常昊 杨盛泉


摘要: 大数据时代的到来,生活种每天都产生着大量的数据,对这些数据进行分析并推荐商品在电商领域就会显得尤为的重要。协同过滤算法是目前发展比较成熟的,在各领域都取得了非常好的效果。但传统的协同过滤算法在计算相似度和预测评分时太过粗糙,并且效率很低。我们将协同过滤算法与决策树算法相结合,并对算法进行改进,创建一种协同过滤决策树算法来对商品进行推荐,并将新的协同过滤决策树算法运行在Hadoop平台上。Hadoop是一种分布式的处理大规模数据的云计算平台。实验证明,改进后算法使得推荐的准确率有了显著的提升。
Abstract: With the advent of the era of big data, daily life is generating a large amount of data. Analyzing and recommending these data will be particularly important in the field of e-commerce. Collaborative filtering algorithms are currently relatively mature and have achieved very good results in various fields. However, the traditional collaborative filtering algorithm is too rough and inefficient in calculating similarity and prediction score. We combine the collaborative filtering algorithm with the decision tree algorithm and improve the algorithm to create a collaborative filtering decision tree algorithm to recommend products and run the new collaborative filtering decision tree algorithm on the Hadoop platform. Hadoop is a distributed cloud computing platform for processing large-scale data. Experiments have shown that the improved algorithm has significantly improved the accuracy of recommendation.
关键词:大数据;推荐算法;协同过滤;Hadoop
Key words: big data;recommendation algorithm;collaborative filtering;Hadoop
中图分类号:TP311.5? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文献标识码:A? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文章编号:1006-4311(2020)09-0127-03
0? 引言
随着科技的发展,互联网技术也随之迅速发展和普及,这就使得网络上的数据每天高速增长,丰富用户生活消费的同时,大量信息资源膨胀迅速的问题也随之出现,“信息过载”也是目前互联网正面对的难题。“信息过载”指的是用户难以从海量数据中准确并且迅速地定位到自己所需要的信息。推荐系统的出现大大地缓解了“信息过载”这一难题。推荐系统根据用户的历史行为,预测并且推荐使用户满意的物品,实现个性化的服务。推荐系统是自动智能的为用户推荐物品,而且还会根据用户行为的变化,动态的调整推荐的物品类型,真正意义上避免了“信息过载”的困扰。
推荐算法是推荐系统的核心,本文主要研究了在Hadoop平台下的推荐算法,该推荐算法将决策树和协同过滤算法相结合,并对传统的协同过滤算法进行改进,来克服传统算法可扩展性差、新用户和新项目冷启动等缺点,提高推荐的时效性[1]。
1? 传统的协同过滤算法简介
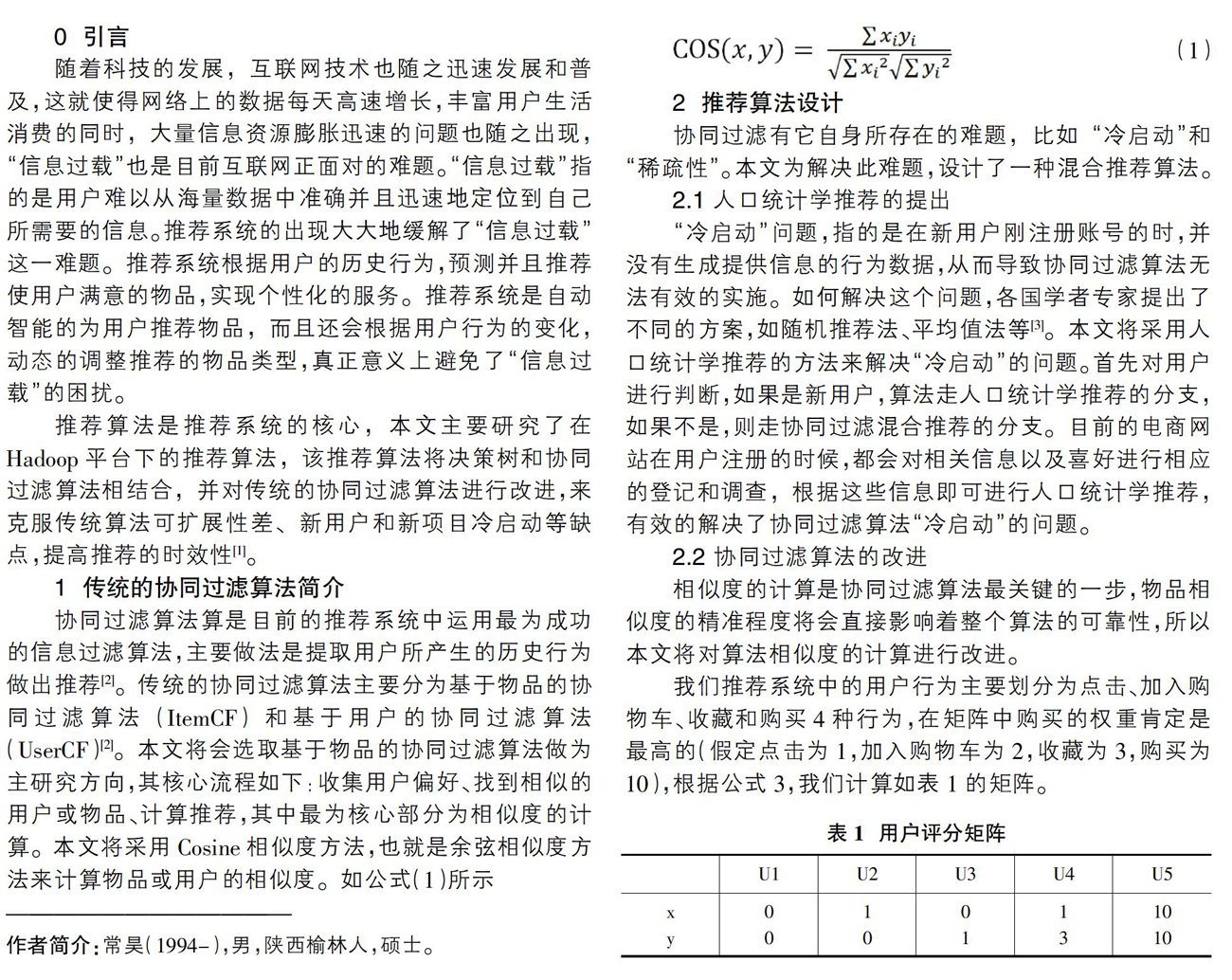
协同过滤算法算是目前的推荐系统中运用最为成功的信息过滤算法,主要做法是提取用户所产生的历史行为做出推荐[2]。传统的协同过滤算法主要分为基于物品的协同过滤算法(ItemCF)和基于用户的协同过滤算法(UserCF)[2]。本文将会选取基于物品的協同过滤算法做为主研究方向,其核心流程如下:收集用户偏好、找到相似的用户或物品、计算推荐,其中最为核心部分为相似度的计算。本文将采用Cosine相似度方法,也就是余弦相似度方法来计算物品或用户的相似度。如公式(1)所示
(1)
2? 推荐算法设计
协同过滤有它自身所存在的难题,比如“冷启动”和“稀疏性”。本文为解决此难题,设计了一种混合推荐算法。
2.1 人口统计学推荐的提出
“冷启动”问题,指的是在新用户刚注册账号的时,并没有生成提供信息的行为数据,从而导致协同过滤算法无法有效的实施。如何解决这个问题,各国学者专家提出了不同的方案,如随机推荐法、平均值法等[3]。本文将采用人口统计学推荐的方法来解决“冷启动”的问题。首先对用户进行判断,如果是新用户,算法走人口统计学推荐的分支,如果不是,则走协同过滤混合推荐的分支。目前的电商网站在用户注册的时候,都会对相关信息以及喜好进行相应的登记和调查,根据这些信息即可进行人口统计学推荐,有效的解决了协同过滤算法“冷启动”的问题。
2.2 协同过滤算法的改进
相似度的计算是协同过滤算法最关键的一步,物品相似度的精准程度将会直接影响着整个算法的可靠性,所以本文将对算法相似度的计算进行改进。
我们推荐系统中的用户行为主要划分为点击、加入购物车、收藏和购买4种行为,在矩阵中购买的权重肯定是最高的(假定点击为1,加入购物车为2,收藏为3,购买为10),根据公式3,我们计算如表1的矩阵。
其中纵坐标代表商品的编号,横坐标代表每个用户行为的权重值。将此代入协同过滤算法的余弦相似度公式中,可得物品x和物品y的相似度很接近于1,但如果用户U5对x物品很满意,对y物品却给了差评,两者对商品的喜爱程度与相似度完全不符,所以我们对公式进行了如下改造,将购买用户对商品的评分结合余弦相似度中,得出如公式(2):
(2)
算法中的a(x)和a(y)分别代表着用户对物品x和y的评分,这个公式计算方式如图1所示。
其中avgall指的是整个电商网站所有用户的所有评分,avgu指的是用户u的平均评分,ux指的是用户u对商品x的评分。
在物品自身的特征中,关键的一个信息即物品面世的时间。如两个物品面世的时间越近,其基于时间的相似性就越大,可知物品之间的相似度和物品面世的时间成反比,如果将其相似度放在[0,1]区间的话,其公式如公式(3)所示:
(3)
其中t1和t2表示物品x和y面世的时间,ρ为归一化系数。
根据研究和分析可知,可以从两个方面得到物品的相似度,然后对此取平均值得到物品最终的相似度(即公式2和公式3求平均),如公式(4)所示。
(4)
2.3 决策树的加权
通过数据集,可以分析得出不同性别用户的偏好,如果不把这些主观因素考虑进去,推荐的物品准确率就会受到一定的影响。为此,我们将用户注册时的信息(年龄、兴趣等)当做决策树的特征值,并计算每个特征值所对应的熵值,建立两个关于性别的决策树模型,即男性决策树和女性决策树。并将协同过滤推荐的物品,带入决策树,得到其每个物品对应的权值,进行计算后,重新进行排序,进行推荐。则算法最终的流程图如图2所示。
3? 实验结果
实验运行环境是Hadoop集群。该集群拥有1个Master节点和3个Slave节点,集群中所有的机器的配置完全相同。集群安装配置在CentOS-6.7操作系统下。实验的测试主要从准确率召回率两个方面入手。
①准确率。
算法的准确率测试的是推荐列表中用户所占物品,用户实际喜欢物品的比例,其推荐率可描述为公式(5):
(5)
其中Lu为用户U喜欢的物品,Bu是推荐算法为用户推荐的商品列表。测试样本从真实样本中进行抽取,分别选用排序top1、top5、top10进行测试,测试结果如表2所示。
在准确率的测试中,可直观的看出本文提出的算法比传统的基于物品的协同过滤算法的准确率更高,效果更明显。
②召回率。
召回率指在推荐列表中,有多少物品是用户喜欢的,其召回率可描述为公式(6):
(6)
其中Lu为用户U喜欢的物品,Bu是推荐算法为用户推荐的商品列表。同样选择返回结果的top1、top5和top10来进行对比测试。测试结果如表3所示。
由表可知,算法随着测试集返回结果的增加而增加,也可知本文设计的算法在召回率方面也是领先于传统的基于物品的协同过滤算法,在top10中体现最为明显,超出传统协同过滤12%。
4? 结论
本文设计的推荐算法模型在计算物品相似度之前采用了判断语句,有效的解决了系统的冷启动问题,提升了算法的可行性。在计算物品相似度時增加了物品面世时间的条件,并且在传统的余弦相似度算法上做出了进一步的改进,使得算法的准确率得到了有效的提升。最后通过数据集验证了改进后算法的在整体上都优于传统的协同过滤算法,并在Hadoop分布式系统中运行,充分发挥了在大数据环境下,Hadoop分布式系统计算数据的优势。
参考文献:
[1]冀晓岩.基于Hadoop的电子商务个性化推荐研究与实现[D].兰州交通大学,2017.
[2]刘畅,吴清烈.基于协同过滤的大规模定制个性化推荐方法[J].工业工程,2014,17(04):24-28,34.
[3]张磊.基于遗忘曲线的协同过滤研究[J].电脑知识与技术,2014,10(12):2757-2762.
作者简介:常昊(1994-),男,陕西榆林人,硕士。
- 行业传媒集团的媒体融合探索
- 坚守与奋进:全媒体时代编辑工作的“不变与求变”
- 如何快速提高编辑的独立策划能力
- 集聚,让数字出版飞起来
- 十年磨一剑 张江基地的创新驱动与融合发展
- 深化基地带动战略 促进产业健康发展
- 深化基地带动战略:集聚与引领
- 资讯
- 保留童真的活力和梦想
- 《韬奋精神六讲》(连载十)
- 从经典再造到返本开新
- 《尤莉亚的日记》:开启“安徒生奖”阅读新时代的金钥匙
- 大数据视角下网络新媒体内容价值链构建策略研究
- 打造学术精品服务科技发展
- 科技专著出版工作的影响因素研究
- 数字出版与知识产权协同保护研究
- 关于建立编校互动制度的思考
- 欧美教育出版商在华经营现状和趋势分析
- 从2017数字图书世界大会看美国数字图书出版现状和趋势
- Newsela:探索自适应学习之路
- 六问数字出版
- 非洲图书出版的现状、问题与应对策略
- “90后动漫价值观”的调研与启示
- 图书稿件中几类常见差错
- 民营书业的文化创新
- negatively
- negativenesses
- negatives
- negative territory
- negativeterritory
- negative²
- negative¹
- negativing
- negativities
- negators
- neglect
- neglected
- neglectedly
- neglectedness
- neglectednesses
- neglecter, neglector
- neglecters
- neglectful
- neglectfully
- neglectfulness
- neglectfulnesses
- neglecting
- neglectingly
- neglectors
- neglects
- 天龙八部
- 天龙表
- 天,大自然
- 太
- 太一
- 太一余粮
- 太一真人图
- 太一莲舟
- 太上
- 太上忘情
- 太上忘情太上无情
- 太上感应篇
- 太上有立德,其次有立功,其次有立言
- 太上皇
- 太上老君
- 太上老君叫蛇咬——法尽了
- 太上老君开处方
- 太上老君开处方——灵丹妙药
- 太不
- 太不像画
- 太不像画(话)
- 太不灵
- 太不过瘾
- 太不量力
- 太丘