穆哈麦德
【摘要】 互联网+已经是当前国内行业经济发展的重要基础和技术支撑,搜索引擎技术的目标任务就是将用户查询返回的结果进行排序,这个排序的标准就是按照与用户查询的相关程度进行排序,而如何获得这个最准确的返回列表也正是排序学习所要研究的重点。本文对比了几种常见排序算法,同时对于重点提出的基于蚁群算法的排序算法与经典的直接优化算法进行了比较分析。
【关键字】 排序 排序算法 对比
排序学习主要是根据给定的对象集合,学习一种完整的排序模型,以此来计算各个对象的分值,然后利用这些分值对这些对象进行排序。己有的排序学习算法在处理小规模数据集时可以表现出良好的算法性能,然而在大数据的背景下现有的算法在处理大规模数据时面临训练模型时间缓慢,内存消耗大等问题,尤其是在一些需要实时处理数据的领域,这些问题的解决显得尤为迫切,成为一个值得研究的具有理论和应用价值的问题。
一、排序学习算法的比较
排序学习对搜索引擎的研究产生了很大的影响,一般在针对某个社会、管理或者其他领域的复杂问题进行系统分析时,所面临的问题经常是一个由多个因素影响,且各个因素之间相互制约的复杂排序问题。要解决这类问题,必须寻求到一个简洁、有效、实用的排序方法,并行排序方法为这类问题找到了解决方案。比较好的排序方法的特征是能够合理的考虑定性与定量因素,将复杂的決策过程按照思维、逻辑规律进行层次化与量化。这是经济系统决策科学中的一种常用方法、一种有效的决策工具。层次分析法所依据的原则就是主要靠决策者以及用户的既有经验,既通过定性方法,也通过定量方法,然后综合判断每个目标的实现的可能性以及互相影响的关系,同时界定重要程序,从而结合这三个方案来赋予一定的权重,通过权值之间的组合给方案进行优劣排序,相比于只使用定量方法来解决问题,效率更高,针对性更强。主要包括以下几个方式:单文档方式是指将单个文档作为训练样本,使得根据从训练样本学习到的分类或者回归函数对文档评分,从而根据这个评分结果决定它的排序。2007年,美国一些人员通过研究将将多类别分类引入到排序问题中从而提出了McRank算法。2012年,程凡提出了基于Point-wise的直接优化的排序算法。
文档列表方式是将查询结果的列表作为模型训练用的实例,其最终目的在于最小化文档列表的损失函数来达到优化排序结果的效果,文档列表方式是最具现实意义的方法因为它将排序问题看待为更实际的模型。2007年Z.Cao等人提出的ListNet算法根据定义的排列概率与实际排序的序列的KL距离作为损失函数进行学习。2014年,缪志高将半监督引入了List-wise排序学习框架,基于这种半监督的排序学习算法可以更加有效地提升算法性能。
二、基于蚁群算法的并行排序算法
蚁群算法是一种仿生算法,具有路径概率选择机制,信息的正负反馈机制,几乎所有的蚂蚁都沿着一条路径行走,该条路径就是一条最优路径,在很多领域得到成功的应用,也可以应用到排序算法中。
设有一组用户浏览的记录为:S={(n1,n4,n8),(n1,n4),(n1,n4,n7),(n1,n3,n7),(n1,n3,n6),(n1,n3,n7),(n1,n3,n6),(n1,n2,n5,n3,n7),(n1,n2,n5),(n6,n7))
蚁群算法的Web站点排序模型如图1所示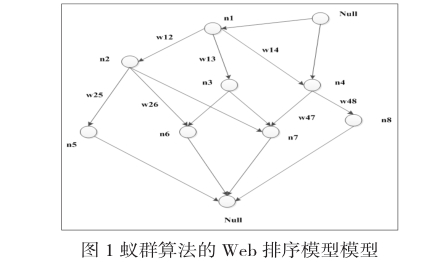
基于蚁群算法的排序模型包括以下策略:(1)首先建立一个比较简单的文档列表;(2)然后通过利用文档列表建立一种群体用户模型;(3)采用蚁群算法对最优排序进行求解。
三、比较分析
为验证第2节中的基于蚁群的排序算法效率,接下来对比了本文算法与的直接优化排序算法,对于不同的事务长度,排序的效率如表1所示: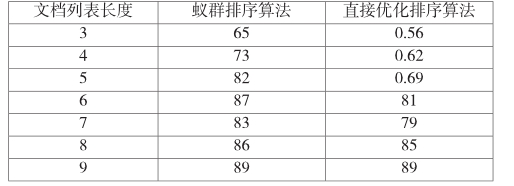
因此,相对于直接优化排序算法,蚁群排序算法的排序效率和准确度更高,主要由于蚁群算法采用信息素机制实现正负反馈机制。
四、结论
现在是海量数据以及物流极度发达的一个时代,为了更好的配置资源,降低实体化的路途成本,充分利用当前数据库以及分布式技术的优势,实现多方合理资源共享以及降低成本,提高企业工作效率与利润。而如何进一步挖掘互联网下所产生的海量数据信息,进行快速排序,是一个具有高度价值与前景的课题。集成了数据仓库、数据挖掘技术一体的商业智能,则为显性知识中的并行排序提供了良好的方式,为企业提供有价值的信息以支持决策。
本文将蚁群算法引入到排序建模中,通过蚁群算法的正负反馈机制和路径概率选择机制快速排序,取得很好的效果。
参 考 文 献
[1] R.Cooley.Web Usage Mining: Discovery and Application of Interesting Patterns from Web data. PhD thesis, Dept. of Computer Science, University of Minnesota, May 2000.
[2] 郑先荣,汤泽滢,曹先彬.适应用户兴趣变化的非线性逐步遗:怎协同过滤算法[J].计算机辅助工程,2010,16(2):69-73.
[3] 涂承胜,鲁明羽,陆玉昌.Web挖掘研究综述[J].计算机工程与应用,2003,10:90-93.
- 信息化视角下的工程机械设备采购管理
- 建设工程施工管理过程中的质量控制问题研究
- 浅析企业文化建设在企业管理中的重要性
- 中小企业人力资源管理中的劳动关系管理问题与优化策略
- 印染废水处理技术研究进展
- 铁路货车轮轴检修中常见故障与策略探究
- 多层与高层建筑中选用塔吊施工的问题研究
- 水利施工技术创新及混凝土施工技术研究
- 对土建工程新型混凝土材料的应用探讨
- 传感器网络中的传感器配置问题研究
- 页岩气储层录井配套技术应用新进展
- 电厂化学的绿色处理趋势和研究
- 关于铁路单线隧道接触网弓形腕臂预配平台的相关研究
- 工业机械设备电气工程自动化技术的应用研究
- 路桥施工工程中钻孔灌注桩施工技术的应用探微
- 复杂地质条件下高面板堆石坝工程质量控制措施阐述
- 技术线损管理浅析
- 铁路敞车车门检修中存在的问题及检修工艺改进
- 探究电气化铁道供电系统新技术的发展
- 市政工程测量中如何使用放线技术
- 试论大数据技术在生态环境保护领域的应用架构及相关技术
- 二维码技术在气瓶安全管理上的应用
- RFID技术在物资仓储配送的应用
- 高层住宅全钢爬架与铝合金模板结合的优势及施工技术总结
- 论VR技术在建筑室内设计中的应用
- beeping
- beeps
- beeps'
- be equal to
- be equipped to do sth
- beer
- beer gut
- beers
- bees'
- bees
- bees-knees
- be estranged / become estranged
- beeswax
- beeswaxed
- beeswaxes
- beeswaxing
- beet
- beetle
- beetled
- beetler
- beetlers
- beetlers'
- beetles
- beetle's
- beetlike
- 玄宫
- 玄宵
- 玄尊
- 玄市
- 玄帝
- 玄干
- 玄序
- 玄庐
- 玄应
- 玄应音义
- 玄度
- 玄律
- 玄律穷,严气升
- 玄微
- 玄思
- 玄情
- 玄想
- 玄成
- 玄成文彩
- 玄房
- 玄扃
- 玄扉
- 玄教
- 玄文
- 玄方