刘岩

摘要:光学元件损伤检测是激光驱动器健康管理的重要环节,复杂的原始损伤图像是损伤检测研究中的挑战性问题。卷积神经网络是深度学习的重要结构,在图像识别领域里有很好的应用实例。针对复杂环境下的光学元件损伤检测问题,提出一种基于卷积神经网络的损伤定位方法。设计了一种含有损伤和背景的数据集制作方法,生成大量伪数据。设计并训练卷积神经网络,得到分类器的参数模型。用多尺度分割原始损伤图像,并对每一分割区域进行归类和处理。实验结果证明,该检测方法具有较高的识别率和鲁棒性,可有效规避大规模噪声对损伤检测的影响。
关键词:损伤检测;深度学习;卷积神经网络
中图分类号:TP183 文献标识码:A 文章编号:1009-3044(2017)04-0178-05
1 概述
光学元件损伤检测技术在许多光学装置中都有重大应用,如大型光学望远镜、高功率激光驱动器等,损伤检测的结果为装置健康维护提供重要依据。
根据检测环境的不同,损伤检测系统可分为在线检测和离线检测。在离线检测中,通过成像设备可获得高质量的原始损伤图像,图像中的噪声低、类型单一,得到的损伤检测结果足够精确,但离线检测存在着检测周期长、成本高的问题。与离线检测相比,在线检测直接利用光学装置中的成像单元采集工作状态下的图像,将其作为原始损伤图像,虽然精确程度低于离线检测,但其效率高、成本低。在线检测也存在固有问题:大规模噪声和复杂背景,如图1所示,这对损伤识别造成了严重影响,该图像为激光设备中CCD采集得到的原始损伤图像,实线标记内为明显损伤,其与背景噪声存在明显差异,虚线标记内为非明显损伤,其与背景噪声融为一体。
在经典的边界检测和区域检测算法中,原始图像可经过降噪滤波、二值化、边界提取算子等处理方法,得到边界和包围区域。这种处理方法实现简单,但在实际应用中,受高噪声、复杂背景和参数设置的局限性,鲁棒性很差,处理效果不好。在损伤识别中,微小损伤往往被背景噪声环绕,大范围的滤波对噪声有一定的抑制作用,对微小损伤同样是严重的破坏。为了改善边界提取效果,很多研究者在边界提取过程中综合了梯度方向、梯度大小、灰度曲率、拉普拉斯交叉特征等参考因素来动态修正边界检测结果[1]。面对更为复杂的检测环境,甚至需要人工添加标记点来辅助边界的检测[2],目的是为了规避全局噪声影响,在局部生成一条最优边界。在大范围噪声和复杂环境下,区域化处理是一种有效的方法。
损伤检测区域化处理的关键在于对背景噪声区域和损伤区域的识别。这个过程需要对二者进行特征提取和训练。常用的人工特征提取算法具有局限性,同一类对象表现形式的跨度越大,人工特征提取算法所得到的特征的代表性就越低。面对原始损伤图像中千变万化的背景噪声,很难设计一套将损伤和背景噪声显著区分的特征提取算法。深度学习是集特征提取和训练于一体的多层人工神经网络,按照节点间的连接关系和训练方式的不同,深度学习可分为深度信念网[3]、卷积神经网络[4],[5](Convolution Neural Network, CNN)、循环神经网络[6]等。CNN由Yann LeCun第一次提出并成功应用在MNIST手写数字识别任务中[5]。在众多深度学习网络结构中,CNN凭借其独特的卷积结构,对图像类型的数据有更好的特征提取和描述,在图像识别领域里具有天然优势,被广泛应用在各种复杂的实际问题中,如情感预测[7]、人体行为检测[8]、人脸匹配[9]、车辆类型识别[10]、交通信号标志识别[11]、医学影像识别[12]、自然图像层次分割[13]等。
本文以高功率激光驱动器为背景,设计了一种CNN结构,对原始损伤图像进行区域识别和局部处理,实验中的所有数据均由高功率激光驱动器中的科学CCD采集得到。本文的内容安排如下:第二节介绍多层网络结构和CNN;第三节中介绍损伤检测流程;第四节中介绍实验数据、检测效果及分析;第五节对整个在线损伤检测系统进行总结。
2 多层神经网络结构与卷积神经网络
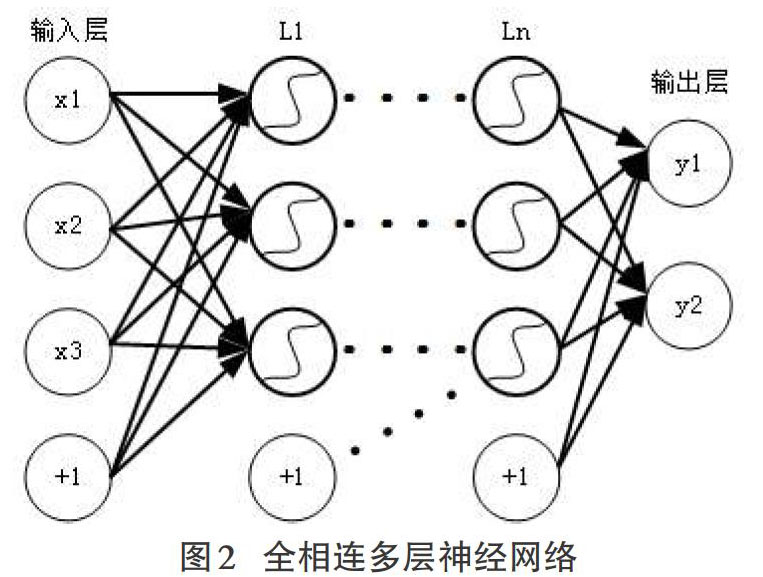
深度学习结构的基础是多层神经网络,如图2所示。多层网络结构中含有输入层、中间隐藏层、输出层。相邻的不同层之间的节点均有权值连接,这样的结构为全相连结构,每个中间節点输出值为公式(1)所示。
其中ω为层与层之间的参数矩阵,每一行为隐藏层节点与上层连接参数向量,b为偏移参数向量,x为输入行向量,f为激活函数,常用的激活函数有阶跃函数、sigmoid函数、双曲正切函数等。
CNN是一种特殊结构的深度学习网络,如图3所示。在CNN中存在着卷积层(C)、减采样层(S)、全相连层(F),且卷积层和减采样层交替出现。在卷积层中,数据会经过卷积核的卷积操作、对应关系叠加、激活函数的处理,形成特征图。在减采样层中,图像数据会根据减采样算子进行减采样操作。全相连层的网络结构同多层网络结构中的相邻两层。
在图3的CNN结构中,采用了SoftMax分类器,其激活函数为:
其中,θ为分类器输出层与输入层之间的参数向量,m是训练样本总数,i表示第i个训练样本,k是分类数量,hθ是输出分类概率向量,其值在0和1之间,总和为1,训练算法是代价函数对参数的梯度下降算法。
CNN的结构具有如下的特点:
A)局部相连
CNN不同于全相连网络结构,其卷积层节点与上层节点之间是局部相连的,如图4所示。局部相连的区域被称为感受野或卷积核,这种设计很大限度的减少了训练参数的数量。在图像中,一个点与周围点的信息相关性比远离点的相关性强,CNN更关注图像的局部特征。B)参数共享
在CNN卷积层中包含多张特征图,每张特征图都是由训练参数组成的卷积核与上一层的图像进行卷积操作得到的,并且这些参数在同一对应关系中是共享的,如图5所示,实线和虚线分别代表两组不同参数所组成的卷积核,这是CNN相比全相连多层网络结构参数大幅减少的另一个原因。假如上一层每张图像的尺寸为M×M,卷积算子尺寸为N×N,则卷积层中特征图的尺寸为:
特征图的数量是设计者在网络结构设计时决定的,并且一张特征图可以与上一层的一张图像对应(图7所示情况),也可以与上一层多张图像相对应。但不管哪种方式,都应保证在上下两层之间,两张图像的对应参数是共享的。
C)池化、减采样
池化操作是对特征图减采样的过程,如图6所示。池化的类型有最大值池化和平均值池化,最大值池化是在池化算子区域内寻找最大值,平均值池化是在池化算子内计算平均值。特征图的池化不仅降低了节点数量,同时也很好地保留了图像的局部特征,达到了特征降维的目的。
3 损伤检测流程
损伤图像处理的主要结构和流程如图7所示。主要包含:多尺度区域划分、子图像标准化、CNN识别、局部区域图像处理、损伤图像整合。接下来对每个单元的功能进行详细介绍。
输入图像单元:输入图像为像素600×600的原始损伤图像(原始损伤图像为灰度图像);
多尺度区域划分单元:按照不同的尺度,将原始损伤图像划分为不同尺寸检测区域,目的是降低损伤区域被拆分的概率,使损伤在检测区域中保持完整。当划分的尺度标准越多时,损伤在子图像中的完整性就越好,但所需的计算量就越大。实际应用中,损伤尺寸在10-20像素之间,用35×35和50×50两种尺度对原始损伤图像进行划分,损伤在所有不同尺度的识别区域中基本可以被完整覆盖;
识别区域标准化单元:不同尺度划分下,识别区域的尺寸是不一样的。CNN的输入维度是固定的,所以要把识别区域的尺寸规范到同一标准下。实际应用中,在35×35尺度下,忽略最后5像素的长度和宽度,其余识别区域保持不变。在50×50的尺度下,利用尺度缩放算子,将所有识別区域缩放到35×35尺寸;
卷积神经网络单元:CNN完成对识别区域的分类功能,输入是标准化的识别区域,输出是对应尺度的识别结果矩阵,矩阵中0代表背景区域,1代表损伤区域。实际应用中,输入是17×17和12×12的两组标准化识别区域图像,输出是17×17和12×12的两组识别结果矩阵;
局部区域处理单元:根据识别结果矩阵对原始损伤图像进行局部处理。结果矩阵中0所对应的区域为背景噪声区域,将对应区域的子图像像素置0;结果矩阵中1所对应的区域为损伤区域,将对应区域的子图像进行中值滤波、自适应二值化处理,得到损伤区域的二值损伤图;
多尺度损伤图像整合单元:将每个尺度下的二值图按原有对应位置关系组合,得到不同尺度下的损伤图像,损伤图像个数和尺度划分个数相等。在实际应用中,将得到35×35和50×50两种尺度所对应的两幅二值损伤图像,损伤图像的尺寸与原始损伤图像的尺寸相同;
整合、输出单元:对所有尺度下的损伤图像进行“或”操作,整合成为最终输出的损伤图像。
4 数据和实验
4.1数据制作
数据集是对分类器中的参数进行训练依据,数据集的好坏直接关系到识别效果。目前,在损伤检测领域里,尚未存在一个标准化的数据集,且本文中损伤检测的应用背景是高功率激光设备,训练所需的数据集也应该由该设备采集的原始图像制作而成。
为了制作更加标准的数据集,本文中调研了其他领域里的标准数据集,如MNIST[5](手写数字数据集)、NIST SD19[14](手写字符数据集)、GTSRB[15](德国交通标志数据集)、CIFAR 10[16](彩色自然图像数据集)。这些数据集有如下特点:1、数据量巨大,每类图像的样本数量均超过5000个;2、数据集中设置了训练样本集、测试样本集来进行参数训练和模型测试,个别数据集中还设置了有效样本集,其作用是在训练过程中通过在有效集上的测试,调整训练进度,在必要的时候提前中止训练,防止训练向差的方向发展。由于有效样本集参与了训练过程,所以不再适合用作测试样本集。
结合以上特点,本文所制作的数据集中包含损伤区域和背景噪声区域两类图像,识别区域尺寸设定为35×35像素。在实际应用中,共选定135个损伤区域,且均为明显损伤区域。由于损伤区域的位置会随机出现在识别区域内,所以在对损伤区域采样时,将每个损伤区域分别置于识别区域九宫格中的9个位置,对每个损伤区域进行9次不同位置的采样,共得到1215个损伤样本。对背景噪声的采样应用图像切割的方式,将600×600的所有原始损伤图像按35×35的尺寸进行分割,去除所有包含损伤区域的、不规则的样本,剩下的样本均作为背景噪声样本,共1364个。
Max Pooling\&维度变换\&全相连\&SoftMax\&]
受到原始数据数量的限制,得到的实际样本数量较少,为了扩充数据集的样本数量,获得更好的识别效果,在原有样本的基础上,对其进行处理与扩展,生成大量的伪数据,如图8所示,前两行为损伤区域样本,后两行为背景噪声样本。处理过程包括对原始样本的以下操作:旋转(3次顺时针旋转)、镜面(水平和竖直翻转)、对比度调整(增减10%)、亮度调整(增减10%)。最终得到的数据集中共有12150个损伤数据样本和13640个背景噪声样本,并从中各抽取2000样本组成测试样本集和有效样本集,其余组成训练样本集。在各个样本集中,损伤样本和背景噪声样本是随机出现的
4.2 CNN训练实验
在测试CNN在光学元件损伤检测中的表现效果时,设计了两个实验。
实验1:设计了如表1所示的CNN结构,其中F1与S2之间仅是维度的变换,由S2中50个尺寸为5×5的特征图变换成F1中节点数为1250的特征向量,卷积层所用的激活函数为双曲正切函数,全相连层所用的激活函数为sigmoid函数。用4.1中所制作的数据集进行训练和预测,在每次训练迭代完成时,用测试集对当前模型进行预测,记录错误率。
在CNN训练过程中采用批次训练的方式,每个批次含有500个样本,训练样本集分为24个批次,这样的训练方式是整体训练和逐一训练的折中,相比逐一训练,能保证训练的结果是趋于全局的,相比整体训练,能缩短训练时间。在CNN训练过程中,每次迭代需要训练24个批次,当所有训练样本训练完毕后,一次迭代完成,并用测试集进行测试。得到的结果如图9所示,经过50次迭代,错误率最终稳定在2.75%。
实验2:将实验1中训练好的CNN模型加入到损伤检测系统中,以图1所示的原始损伤图像作为输入,得到最终的损伤图像,得到的损伤检测结果如图10所示。
从损伤图像中可看出,图1中所有明显损伤均已正确识别并二值化处理。在四个非明显损伤中,仅1号损伤体现在了最后的损伤图像中,其余三个并未体现。查询所有尺度下的识别结果矩阵可得到如下信息:
1)四个非明显损伤中,1、2、3号所在区域均被正确识别为损伤区域,仅4号未被识别。2、3号之所以未在损伤图像中体现,是因为在损伤区域局部图像处理过程中,由于灰度变化不明显,自适应二值化算法并不能将损伤和背景噪声二值化区分,所以未被体现;
2)在所有背景噪声区域,有3个区域被误判为损伤区域,但并未对损伤图像造成视觉上的影响,其原因同1中所述。
5 结束语
在本文和相关的工作中,设计了一种区域识别、局部处理的损伤检测处理方式,并在光学元件损伤检测中成功规避了大规模噪声,有较好的识别效果。在数据集制作过程中,利用图像变换获取大量伪数据,扩充了数据集;设计了多尺度区域划分,使损伤尽可能的包含在识别区域内;在区域识别结构中以CNN作为分类器,设计CNN结构和训练方式;依据分类结果完成多尺度下的损伤图像和整体损伤图像。在線损伤检测系统在现有数据中达到了预期的效果。
但在个别环节中仍存在不足:1、CNN分类器对非明显损伤的识别效果还有提升的空间,目前所用的训练集中的损伤样本主要是明显损伤样本,非明显损伤样本数量较少,原因是非明显损伤经过对比度和亮度变换,损伤信息会遭到极大的破坏,使其拓展样本成为脏数据。2、在局部处理中应用的自适应二值化算法仍具有参数局限性,不能满足所有情况。
在今后的研究工作中,会对CNN的结构、多任务的深度学习网络进行研究,并在实际中应用,提升分类单元对噪声的鲁棒性和非明显损伤的识别效果。
参考文献:
[1] Barrett W A, Mortensen E N. Interactive live-wire boundary extraction[J]. Medical Image Analysis, 1997, 1(4):331-341.
[2] F?rber M, Ehrhardt J, Handels H. Live-wire-based segmentation using similarities between corresponding image structures.[J]. Computerized Medical Imaging & Graphics the Official Journal of the Computerized Medical Imaging Society, 2007, 31(7):549-60.
[3] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks.[J]. Science, 2006, 313(5786):504-507.
[4] Lecun Y, Kavukcuoglu K, Farabet C. C.: Convolutional networks and applications in vision[C]// Circuits and Systems (ISCAS), Proceedings of 2010 IEEE International Symposium on. IEEE, 2010:253-256.
[5] Lécun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.
[6] Hochreiter S, Schmidhuber J. Long short-term memory.[J].Neural Computation,1997, 9(8):1735-1780.
[7] Baveye Y, Dellandrea E, Chamaret C, et al. Deep learning vs. kernel methods: Performance for emotion prediction in videos[C]// ACII. 2015:77-83.
[8] Rajeswar M S, Sankar A R, Balasubramaniam V N, et al. Scaling Up the Training of Deep CNNs for Human Action Recognition[C]// Parallel and Distributed Processing Symposium Workshop. IEEE, 2015.
[9] Khalil-Hani M, Sung L S. A Convolutional Neural Network Approach for Face Verification[C]// International Conference on High PERFORMANCE Computing & Simulation. 2014:707-714.
[10] Dong Z, Pei M, He Y, et al. Vehicle Type Classification Using Unsupervised Convolutional Neural Network[J]. IEEE Transactions on Intelligent Transportation Systems, 2014, 16(4):1-10.
[11] Lau M M, Lim K H, Gopalai A A. Malaysia traffic sign recognition with convolutional neural network[J]. IEEE International Conference on Digital Signal Processing (DSP) 2015:1006-1010.
[12] Hatipoglu N, Bilgin G. Classification of histopathological images using convolutional neural network[J]. International Conference on Image Processing Theory, Tools and Applications (IPTA) 2014:1-6.
[13] Jun W, Chaolliang Z, Shirong L, et al. Outdoor scene labeling using deep convolutional neural networks[C]// Control Conference. IEEE, 2015.
[14] Grother P J, Grother P J. NIST Special Database 19 Handprinted Forms and Characters Database[J].Technical repot, National Institute of Standards and Technology(NIST) 1995.
[15] Akasaki K, Suenobu M, Mukaida M, et al. The German Traffic Sign Recognition Benchmark: A multi-class classification competition[C]// Neural Networks (IJCNN), The 2011 International Joint Conference on. IEEE, 2011:1453-1460.
[16] Krizhevsky A. Learning Multiple Layers of Features from Tiny Images,2012.
- 自体脂肪颗粒填充矫正泪槽畸形
- 强脉冲光联合果酸治疗痤疮炎症后色素沉着疗效分析
- Q开关Nd:YAG倍频532nm激光联合光子嫩肤治疗面部雀斑疗效分析
- 黄金微针射频联合透明质酸在面部皮肤年轻化中的应用效果研究
- 手术治疗小儿甲母痣
- 强脉冲光联合氨甲环酸治疗黄褐斑的有效性和安全性分析
- 595nm脉冲染料激光联合果酸治疗寻常性痤疮疗效观察
- 三联综合疗法与二氧化碳激光治疗跖疣疗效比较
- 羟氯喹联合多西环素序贯光电协同治疗I型及Ⅱ型玫瑰痤疮临床观察
- 告作者读者
- 湿性医疗技术在PDL联合CO2点阵激光治疗早期红色瘢痕术后创面修复中的应用研究
- 超分子水杨酸联合米诺环素治疗玫瑰痤疮疗效观察
- 不同缝合方法对皮脂腺囊肿术后修复效果的影响
- 负压创面治疗技术联合整张中厚皮片移植修复肉芽创面
- 异体真皮替代材料联合自体刃厚皮移植在烧伤瘢痕整复中的应用效果
- 部分游离胸大肌肌束填充乳头技术在保留乳头乳晕的乳房切除术中的应用
- A型肉毒毒素联合氟尿嘧啶注射治疗烧伤瘢痕效果评估
- 头皮扩张术结合毛发移植术治疗大面积瘢痕性秃发
- 医用皮肤表面缝合器在胸部正中切口裂开中的应用
- 单层型人工真皮联合自体刃厚皮片一期修复骨/肌腱外露创面的疗效观察
- 心理社会管理对眼睑整形美容患者术后转归和健康状况的影响
- 基于信息-动机-行为技巧模型的干预策略在面部有创激光术后护理中的临床应用
- 基于微信平台的延续性护理对皮肤激光美容患者术后及时干预并减少纠纷的作用分析
- 美容整形门诊手术患者延续护理服务需求调查
- 皮肤美容护理对寻常性痤疮患者愈后外观及心理应激反应的影响
- dress-the-house
- dress up
- dress up/get dressed up
- dressy
- dress²
- dress¹
- drew
- drew in
- drew out
- drew up
- dribble
- dribbled
- dribbler
- dribblers
- dribbles
- dribbling
- dribbly
- dribs and drabs
- dried
- dried out
- dried up
- drier
- driers
- dries
- dries out
- 蟾踆
- 蟾轮
- 蟾辉
- 蟾逃兔遁
- 蟾钩
- 蟾镜
- 蟾阙
- 蟾阙彦
- 蟾魄
- 蟿
- 蟿螽
- 蠁
- 蠃
- 蠃虫
- 蠃蠃
- 蠃负
- 蠃醢
- 蠅
- 蠆
- 蠈
- 蠉
- 蠉飞蠕动
- 蠊
- 蠋
- 蠋蜍