理是在ConsumerConnect建立连接的同时,开启一个定时器,每隔一定时间(用户可配置),就将现在用户consumer的在每个分区的offset记录到zookeeper中;因此,每次consumer启动的时候都会先从zookeeper中读取记录其中的offset,作为这次消费的起始点。
以上,就是Kafka原生的Consumer的基本设计原理,下面我们阐述一下他的缺陷,以及会造成的问题。
2.2 非可靠性的缺陷
由上述kakfa-Consumer的设计原理,标记Consumer消费水位的offset的记录是跟用户对数据消费和处理是分离的。考虑如下场景,例如用户的Consumer程序由于种种原因(程序异常、主机宕机、JVM异常、错误操作等)异常退出,此时用户Consumer在异常退出前消费的数据,就很有可能恰好处于ConsumerConnect中记录offset的定时器的运行周期,使得退出是丢失的数据的offset被记录到了zookeepero这样,当应用重新启动,向zookeeper同步offset的时候,就会拿到错误的偏移量,导致数据的丢失,使得数据不可靠。
2.3 本文设计方案的创新性
本文由于生产业务对数据质量的需求,摒弃了Kafka提供的不可靠的High-Ievel接口集,而采用Kafka内部底层的low-level的接口集,即只使用Kakfa获取数据的接口,不使用原生的的对于offset的维护服务。本文的设计方案重新封装了kafka的消息结构,并且利用zookeeper自行构造了保存offset的结构和方式,定义了用户获取数据的接口以及用户提交offset的接口,使得用户的数据消费行为与offset提交的行为朕动起来,保障了数据的可靠性。具体方案的设计原理会在下面章节详细阐述。
3 可靠的Consumer设计
3.1 可靠性的定义和条件
3.1.1 Consumer可靠性和本文的选型
对于Consumer的读取数据的可靠性有如下三种可达标准:
l.At most once消息可能会丢,但绝不会重复传输
2.At least one消息绝不会丢,但可能会重复传输
3.Exactly once每条消息肯定会被传输一次且仅传输一次
对于Kafka的原生Consumer,实现的Consumer属于第一种可靠性。在Kafka中是通过对于offset的保持,来控制数据的消费位置,即数据消费水位线。在Kafka的原生Consumer对于数据消费和数据水位线(offset)的保持是分离的。即在系统出现异常退出的时候,如果Consumer已经将数据消费,但是并未提交offset,当系统恢复重启时,同步上次记录的水位线时,就回读取到较早提交的offset,就会造成数据的重复消费;如果Consumer还未来得及消费数据,但是offset已经提交,在下次系统恢复重启,就回读取到错误的水位线,导致一部分数据无法被消费而丢失。
这种模式下,即Consumer的数据消费与offset的不同步,造成系统故障后可能丢失数据也可能重复读取数据,这就对应于At most once的可靠性。
本文要是现实的就是第二种可靠性,即At leastonce。将Consumer的数据消费与offset的提交同步起来,即Consumer在读完消息先处理再commit。这种模式下,如果在处理完消息之后commit之前Consumer宕机了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经被处理过了。这就对应于At least once。
由上面的描述,我们看出这种Consumer读取的可靠性,有可能会导致读取后的数据有重复的情况,这种情况很好解决。由于,在很多使用场景下,消息都有一个主键,所以消息的处理往往具有幂等性,即多次处理这一条消息跟只处理一次是等效的,那就可以认为是Exactly once;如果数据中没有主键,我们也可以人为的在producer端对每一条数据加入一个唯一的ID作为主见,而后在Consumer后端的业务端进行去重,就能够实现Exactly once。
如果一定要做到Exactly once,就需要协调offset和实际操作的输出。经调研发现一般的做法有两个:
1、引入两阶段提交。由于,许多输出系统可能不支持两阶段提交,这种做法通用性很差,而且引入两阶段提交,这种类似同步的做法,会降低系统通用消息消费的性能,使吞吐大打折扣;
2、如果能让offset和操作输入存在同一个地方,会更简洁和通用。这种方式可能更好。比如,Consumer拿到数据后可能把数据放到HDFS,如果把最新的offset和数据一起写到HDFS,那就可以保证数据的输出和offset的更新要么都完成,要么都不完成,间接实现Exactly once。但是这种做法,也限制了Consumer端的输出形式,并将业务和接口耦合在一起,是系统具有很差的扩展性。
因此,综合考虑了系统的性能和可扩展性,以及通过后端数据再处理达到Exactly once可靠性的可实现性,本文选择了实现能够保障At least once可靠性的Consumer。
3.1.2 本文的可靠性设计的外部依赖条件
本文只设计并实现一个可靠的kakfa-consumer,只关注Consumer从broker拉取数据到处理完成数据输出到业务层这段的数据可靠性,这就需要一些外部条件的保障:
1、假设producer是可靠的,即不会丢失数据,能够建数据源的数据不丢失的推送到broker;
2、假设broker是可靠的,不会有丢失数据;不会有超过replication数目的broker不能够提供服务;
3、假设zookeeper是可靠的,能够保障服务的提供以及数据的一致性。
3.2 Zookeeper技术
Zookeeper分布式服务框架是Apache Hadoop的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。Zookeeper的典型的应用场景:配置文件的管理、集群管理、同步锁、Leader选举、队列管理等。
本文使用Zookeeper开源工具,保持offset数据,利用zookeeper的数据一致性的特性,来保障offset的数据可靠性。
3.3 设计详述
3.3.1 Consumer的模块设计
本文的Consumer设计如图5所示
ZKTools模块,主要负责与zookeeper相关的交互操作,提供与Zookeeper进行读写操作的相关操作的API;
ConsumerClient是主体模块,主要负责针对主体的每个分区的数据读取和可靠性维护的操作;
BatchMessage是对Kafka的原生的消息结构进行封装,加入了该消息的offset和读取该消息所在分区的ConsumerClient类的对象,为数据可靠性的实现提供支持,丰富了原生的Message结构的功能;
ClientEngine是整个kafka-consumer的对用户的接口模块;提供了设置c onsumer链接,获取数据读取入口的API。
3.3.2 Consumer的详细设计
图6是kafka-consuemr的详细设计的类图,具体阐述了每一个模块在代码层面完成的功能:
ZkTools是一个单件类,提供与zookeeper相关的操作:
_init_ (confMap):构造函数,参数是用户配置,配置主要包括zookeeper的ip和端口、要消费的主题名称、consumer的群组名称。构造函数完成,与zookeeper的链接、初始化一些类变量。
setData (zkPath,offset):设置zkPath指定的zookeeper中的文件的内容
getData (zkPath):获取zkPath指定的zookeeper中的文件内容
createPath (zkPath):创建zkPath指定的目录
checkExist (zkPath):判断zkPath是否存在
getPartitions (topic):获取主题的所有分区编号的列表。
BatchMessage是原生Message的扩展类,提供一些系列get和set方法,是用户完成消费动作的入口:
getThisOffset():获取该消息的起始offset
setThisOffset():设置该条消息的offset
setConsumerClient 0:设置ConsumerClient对象,当该条消息,被用户读取并执行完处理逻辑,可以利用该对象,调用fnish()方法,完成对该消息的消费,从而提交该消息的偏移位置,只是保障消息不丢失,达到可靠性重要的一环,即用户每当对一条消息完成用户逻辑的时候就调用frnish (),这样使得数据消费的偏移量和用户处理逻辑能够协同工作,保证数据的可靠性;
getsumerClient():获取ConsumerClinet对象
ConsumerClient是整个kafka-Consumer的核心,完成主要的功能,ConsumerClient类,是Runable类的实现类,实现run()方法,是一个线程类,每个线程针对主题的某一个分区进行处理:
_init_():构造函数,获取用户配置confMap、处理的分区编号partld_存放消息的共享队列bq。构造函数完成一系列的初始化工作:
1、与zookeeper建立连接
2、根据主题名称、和分区编号获取该主题的leader-broker的ip和port
3、根据主题名称、分区编号、groupld获取当前最新的消费offset作为起始offset
4、初始化各种数据结构
5、建立用于周期性提交offset的Timer
CommitOffset():是Timer定时器的定时调用函数,周期性向zookeeper提交offSet。
利用offset的存储结构和提交策略保障可靠性
在ConsumerClient类中有一个排序的数据结构,对象名称叫msgWait,是一个存放offset的有序列表。
另外,与msgWait,相关的是fnish()函数,功能为从msgWait中删除最小的的offset,而由于msgWait本身有序,即删除第一个元素。
run()方法根据初始化的leader-broker的ip和port,利用Kafak底层Api向broker拉取数据(Message),并将数据、当前ConsumerClient对象、该数据的起始offset,也即消费的curOffSet(当前offset)构造为BatchMessage对象,装填到共享消息队列bq里面;然后将curOffSet追加到msgWait中。
用户读取共享队列中消息并执行完处理逻辑,调用fnish()方法,将该消息的起始offset从msgWait中删除。
CommitOffset()方法,是从msgWait中取出最小的offset.并将其提交到zookeeper()。也即如果用户没有处理完该消息,就不会调用finish()方法,那么CommitOffset就一直在提交上一条已经消费完成的消息的偏移量;当用户消费完成后,调用了finish方法,将该条消息的起始位置的offset从msgWait中删除,那么msgWait中最小的offset就是该消息的偏移量位置,就会在下一个周期被提交。本文的方案就是利用一个offset有序的结构和finish的方法,将用户的处理逻辑和Consumer对于offset的提交,联系到了一起,确保只有当用户处理完成数据后,才会提交消息的offset,从而保障数据的可靠性。
getLeader():获取该分区的le ader-broker的的ip和port。
getLeaderAfterElection():前文提过, 当leader-broker异常时,kafka会采用某种选举方式,重新选举leader-broker,但是这个过程不是原子的,会产生获取数据失败的情况,该函数就是在获取数据失败的情况下,重新获取选举后的leader-broker。
getLastestOffset():获取该分区最新的offset。
ClientEngine是kafka-consumer提供给用户的入口类,主要完成ConsumerClient现成的启动,提供消费数据接口:
init():构造函数,获取用户配置、初始化共享消息队列bq、向zookeeper获取主题的分区编号的列表:
Start():根据分区列表,启动ConsumerClient线程
getConsumerlterator():返回共享消息队列的迭代器,作为用户消费数据的入口。
4 方案验证
4.1 测试环境
测试环境采用实验室的pc机进行测试。机器配置如表1所示,
测试主机有三台,组成kaika和zookeeper的测试集群,三台主机网络配置信息如下,
4.2 测试用例和结果
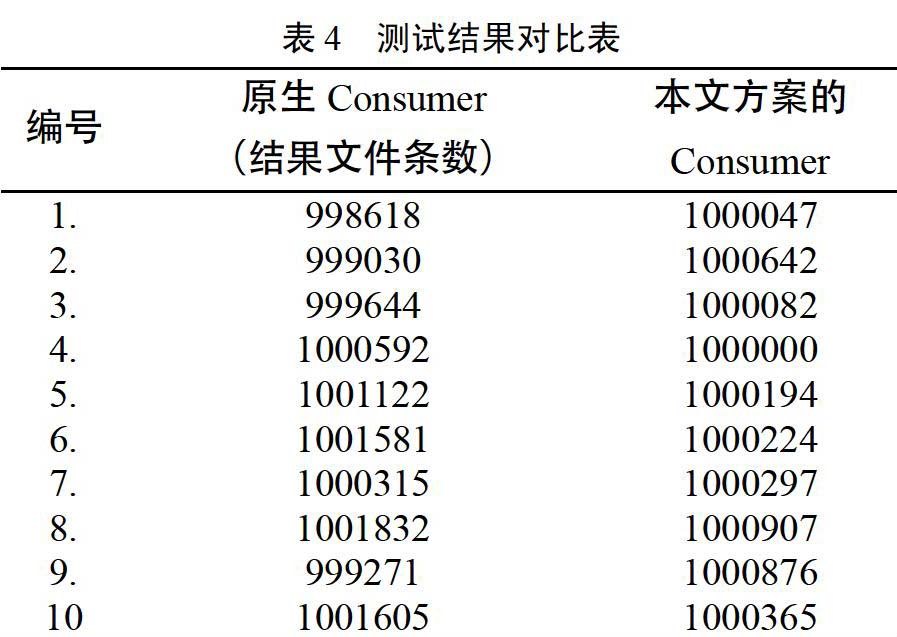
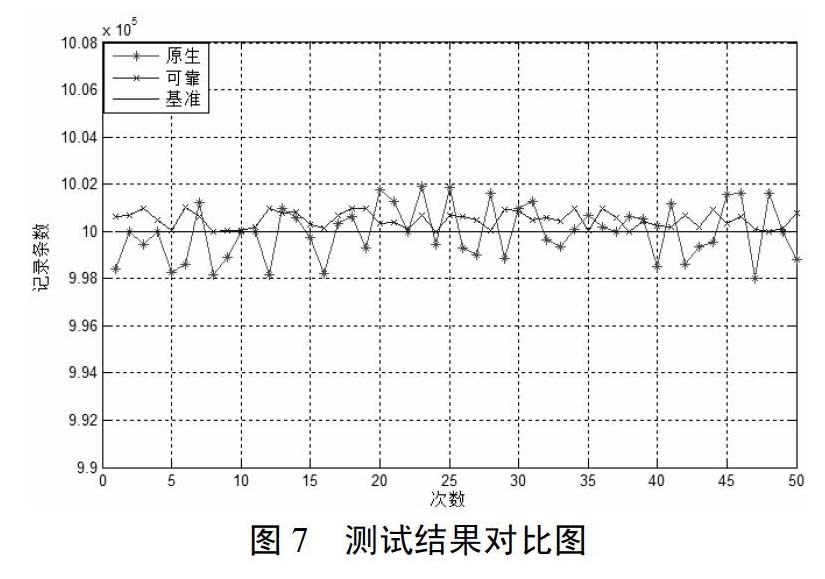
由于篇幅有限,上表实例性的展示了10次测试的对比结果,为了清晰的对比展现测试结果,见如下对比图,图7中,红线代表原生Consumer在测试用例下的结果数据,蓝线代表本文设计方案下的Consumer的结果数据,黑线代表着原始数据的记录条数。由图我们可以清楚的看出,原生Consumer无法保证数据的可靠性,时而多数据,时而缺失数据;而本文实现的可保证At least once可靠性的Consumer的线图一直在黑线之上,表明本文的设计方案下数据在系统意外宕机时不会缺失,能够保障At least once的可靠性,从而证明了本文设计方案的可行性和正确性。
5 结论
随着互联网的飞速发展,新的业务对数据处理的实时性、高并发、高吞吐的要求在不断的提高。然而,数据的可靠性也是十分重要的一环。本文基于Kafka分布式消息队列,提出了一种可靠的Consumer的设计方案,保障了数据的可靠性,能够在业务端保证数据幂等的条件下,达到数据不会丢失也不重复的效果。然而,本文实现的Consumer对于可靠性的保障是有局限性的、并且对于主题分区较多的情况效率也会下降。所以,笔者也会不断的学习,为了使用信息社会的瞬息万变,需要不断地变革和创新,才能为社会创造更好的互联网服务。
- 美声唱法对我国民族声乐的影响
- 试论唐代宫廷乐舞机构发展的历史成因
- 探析《春蚕》演奏艺术魅力及技巧创新
- 探析琵琶曲《十面埋伏》的艺术特色
- 中国小提琴作品创作问题思考
- 浅谈美声唱法技术在流行音乐中的巧妙应用
- 谈国产电影的第一次自救
- 论纪录片真实性、客观性的作用
- 关于诗意纪录片的探求
- 浅析电影《如父如子》中的父子之情
- 中国“硬科幻”中的文化价值观
- 媒介娱乐化视角下的广播电视方言节目研究
- 欧美游戏改编电影中的女性角色研究
- 浅论城市旅游形象宣传片创作和制片管理
- 格鲁克歌剧改革之《奥菲欧与优丽狄茜》
- 浅谈合唱指挥技术中的“省、准、美”
- 谈歌曲复调性织体写作的钢琴伴奏
- 浅析歌剧《原野》中咏叹调《啊,我的虎子哥》的演唱技巧及情感表达
- 二十世纪二三十年代中国艺术歌曲的当代阐释
- 二重唱《我的叹息将随风飘去》曲式结构分析
- 论河北民间音乐产业化发展的创新实践
- 汉代相和歌探究
- 浅析琵琶左手演奏技法在琵琶演奏中的运用
- 刘天华先生对近代琵琶艺术的贡献分析
- 论手风琴重奏教学中的“一致性”处理
- aspirin
- aspiring
- aspiringly
- aspiringness
- aspirin's
- aspirins
- aspish
- asps
- asp's
- as-regards
- as-rule
- ass
- as's
- assailant
- assailants
- assassin
- assassinate
- assassinated
- assassinates
- assassinating
- assassination
- assassinations
- assassinative
- assassinator
- assassinators
- 帝王的功绩和教化
- 帝王的历数,国运
- 帝王的后代
- 帝王的后裔
- 帝王的命令
- 帝王的命运
- 帝王的坐具
- 帝王的坐骑
- 帝王的坟墓、陵园
- 帝王的坟墓及墓地的宫殿建筑
- 帝王的基业
- 帝王的墓地
- 帝王的外戚
- 帝王的妃嫔
- 帝王的妾侍
- 帝王的威严
- 帝王的威仪
- 帝王的威力很大,足以制服山河
- 帝王的威势
- 帝王的子孙
- 帝王的宗室近亲
- 帝王的宗庙
- 帝王的宠爱关注
- 帝王的宫室
- 帝王的宫殿