周孝辉
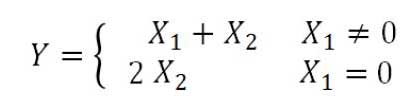
【摘要】? ? 近些年中国电影市场飞速发展,仅2021年春节档电影票房就破百亿,国内用户选择影片观影时会参考豆瓣电影评分,也会表发影评并打分,由于智能手机的普及,人们大多习惯在各类手机APP或者网站上发表评论,这类评论多为短文本,本文旨在通过对影评的情感分析,结合用户对电影的评分计算出一个更符合用户真实想法的电影评分。该评分可以供用户和影院参考,协助其做出观影决策和排片。相比传统CNN模型,胶囊网络在小型数据集上可以取得更好的效果,并且有更好的鲁棒性以及拟合特征能力。我们先用网络爬虫技术爬取豆瓣影评数据并进行预处理,然后将处理好的数据输入到ALBERT层进行序列化,再将ALBERT层输出的文本特征分别输入到Bi-GRU层和胶囊网络层获取句子全局特征和局部特征并进行特征融合,再经过全连接层进行线性降维,然后将全连接层的输出结果输入到Softmax层进行分类得到对应情感类别,最后结合电影的星级评分计算电影的综合评分。
【关键字】? ? 短文本? ? 情感分析? ? Bi-GRU? ? 胶囊网络
引言:
情感分析,也称为观点挖掘、意见挖掘、极性分类,本质上是一个情感分类问题,主要研究人们对实体的看法、态度和情感,是自然语言处理领域中的一个重要研究方向。传统的情感分析方法主要是基于机器学习,需要复杂的特征工程,且泛化能力较差,近年来崛起的深度学习方法很好的弥补了基于机器学习方法的缺陷,成为了情感分析的主流方法。
主流的深度学习方法,大多基于CNN模型或者RNN模型,存在着诸多不足:CNN获取信息能力取决于卷积核窗口长度,捕获能力有限,且不能学习上下文信息;RNN容易出现梯度消失或者梯度爆炸现象。由于这些原因,胶囊网络(Capsule Network)、长短期记忆网络(LSTM)、门控循环单元(GRU)、双向长短期记忆网络(Bi-LSTM)等变体开始流行。本文提出一种基于深度学习的短文本情感分析方法。
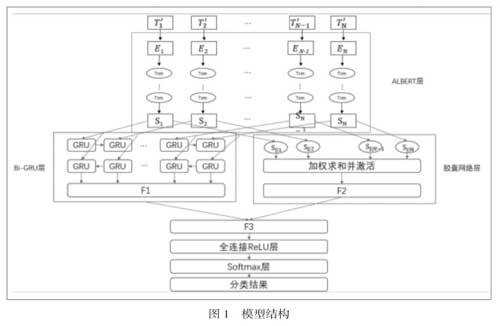
一、模型结构
情感分析属于自然语言处理领域,本文提出的模型结构如图1所示,主要分为以下模块:
1.文本预处理模块:通过网络爬虫技术爬取豆瓣影评T,进行清洗和预处理操作使文本结构化得到数据T1,预处理操作包括去特殊符号、去英文、去数字、去停用词和中文分词。
2.词向量嵌入模块:使用预训练好的ALBERT模型对结构化数据进行序列化,得到文本对应的序列S。
3.征提取模块:包括Bi-GRU层、胶囊网络层和特征融合层,其中Bi-GRU层提取文本的全局特征,将序列S分别输入前向GRU层和后向GRU层中进行训练得到向量表示和,将两者叠加得到向量F1;膠囊网络层用于提取文本的局部特征,将序列S输入到胶囊网络层,使用动态路由算法进行特征提取,得到特征向量F2;特征融合层,将特征向量F1和F2向量进行特征融合,得到新的特征向量F3。
4.全连接层:用于将上一层输出F3全连接至本层的输出神经元,输出一个特征向量V。
5.Softmax分类层:用于将全连接层输出的特征向量V进行归一化,得到文本对应每一类的概率矩阵M,M的最大值索引即文本对应的情感标签,包括好评,中评和差评,分别对应数值“5”,“3”和“1”。
6.输出层:综合用户对影片的评分和文本对应的情感标签对影片进行评价,用户对影片的打分为X1,如果评分缺失设定X1为0,基于情感分析的影评评分为X2,影片的最终评分计算公式如下:
二、算法介绍
2.1 文本预处理
2.1.1网络爬虫
网络爬虫技术,也叫爬虫程序,是自动搜索并下载互联网资源的程序或脚本。通常可以分为四类:主题网络爬虫、通用网络爬虫、增量式爬虫和深层网络爬虫。本方法使用的主题爬虫能只抓取预定义主题相关的页面,避免了无效信息的干扰。
网络爬虫可以用JAVA、PHP、Python等各种语言实现,由于Python拥有脚本语言中最丰富的类库,我们使用Python的Selenium库模拟主流浏览器的运行,实现模拟登陆、自动翻页,自动点击等交互操作。
2.1.2去停用词
文本中存在着大量与文章主题无关的字母、标点、助词等,如“你”、“了”、“的”等,进行预处理时将这些删除以免对文本分类结果造成影响。
2.1.3中文分词
词对于中文来说是表示语义的最小单元,和英文用空格隔开不同,词与词之间没有天然分隔,对于计算机理解较困难,分词尤为重要。我们选用的jieba分词工具,是一种免费开源的分词工具,支持精确模式、全模式和搜索引擎模式三种分词模式:精确模式, 试图将句子最精确地切开,适合文本分析;全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;搜索引擎模式,在精确模式的基础上,对长词再词切分,提高召回率,适合用于搜索引擎分词。
2.2 ALBERT
常用的Word2Vec模型只考虑了文本的局部信息,Pennington等为了克服其缺陷提出的Glove模型,虽然同时考虑了局部与整体信息,但本质上仍然是静态的词向量,舍弃了大量的位置信息。Devlin等人2018年提出的BERT(Bidirectional Encoder Representations from Transformers)是一种动态词嵌入技术,在NLP领域的11个方向大幅刷新了精度,但是其所需训练时间较长,会导致内存不足等问题。
ALBERT(A Lite BERT)模型是基于BERT模型的一种轻量级预训练语言模型,其和BERT一样采用双向Transformer获取文本特征表示,但通过嵌入层参数因式分解和跨层参数共享大幅减少了模型参数,降低了训练时的内存开销并提升了训练速度。
2.3 Bi-GRU
RNN(Recurrent Neural Network)容易出现梯度消失或者梯度爆炸现象,LSTM(Long Short-Term Memory)和Bi-GRU(Bidirectional Gated Recurrent Unit)通过引入門控机制缓解了这两个问题。GRU相较LSTM只有更新门zt和重置门rt两个门控单元,模型训练时间更短。
本方法使用的Bi-GRU,是一种双向的基于门控的循环神经网络,由前向GRU和后向GRU组成,通过两个方向遍历文本,得到包含文本上下文的信息,解决了GRU模型只能包含上文信息的问题,同时速度相比其他序列模型有一定提升。
2.4 胶囊网络
2011年Hinton等首次提出胶囊网络的概念,其用向量胶囊代替卷积神经网络中的神经元、动态路由机制代替池化操作、Squash函数代替ReLU激活函数,在图像识别领域取得了很好的效果。
近年来,人们开始尝试将胶囊网络用于自然语言处理领域,并逐步取得不错的效果,本方法中胶囊网络的动态路由算法可以动态学习神经网络层之间的关系并保留句子中出现概率较小的语义特征,保证特征信息的完整性,且其相比CNN有更好的鲁棒性以及拟合特征能力。
三、结束语
本文提出了一种基于深度学习的短文本情感分析方法,本方法使用ALBERT预训练的动态词向量代替传统的静态词向量,提升了词向量的表征能力,为之后的分类奠定了很好的基础,很大程度上提高了分类的准确性;本文使用Bi-GRU负责全局特征提取,相比常用的单层或者双层神经网络可以得到更好的效果;本文使用胶囊网络负责局部特征提取,保证特征信息的完整性,速度和鲁棒性相比传统方法有一定提高。
参? 考? 文? 献
[1] Pawe? Cichosz. A Case Study in Text Mining of Discussion Forum Posts: Classification with Bag of Words and Global Vectors[J]. International Journal of Applied Mathematics and Computer Science,2018,28(4).
[2] LAN Z,CHEN M,GOODMAN S,et al.ALBERT:a lite BERT for self-supervised learning of language representation.
[3]冀文光. 基于Attention-Based Bi-GRU模型的文本分类方法研究[D].电子科技大学,2019.
[4]薛炜明,侯霞,李宁.一种基于word2vec的文本分类方法[J].北京信息科技大学学报(自然科学版),2018,33(01):71-75.
- 发挥基层组织作用 切断社会矛盾源头
- “互联网+”视域下推进国家治理现代化研究
- “一带一路”背景下中国与土耳其的关系
- “一带一路”背景下的中国与中东欧
- 美国非政府组织的发展对改善政府“信任危机”的重要影响
- 美国对欧亚危机稳定性的判断和比较
- 海洋法视域下的南海海盗治理问题
- 试论海上人命救助的报酬请求权
- 著作权法视野下戏仿作品的定位与规制
- 知识产权权利限制的经济学分析
- 预告登记后基于公权力的中间处分的效力问题研究
- 论网络侵权案件的管辖权
- 论网络侵权责任的承担
- 网络虚拟财产继承的立法探讨
- 论代孕所生子女的法律地位
- 我国集体土地征收中土地补偿费分配的立法及司法现状
- 当代中国的“群体性事件”:成因与预防机制
- 基于公共政策执行过程模型的“限塑令”执行影响因素分析
- 新《环保法》的一些启示
- 避风港原则在ISP责任承担中的适用
- 古代镖局业与国外保安业对我国保安服务业建设的启示
- 以第三方参与治理促进企业安全生产
- 高校大学生文化志愿者服务模式研究
- 高校教师信用共享平台建设问题研究
- 社区警务工作改革若干问题研究
- warming up
- warmly
- warmness
- warmnesses
- warmonger
- warmongering
- warmongerings
- warmongers
- warms
- warm somebody/somethingup
- warm somethingup
- warm sth up / warm up
- warms up
- warmth
- warmthless
- warmthlessness
- warmthlessnesses
- warmths
- warm to
- warm to sb/sth
- warm to sth
- warm to/towards sb
- warm towards
- warm-up
- warm up
- 脱了裤子推磨——转着圈儿败兴
- 脱了裤子放屁
- 脱了裤子放屁——费两道手
- 脱了轨的火车
- 脱了鞋子跑步——脚踏实地
- 脱了鳞的黄花鱼
- 脱亡
- 脱产
- 脱似
- 脱位
- 脱体
- 脱使
- 脱俗
- 脱俗不凡
- 脱俗不凡的幽雅风姿
- 脱俗不凡的情致风韵
- 脱俗不凡的情趣
- 脱俗不凡的风度
- 脱俗的风姿
- 脱俗的风度,高尚的品格
- 脱俗离尘
- 脱俗离尘离尘绝俗
- 脱保
- 脱光
- 脱光衣服打屁股——让人面子上过不去