朱颢东 李雯琦
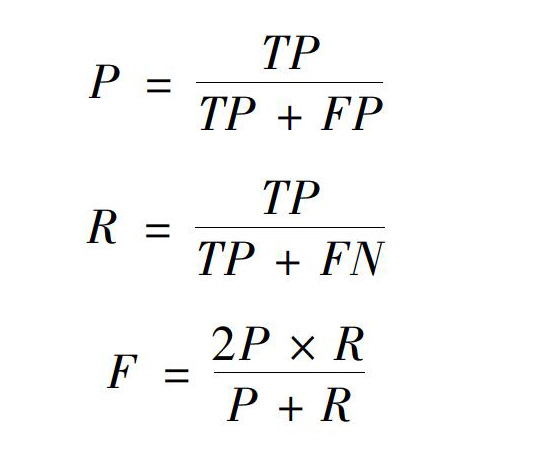

关键词:微博情感;表情符;情感词;语义规则
摘要:针对目前中文微博情感分析方法考虑因素不全面,从而导致情感分析结果欠佳的问题,提出一种基于语义规则和表情加权的中文微博情感分析方法.该方法在使用传统情感词典分析中文微博情感倾向的基础上,在普通情感词典中融入否定词、程度副词和网络新词,根据中文微博文本独有的语言特点和句式特点,采用从词语到分句再到复句的方式对整个中文微博进行情感分析,进而使用表情加权和语义规则进行权值求和,以确定情感倾向.实验结果表明,较另外3种中文微博情感分析方法,该方法效果更显著,其平均准确率为78.4%,平均查全率为75.2%,平均F值为76.7%.
Abstract:Aiming at the problem that the current Chinese micro-blog emotional analysis methods were not comprehensive, which led to poor sentiment analysis results, a Chinese micro-blog emotional analysis method based on semantic rules and expression weighting was proposed.On the basis of using traditional emotion dictionary to analyze the emotion tendency of Chinese micro-blog, negative words, degree adverbs and network neologisms were incorporated into the general emotion dictionary.According to the unique language characteristics and sentence pattern characteristics of Chinese micro-blog text, the method of emotional analysis from words to clauses and then to complex sentences was adopted to analyze the whole Chinese micro-blog.Expression weighting and semantic rules were used to perform weight summation to determine emotional tendency.The experimental results showed that compared with the other three Chinese micro-blog emotional analysis methods,the proposed method was more effective.It had an average precision rate of 78.4%, an average recall rate of 75.2%, and an average F value of 76.7%.
0 引言
伴随着互联网和社交媒体的不断发展及广泛应用,其所承载和产生的数据信息迅速增长.微博中承载着海量有价值的信息,如何对其进行合理的分析和利用,受到了国内外学者的广泛关注.用户通过微博平台可以随时随地获取信息、表达情感,海量的微博信息包含着用户对事件、产品、政策等的态度、意见和评价,对这些信息进行情感趋向分析,能够很好地挖掘网络群体的行为规律,获得潜在信息.因而,如何快速准确地分析微博情感倾向是当前研究的热点之一.
当前微博情感分析的主流方法为基于语义的分析方法,该方法通过情感词典统计出微博文本中情感词的情感权值,对其进行相关运算,计算出整个语句或文本的情感值,由此判断微博的情感倾向.
国外的网络社交媒体文本情感分析研究主要针对Twitter数据.Y.Yu[1]提出了针对Twitter的情感分析方法,将从Twitter中提取的词语与情感词典中被标注为正向或负向的情感词语进行比较,而后计算出文本的情感值.A.Pak等[2]在标注Twitter文本情感极性数据集的基础上,设计实现了基于朴素贝叶斯算法、支持向量机和条件随机场的情感分类器.E.Riloff等[3]利用人工定制模板,选取种子情感词语,运用迭代法获取了名词词性的情感词语,以此对微博进行情感倾向分析.
由于国内外语言结构和表达方式不同,中文微博的情感分析比英文微博的情感分析要复杂得多.国内的网络社交媒体文本情感分析研究主要针对新浪微博数据展开.朱嫣岚等[4]基于HowNet中情感词汇的情感信息,通过语义相似度和语义相关场来计算词语情感倾向,以提高情感分析的准确率.谭皓等[5]引进表情符和注意力机制,将表情符和词语同时训练,使用表情加权与普通情感词相结合的方式进行情感分类.李继东[6]结合普通情感词典和语义规则计算感情值,对中文微博进行情感分析.王文等[7]基于普通情感词典计算语义相似度,考虑正面情感增强因素,综合表情和语义规则获得情感倾向结果.刘志明等[8]通过对比3种机器学习算法、3种特征权重计算方法和3种特征选择算法后发现,使用支持向量机、词频-逆文本频率(TF-IDF)和信息增益(IG)選择特征项权重时,情感倾向分析效果最佳.但是上述研究对于影响中文微博情感倾向分析结果的因素考虑不够全面,导致情感倾向分析结果欠佳.
鉴于此,本文拟提出一种基于语义规则和表情加权的中文微博情感分析方法,根据中文微博特有的语言特点,在情感词典的基础上,融入语义规则和表情符号,计算文本情感值以确定微博情感倾向,以期有效改善中文微博情感分析结果.
1 中文微博情感分析方法与流程
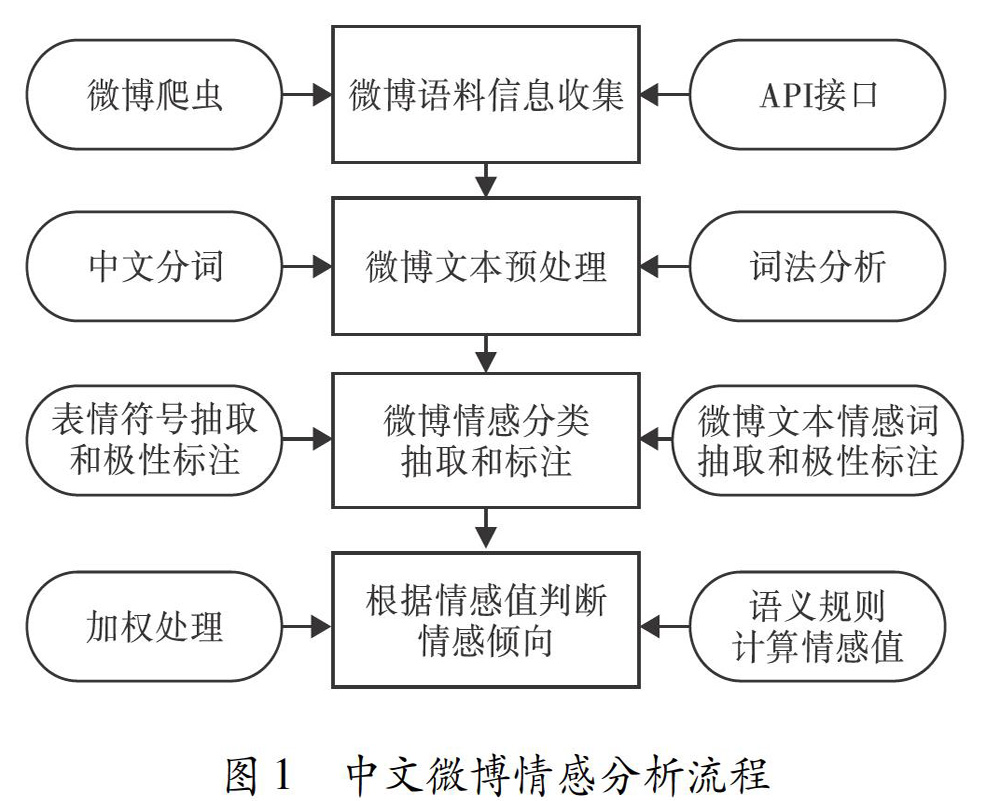
中文微博情感分析方法的流程一般分为以下4个步骤:
1)通过微博爬虫和API接口获取微博语料信息;
2)对获取的微博数据进行预处理,通过中文分词将微博文本中的句子划分为词语,并进行词性标注;
3)对微博文本情感词和常用的表情符号进行抽取和极性标注;
4)借助情感词典和语义规则计算情感值,对其进行加权处理,根据最终情感值将微博文本划分为正向、中性和负向3类.
中文微博情感分析流程如图1所示.
1.1 中文微博语料的收集和文本预处理
中文微博数据的获取方法主要有两种:一种是通过爬虫获取微博数据,将解析到的数据流内容转换成文本存入数据库,该方法可以收集大量的微博数据,但受限于访问速度,且需要下载大量的页面,因而效率不高;另一种是利用微博官方API获取数据[9],但如果仅使用API接口,所采集到的数据范围不够广泛,并且微博API开放接口会限制每段时间的请求次数,而过度或者恶意调用又会对微博平台性能产生不良影响.
因此,本文使用爬虫与API接口相结合的方式来获取微博数据,而后对其进行预处理.对没有价值的信息进行降噪处理,如删除微博中的广告、具有转发性质的微博、只含有表情符号的微博等.本文运用当前使用频率较高、性能较稳定、准确率较高的jieba组件(Python版)对获取的微博文本进行分词处理,并分析词法,标注词性.
1.2 微博文本表情符号标注
表情符号直接影响着微博这种短文本的最终情感分析结果.中文微博中常常存在大量的表情符号,其中使用最为广泛的就是微博中的默認表情符和输入法中自带的emoji表情符[10].这些表情符大多具有明显的情感倾向,在输入表情符号时,会出现相对应的标注,可以利用它们进行明确的情感倾向划分.
对于表情符号的情感分析研究主要有3种方式:将文本中表情符的情感极性直接作为句子的情感极性,忽略文本信息对情感极性的影响;将表情符和情感词视为相同级别的元素,赋予相同的权值进行情感极性计算;将表情符和文本视为相同级别的元素,但使用不同的权值对微博情感极性进行计算[11].本文选择第3种方式对微博的情感值进行计算.通过人工方式选择微博常用的表情符号,删除其中不具有情感倾向的表情符号.常用表情符情感倾向标注如表1所示.
除了对表情符号进行情感极性标注,本文对表情符号的情感强度也进行了相应的标注.利用王文等[7]对正向和负向表情情感权值的定义,正向表情情感权值在(0,1]区间内取值,负向表情情感权值在[-1,0)内取值,部分表情符号及其权值如表2所示.
1.3 微博文本情感词的抽取和标注
微博文本情感词的抽取和标注离不开情感词典.在情感分析领域,目前使用较为广泛的情感词典有知网的HowNet情感词典、大连理工大学词汇本体库和台湾大学的中文情感词典[12].
三者各有优缺点,HowNet情感词典和中文情感词典对正向和负向情感词进行了细致的划分,但未标注情感词词性及其情感权值,而词汇本体库虽然不如HowNet情感词典词汇丰富,却对词性和情感权值都进行了标注.因此,本文将融合HowNet情感词典和词汇本体库来确定情感词的极性及其情感权值,并在此基础上,针对微博文本特点,加入否定词词库、网络新词词库和程度副词词库,以提高情感分析的准确性.
在对网络新词进行词性标注时,引入PMI算法,通过计算基准词与网络新词之间的相似度来判断其情感极性,具体公式为若SO-PMI(word1)>0,则网络新词word1为正向情感词汇,否则为负向情感词汇.
在对微博进行情感分析时,应充分考虑到微博文本中程度副词和否定词对情感极性判定的影响.程度副词会加重或减轻微博情感倾向的程度,根据蔺璜等[13]对程度副词的特点、范围和分类的研究,将程度副词分为4个级别,即极度、高度、中度和微度,如果某个情感词语前出现多个程度副词,只对其前面出现的3个以内程度副词进行权值求积,超出3个的程度副词按无效词处理.否定词在情感分析中的作用更是不容小觑,若一个分句中存在两个否定词,双重否定则表示为否定之否定即肯定.因此,本文将否定词的权值设置为负值,用累乘的方式来计算其情感权值[14].部分网络新词、程度副词和否定词示例见表3—表5.
1.4 语义规则
中文的微博情感分析不同于英文微博,不仅要考虑情感词(表情符、否定词、网络新词和程度副词)的权值,还要考虑语义规则对整体情感分析的影响[15].本文的语义规则主要包括句型关系语义规则和句间关系语义规则.
1.4.1 句型关系语义规则
在进行情感分析时,先根据标点符号将复句分割成若干个小的分句,再对每个分句进行分析.用户在发布微博时,常用的句型主要有陈述句、问句和感叹句.陈述句对整体的情感影响不大;问句又分为反问句和疑问句,反问句会使整个句子的情感倾向从正向变为负向或者从负向变为正向,疑问句通常只是传递疑惑的态度,句子本身无情感变化;感叹句具有加强情感倾向的作用[16].如果用si来表示整个句子的影响权值,那么这3种句型的影响权值如下:陈述句si=1;疑问句si=0,反问句si=-1.5;赵天奇等[17]研究发现,当感叹句si=2时合格率最大,本文根据目前中文微博的语言习惯,对其研究成果进行改进,如果感叹句的尾部只有1个或2个感叹号,则si=2,如果有3个或3个以上感叹号,则si=3.
1.4.2 句间关系语义规则
除句型关系外,句间关系也会对情感分析产生重要的影响.在中文的日常表达中,复句存在众多句间关系,如并列关系、递进关系、选择关系、转折关系、假设关系、条件关系、因果关系等,本文仅对中文微博中出现频率较高的转折、递进和假设3种句间关系进行权值分析.通常使用集合{C1,C2,…,Ci,Cj…,Cn}来表示整个复句,其中Ci用于表示复句中的分句,S(Ci)用于表示影响权值.
1) 转折关系影响权值:对于存在转折词“但是”“然而”“却”的句型,其情感表达的重点在后半句,因此其S(Ci)=0,S(Cj)=1;对于只有一个转折前接词(如“尽管……”)的句型,其情感表达的重点在含有转折词的分句中,因此其S(Ci)=1,S(Cj)=0.
2) 递进关系影响权值:递进关系常用的关联词有“不但……而且”“甚至”“更”等,带有关联词的句子所表达的情感更加强烈,所以其S(Ci)=1,S(Cj)=1.5.
3) 假设关系影响权值:如果是形如“如果……那么”的肯定句型时,前面分句的情感倾向更强一些,则S(Ci)=1,S(Cj)=0.5;如果是形如“如果不……就”的否定形式时,因为有否定词,则S(Ci)=-1,S(Cj)=-0.5.
1.5 本文方法流程
根据上述分析,在对中文微博文本进行情感分析时,首先应对整个中文微博文本进行词语划分,统计情感词,然后对网络新词、程度副词和否定词进行权值分析,将这些权值进行累乘计算,再融入表情符号和语义规则进行权值求和,以确定其情感倾向.本文提出的中文微博情感分析方法流程如图2所示.
其中,adv表示用于修饰情感词的情感副词权值,Neg表示否定词权值,new表示网络新词权值,sen表示情感词在情感词典中的情感权值.
整个句子的情感值需要考虑到语义规则对情感倾向的影响,首先是对于分句而言的句型关系,根据上文对句型关系的分析,以E(ti)来表示融入句型关系的分句情感权值,其计算公式为
转折、递进和假设关系在复句中对情感分析有着重要的影响,对其情感权值进行求值时,要先对各个分句的情感权值进行求和,再乘以句型关系权值,以最终确定复句的情感权值,其计算公式為
其中,E>0.1表示微博情感倾向为正向,值越大则正向情感越强烈;E∈[-0.1,1]表示微博情感倾向为中性情感;E<-0.1表示微博情感倾向为负向,值越小则负向情感越强烈.
2 实验结果与分析
2.1 实验数据与评价指标
为验证本文提出的情感分析方法的有效性,将其与文献[5-7]的3种方法进行对比实验.采用将网络爬虫与API接口相结合的方式从新浪微博中获取8000条微博数据,剔除无效数据,经过筛选,有效微博为6834条,通过人工的方式将这6834条微博进行情感标注后得到具有正向情感倾向的微博1358条,具有中性情感倾向的微博2349条,具有负向情感倾向的微博3127条.
在信息检索、模式识别等领域,准确率(P)和查全率(R)是最基本的评价指标,可以从不同侧面对结果进行质量评估,而F值是综合这两项指标的评估指标,用于综合反映实验结果的整体质量.在对微博情感进行分析时,选择这3项指标作为判别分析结果的标准,其计算公式分别为
P=TPTP+FP
R=TPTP+FN
F=2P×RP+R
其中,TP表示微博情感分析中正确分类的微博文本数量,FP表示检索到但分类错误的微博文本数量,FN表示未检索到但属于此类别的微博文本数量.本文使用Matlab分析计算结果.
2.2 结果与分析
4种情感倾向分析方法对6834条有效微博数据的测试结果如图3—图5所示.
由图3可知,文献[7]方法对中文微博分析平均准确率高于文献[5]方法和文献[6]方法,说明在中文微博情感倾向分析中,表情加权和语义规则对情感分析具有一定的积极作用.本文方法针对中文微博的语言特点和独有的表情特点,在结合了表情加权和语义规则的基础上,又融入一些特殊的影响情感倾向的情感词,从多个方面对情感倾向进行分析,对情感倾向的判别具有一定的修正作用,相比较其他3种方法,本文提出的微博情感倾向分析的平均准确率达 78.4%,整体上提高了情感倾向分析的准确率.
由图4可知,4种情感倾向分析方法的平均查全率都大于70%,而本文方法的平均查全率最高,为 75.2%.这是因为中文微博比较口语化且时效性强,经常出现一些新兴的网络词汇,而普通情感词并不包含这些.因此,本文方法在普通情感词中同时融合否定词、程度副词和网络新词的方式,对情感倾向的分析更加全面、准确.
由图5可知,本文方法的平均F值最高,为76.7%,其中中性倾向的中文微博F值整体上都低于正向和负向情感倾向的F值.这主要是因为正向和负向情感倾向的中文微博通常都带有明显的情感倾向标志,而中性情感倾向的中文微博容易因为中文语言特点造成误判,例如“垃圾分类是一个严肃的问题”,“严肃”一词,在情感词典中被划分为负向情感词,但此文本是在阐述事实,是一种中性情感,这就影响了中性情感分析的结果.
整体而言,随着实验方法中衡量微博情感倾向的因素增多,正向、中性和负向倾向的中文微博情感分析指标都有所提高,而通过融入表情符、语义规则、否定词、程度副词和网络新词众多特征后,中文微博情感倾向分析的平均准确率、平均查全率和平均F值都有一定程度的提高.但即使从多方面考虑影响微博情感倾向的因素并对其偏差进行修正,本文方法的平均准确率仍未突破80%.造成这种状况的原因可能是,用户在发布微博时,存在语言、符号和表情滥用的情况,或者文本中存在着讽刺意味,这对微博情感倾向的分析带来较大的干扰.
3 结语
针对目前中文微博情感分析方法考虑因素不全面,从而导致情感分析结果不佳的问题,本文根据中文独特的语言方式和微博文本信息量大、时效性强、随意性强等特点,充分考虑影响情感分析结果的各方面因素,提出了一种基于语义规则和表情加权的中文微博情感分析方法.该方法从微博文本的多方面特征考虑,在传统情感词的基础上进行拓展,融入了否定词、程度副词、网络新词,并使用表情加权和语义规则进行权值求和确定情感倾向.实验结果表明,本文提出的中文微博情感分析法效果显著,相较于其他3种分析方法,本文方法的平均准确率(78.4%)、平均查全率(75.2%)和平均F值(76.7%)相对较高.但该方法对于歧义句的分析效果还不令人满意,在对具有讽刺意味的语句进行情感分析时,发生误判的概率较高,后续将会结合具体领域和情境对中文微博情感分析做更深入的研究.参考文献:
[1] YU Y.Text emotional analysis based on Twitter data[J].Information and Computer,2018,46(19):151.
[2] PAK A,PAROUBEK P.Twitter as a corpus for sentiment analysis and opinion mining[C]∥European Language Resource Association.Proceedings of International Conference on Language Resource and Evaluation.Valletta:LREC,2010:1320.
[3] RILOFF E,WIEBE J.Learning extraction patterns for subjective expressions[C]∥Association for Computational Linguistics.Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing(EMNLP-03).Sapporo:EMNLP,2013:105.
[4] 朱嫣嵐,闵锦,周雅倩,等.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006(1):14.
[5] 谭皓,邓树文,钱涛,等.基于表情符注意力机制的微博情感分析模型[J].计算机应用研究,2019,36(9):2647.
[6] 李继东.基于扩展词典和规则的中文微博情感分析[D].北京:北京交通大学,2018.
[7] 王文,王树锋,李洪华.基于文本语义和表情倾向的微博情感分析方法[J].南京理工大学学报(自然科学版),2014(6):733.
[8] 刘志明,刘鲁.基于机器学习的中文微博情感分类实证研究[J].计算机工程与应用,2012,48(1):1.
[9] 于韬,李伟,代丽伟.基于Python的新浪新闻爬虫系统的设计与实现[J].电子技术与软件工程,2018(9):188.
[10]林江豪,顾也力,周咏梅,等.基于表情符号的情感词典的构建研究[J].计算机技术与发展,2019,29(6):181.
[11]梁亚伟.基于表情词典的中文微博情感分析模型研究[J].现代计算机(专业版),2015(21):7.
[12]宋沛玉.面向中文微博情感分析的多特征融合方法研究[D].广州:广东工业大学,2018.
[13]蔺璜,郭姝慧.程度副词的特点范围与分类[J].山西大学学报(哲学社会科学版),2003(2):71.
[14]杨立月,王移芝.微博情感分析的情感词典构造及分析方法研究[J].计算机技术与发展,2019,29(2):13.
[15]姜杰,夏睿.机器学习与语义规则融合的微博情感分类方法[J].北京大学学报(自然科学版),2017,53(2):247.
[16]陈国兰.基于情感词典与语义规则的微博情感分析[J].情报探索,2016(2):1.
[17]赵天奇,姚海鹏,方超,等.语义规则与表情加权融合的微博情感分析方法[J].重庆邮电大学学报(自然科学版),2016,28(4):503.
[18]王志涛,於志文,郭斌,等.基于词典和规则集的中文微博情感分析[J].计算机工程与应用,2015,51(8):218.
- 心脏彩超在高血压心脏病检测过程中的敏感性和特异性分析
- 1.5T磁共振不同序列单独及联合应用对乳腺良恶性肿瘤鉴别诊断的价值分析
- 孤立性肺小结节胸部CT的临床表现
- 经宫腔镜子宫内膜息肉切除术62例临床分析
- 侵袭性血管黏液瘤 例及文献复习
- 凝血四项检测对预防妊娠晚期孕妇产后出血的诊断价值分析
- 输尿管硬镜碎石术与软镜碎石术治疗输尿管结石及术后并发症效果分析
- 微生物检验控制医院感染的I临床价值分析
- 急性胰腺炎消化内科治疗的临床疗效体会
- 5570例老年人健康体检结果分析
- 浅谈后腹腔镜手术治疗泌尿外科上尿路疾病的临床效果
- 苏州地区下呼吸道感染支原体感染的流行病学分析
- 化痰通络理气法中药联合针刺治疗肥胖2型糖尿病患者的临床疗效
- 中医食疗法应用于糖尿病患者的临床疗效观察
- 按摩四神聪穴结合温针对颈椎病记忆减退患者的效果研究
- 中医辩证治疗脂肪肝的临床研究
- 《脾胃论》四时用药特色探析
- 婴幼儿腹泻的外治疗法
- 针灸结合中药治疗神经性耳鸣的临床疗效观察
- 针灸治疗颈椎病的临床作用探究
- 中医定向透药治疗在慢性阻塞性肺病急性加重期的效果观察
- 中医透药疗法对于眩晕症的治疗
- 针刺安眠穴联合三阴交温针灸治疗痰湿中阻型失眠的临床效果
- 慢性盆腔炎治疗的中医探讨
- 针灸对带状疱疹后遗神经痛的治疗效果及疼痛评价
- more full blown
- more full fledged
- more full grown
- more full length
- more full scale
- more full time
- more go ahead
- more god fearing
- more go getting
- more goggle eyed
- more good for nothing
- more good looking
- more good natured
- more goody goody
- more goose pimply
- more grown up
- more hair raising
- more half baked
- more hands-on
- more happy go lucky
- more hard boiled
- more hard copy
- more hard hitting
- more hard nosed
- more hard pressed
- 挠怀
- 挠情
- 挠扰
- 挠抑
- 挠抗
- 挠挠
- 挠挫
- 挠搅
- 挠曲枉直
- 挠栋折鼎
- 挠格
- 挠正
- 挠沮
- 挠滑
- 挠留犁酒
- 挠痒痒
- 挠痒痒(儿)
- 挠直为曲
- 挠着屁股转
- 挠着痒处
- 挠耳
- 挠腮
- 挠腮抓耳
- 挠腮挝耳
- 挠节