郎叶楠++高跃明


摘要:随着国际反恐形式的不断严峻,通信社交圈的获取与分析逐渐成为预防恐怖行动的重要手段之一。为满足社会对通信社交圈进行分析的需求,本文利用分布式存储技术以及分布式运算技术,通过对电信信令数据的分析获取人员通信社交圈,社交圈中的信息可以帮助分析人员快速锁定目标、了解事件发生顺序。与此同时,本文合理利用了开源软件的特性,有效降低了系统的开发与维护成本,适合于大范围推广。本文给出了较为完整的社交圈分析系统的设计方案,并通过进一步实现证明了方案的可行性。
关键词:计算机应用技术;信令;社交圈分析;分布式
中图分类号:TN925+.3
文献标识码:A
DOI:10.3969/j.issn.1003-6970.2016.02.021
引言
在多种犯罪预防的手段中,通信社交圈的分析是重要手段之一,通过对指定人员通信行为的分析,分析人员可以达到以下目的:1.关键人员定位;2.协同人员挖掘;3.人员行为梳理(了解事件发生顺序)。反恐领域的特殊性导致了其对通信社交圈分析有诸多硬性需求。首先,用来分析的数据应当尽量全面;其次,分析速度要快;最后,对社交圈分析所需的软硬件需求应尽量低,从而适合大规模推广。
当前,我国的基层民警大多使用人工的方式进行社交圈分析,在进行分析之前需要从相关运营商调取人员通信记录,通过对记录的分析确定下一批待分析的人员名单,然后再次调取这些人的通信记录,周而复始。这种人工分析的方式速度缓慢,分析一个通信行为较活跃人员几小时的通信行为甚至需要一至两天的时间。同时,人工分析使得分析人员极易疏漏重要信息,使得分析结果的可靠度下降。虽然当前也存在一些自动化分析软件,但这些软件都无法很好的解决数据来源以及处理问题,这给用户的使用带来了不便。
为克服传统人工分析方式以及现有软件的不足,本文所设计的系统以a接口与Abis接口信令产生的话单数据作为分析基础,通过对话单数据的采集、预处理、存储以及分析来生成人员通信社交圈,有力地提高了分析的速度与准确度并很好地解决了数据的采集以及处理问题。
利用开源软件搭建云服务是现今系统架构的趋势,本系统采用HBase与HDFS等开源软件搭建了能够为用户提供在线社交圈分析的云服务系统。
1 功能分析
根据本人对目标用户需求的调研,分析人员在进行社交圈分析时存在以下使用场景:
(1)已明确目标群体(多于一人)并对群体内人员的信息有所了解,需要查看群体内人员在某一时间范围内的社交行为从而推测事件发生顺序。
(2)已有明确的目标(任意数量),但不清楚是否还有其他协同人员,故而需要对某一时间范围内目标人员的短信以及通话联系人进行分析;
针对上述场景,本系统为社交圈分析提供了两种使用模式:
(l)针对场景l,本系统提供组内分析模式。组内分析模式仅对指定的目标人员间的行为进行检索,生成的社交圈中仅包含指定的目标人员以及他们之间的联系,分析人员可通过查看社交圈来推断事件的发生顺序。
(2)针对场景2,本系统提供组外分析模式。组外分析模式可以对指定的人员进行全量的通信行为检索,生成的社交圈中包含分析人员指定的目标人员、目标人员的直接联系人以及上述所有人之间的联系,分析人员可通过查看社交圈来推断目标人员是否还有其他协同人员;
除以上两种可供选择的分析模式外,分析人员还可以在分析时指定是否只查看短信行为和是否只查看通话行为。
2 关键问题
2.1 数据存储空间
本系统需在海量数据存储的基础上才能运行,这就要求本系统能够存储足够大量的数据。以浙江某城市为例,该城市每天产生20G的数据,而一次社交圈分析至少需要使用30天的数据才能产生有意义的分析结果。
2.2 业务响应时间
本系统作为在线分析系统,响应时间的长短对用户体验有重要影响,响应时间越短,用户体验越好。本系统在响应时间上存在以下难点:
数据量大,数据检索时间长。本系统在进行分析之前需要对大量数据进行检索,如果没有有效的优化措施,分析业务将在数据检索环节耗费大量时间。
每次分析需要进行多次数据检索。由于本系统针对业务的特殊性,每次社交圈分析都需要对数据进行多次检索。从以上章节流程说明可见,除多起始点组内模式外,其他所有分析都要从起始点开始,通过起始点的检索才能确定下一次检索的条件,因此至少需要两次检索。在数据量本就很大的前提下,多次检索无疑会进一步增加数据检索阶段的耗时。
无法有效利用缓存机制来减少每次检索的耗时。在本业务中,不仅多个分析请求的起始点间没有关联,单个分析过程内的多个检索条件也没有明显关联,整个业务有明显的数据量大、数据复用率低的特点,因此缓存机制对检索速度的提升没有明显效果。
3 系统设计与实现
3.1 系统结构设计
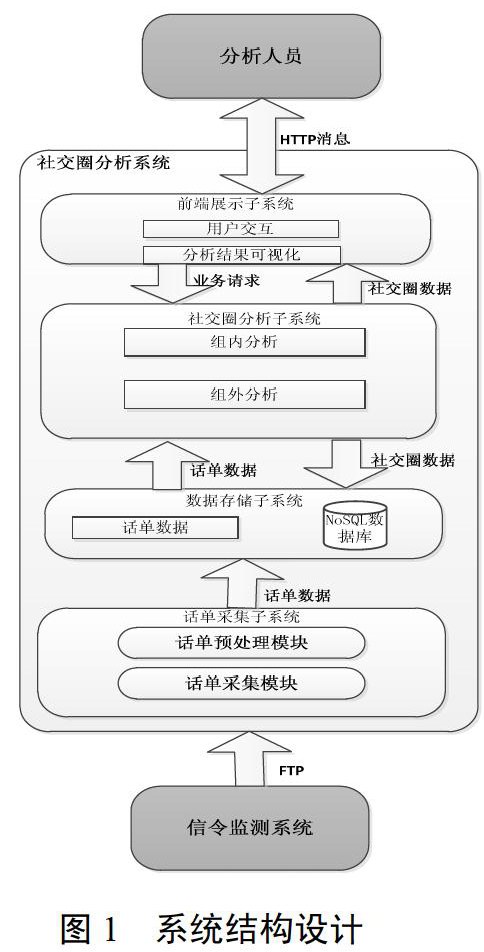
图1给出了系统静态结构设计,根据子系统功能的不同,系统可划分为话单采集子系统、数据存储子系统、社交圈分析子系统以及前端展示子系统以及管理平台。
其中,话单采集子系统负责接收信令监测系统发送来的话单数据并对话单数据进行预处理。数据存储子系统负责存储经过了预处理的话单。社交圈分析子系统负责社交圈分析的业务逻辑,根据用户的业务请求对数据存储子系统中的数据进行分析,分析结果交由前端展示子系统返回给用户。前端展示子系统是本系统与用户进行交互的接口,负责分析请求的接收、分析结果的展示等,前端展示子系统在收到社交圈分析子系统提供的分析结果后,会将经过了数据可视化处理的数据展现给用户。系统各部分具体功能如下:
(l)话单采集子系统
话单采集子系统是所有数据的入口,负责接收和预处理来自信令监测系统的话单数据。话单采集子系统内部分为话单预处理模块与话单采集模块,话单采集模块定期接收来自信令监测系统的话单数据,话单预处理模块对接收到的话单进行预处理,经过处理的数据交由数据存储子系统进行存储。
话单采集模块:话单采集模块负责定期接收来自信令监测系统的数据,二者使用FTP服务进行数据传输。话单采集模块对接收到的数据进行解压缩操作后交给话单预处理模块进行话单预处理。
话单预处理模块:话单预处理负责对接收到的话单文件进行预处理,包括无效话单过滤以及关键信息提取。由于采集来的话单可能以不同格式存在,话单预处理模块还具备对多格式的兼容功能,其接受指定格式的多种数据,输出统一格式的数据交由数据存储子系统进行存储。
(2)数据存储子系统
数据存储子系统是本社交圈分析系统的核心子系统之一,所有话单数据都存储在其中。话单数据因其数据量大、随机读取性能要求的特点而存储在HBase数据库中。
话单数据:话单数据是经过话单采集子系统预处理的数据,是本社交圈分析系统的核心数据,话单数据中包含主被叫号码,业务发生时间、时长以及业务相关数据。
(3)社交圈分析子系统
社交圈分析子系统是本社交圈分析系统的业务核心,负责对数据存储子系统中的数据进行分析,所有与业务相关的逻辑都由社交圈子系统完成。社交圈子系统在分析结束后,将完整的社交圈交给前端展示子系统。在与数据存储子系统的交互中,数据存储子系统只进行数据检索,数据的分析、汇总以及下一轮查询的查询条件都由社交圈分析子系统完成。
(4)前端展示子系统 前端展示子系统是本系统与最终用户的接口,所有与用户的交互都由本子系统完成。在交互部分,前端展示子系统的功能包括用户注册、用户登录、用户账号信息修改以及用户社交圈分析请求的收集,收集来的分析请求会交由社交圈分析子系统进行进一步处理。
3.2 数据存储子系统数据结构设计
由于话单数据的数据量大、分析业务对话单随机读取的性能要求高,故而本系统采用HBase存储话单数据。然而,HBase是列存储性Key-Value数据库,仅可对row key进行排序和索引(自动执行),有效话单无法直接存储到HBase中去。虽然HBase只有一种固定的索引,但这种索引在HBase的运行中十分高效,合理利用这一点可以在避开检索条件单一这项缺点的同时最大化HBase的随机读取性能,因此,row key的设计就成为了数据结构设计的重点。
一个好的row key设计应当能达到以下目的:
(l)分散数据,尽量避免访问热点的出现。HBase集群中的每台服务器节点都保存有一部分的数据,多节点同时进行数据检索时可以充分发挥系统性能,相反,若查询只集中在某几个节点上,则会严重降低系统性能,导致业务响应时间的提高。
(2)减少查询所需时间。可以通过两种途径达到减少查询时间的目的:减少查询次数与减少单次查询所需时间。
在对本系统的业务进行分析后可知,手机号码与业务开始时间必然JL}{现在检索条件之中,且对手机号码的检索分为两种情况:全量查询与指定查询。全量查询是指查询与指定单个号码相关的所有数据,发生在起始点查询阶段;指定查询是指查询两个号码间的通信数据,发生在直接联系人查询阶段。显然,指定查询可用全量查询实现,实现方式为对两个号码中的任意一个进行全量查询,再以另一个号码对查询结果进行过滤。鉴于过滤操作可以方便地通过HBase提供的filter实现,故而本系统便以全量查询的方式实现指定查询。
本系统中,row key由单个号码和该次通信的开始时间作为row key,二者以符号“l”分隔,其格式为
MDNlstart_time
在对话单数据进行存储时,每条话单中的主被叫分别作为MDN -次,生成两份话单数据,同时向数据中插入一个标示通信方向的属性,数据流程如图2,数据库中数据结构如表1。
流程说明:
(l)提取有效话单中的主叫号与开始时间,按照MDNlstart_time的格式组成row key,同时添加direction列以标示业务的通信方向,有效话单中的其他数据被放在各自的列中,数值不变。
(2)提取有效话单中的被叫号码与开始时间,按照MDNlstart_time的格式组成row key,同时添加direction列以标示业务的通信方向,有效话单中的其他数据被放在各自的列中,数值不变。
在进行数据查询,全量查询与指定查询两种查询方式需要使用不同的查询命令。
全量查询
全量查询使用scan操作对row key进行检索,在scan操作中指定row key的起始行与结束行。例如,查询号码13813800000在2015年10月1日0点0分至2015年10月10日10点10分间的通信数据,就可以使用如下命令在HBase中进行查询
Scan‘TABLENAME: {STARTROW=>13813800000120151001000000
, ENDROW=>13813800000120151010101011}
指定查询
指定查询同样使用scan操作,与全量查询不同的是,这类查询需要在参数中指定所使用的filter。例如,查询号码13813800000与13 813 811111在2015年10月1日0点0分至2015年10月10日10点10分间的通信数据,就可以使用如下命令在HBase中进行查询
Scan‘TABLENAME: {STARTROW=>13813800000120151001000000
, ENDROW=>13813800000120151010101011
,COLUMNS=>data
, FILTER=>”SingleColumnValueFilter(‘data,opnt,=,‘13813811111)”}
由于社交圈分析业务的特殊性,每次检索的号码都可认为是随机的,因此以MDN作为row key的起始可以有效分散数据,避免热点的出现。同时,这种row key设计最大化利用了HBase对row key的排序机制,极大优化了单次查询的效率。
3.3 话单采集子系统实现
Python语言能够很容易地实现对文本以及文件系统的操作,在字符串格式化、移动文件以及删除文件上具有很强的能力,同时,Python还拥有众多第三方库供调用,可以实现FTP操作、解压缩操作以及对HDFS的操作等,本系统使用Python语言实现话单采集子系统。
话单采集子系统以FTP客户端的方式从信令监测系统获取原始信令,为避免数据的重复下载和遗漏,约定信令监测系统将话单数据以统一的命名方式存储在固定的目录下,话单采集子系统中以话单类型、地理位置以及时间的格式保存下载记录,通过比较信令采集系统中的文件名与下载记录来判断是否有新的数据需要下载。话单文件下载后,通过逐行读取文件并将有效数据写入新文件的方式生成系统使用的话单文件,话单文件写入完成后即调用HBase的批量导入功能将数据写入HBase数据库。
3.4 社交圈分析子系统实现
社交圈分析子系统由Java实现,其运行流程如下:
(1)接收社交圈分析请求,根据请求中的内容确定第一次查询所需的查询条件。;
(2)进行第一次查询,若为组内分析模式,则直接跳至步骤4;若为组外分析模式,则将其中所有人员列为待查人员;
(3)依次对所有待查人员进行数据查询,查询条件与步骤1类似;
(4)汇总所有数据,提取数据中的人员关系生成社交圈,社交圈以二维数据的形式表达,其中包含人员间的联系、联系类型以及联系次数;
(5)将生成的社交圈输出至至前端展示子系统。
4 结论
本文给出了较完整的系统实现,通过对分布式技术的合理利用,以低成本解决了海量数据的存储与分析问题,同时,对第三方信令监测平台的合理利用解决了同类社交圈分析产品数据获取困难的问题。
- 读懂“索要带孙费”背后的社会问题
- 炒饭的底线是“饭”
- 中国远征军347具阵亡将士遗骸回归祖国
- 陕西举办纪念红军长征到达陕北八十周年图片故事展览
- 陕西开启“握手五洲”新时代
- 坚定信心,迎难而上,不断扩销增效
- “全面加强党风廉政建设”理论研讨会在西安召开
- “华山论剑·锵锵丝路行”丝路行者文化论坛举行
- 百灵庙不能遗忘的抗战记忆
- “陕西微博达人在线”9月优秀微博
- 华阴市贫困大学生资助快讯
- 华阴市农综办“一把手”认真讲好“三严三实”党课
- 陕西旬阳:创新管护机制管好安全水
- 群众满意才“销号”
- 喀什的土陶世家
- 塔克拉玛干的睡胡杨
- 于敏石破天惊是此生
- 百年油田的延长之路
- 再造百年延长
- 污染地图背后的生态难题
- 延长“铁人”张林森
- 陈振夏中共石油战线首任厂长
- 延一井中国陆上石油第一井
- 延长石油传奇
- “十三五”规划的十三个新亮点
- praisers
- praises
- praiseworthily
- praiseworthiness
- praiseworthinesses
- praiseworthy
- praise²
- praise¹
- praising
- pram
- prams'
- prams
- prance
- pranced
- prancers
- prances
- prancing
- prank
- pranked
- prankful
- pranking
- pranks'
- pranks
- pranksome
- prankster
- 愚兄
- 愚公
- 愚公之谷
- 愚公有志
- 愚公的住处
- 愚公的房子——开门见山
- 愚公移山
- 愚公移山精神
- 愚公谷
- 愚冗
- 愚冥
- 愚凡
- 愚劣
- 愚勇
- 愚卤
- 愚叟移
- 愚叟移山
- 愚味地行动
- 愚味无知
- 愚园(園)路
- 愚士
- 愚士系俗
- 愚夫
- 愚夫俗子
- 愚夫妇