汤慧仪+张俊达
摘要:作为一种基于纹理的矢量场可视化方法,线积分卷积算法能够以纹理图像的形式展示矢量场全貌,并能够较好地展现细节变化,因而是一类行之有效的方法,但计算量巨大,绘制效率较低。针对此问题,提出一种基于CUDA的线积分卷积矢量场并行可视化方法,利用并行计算架构的优势以及图形处理器的快速计算能力,较好地提高矢量场的可视化效率。首先对线积分卷积算法并行化的可行性进行分析,然后针对其中的流线生成和纹理生成两个关键阶段进行并行化改造,将计算密集型的部分转移到图形处理器中进行快速计算,从而较大幅度提高了绘制效率,最后通过实验验证了方法的有效性。
关键词: 线积分卷积;CUDA;矢量场;可视化
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2016)12-0270-03
Abstract:As a texture based vector field visualization algorithm,LIC algorithm can display the complete picture of vector field in the form of image, and show the details of the changes. Aiming at the problem of low efficiency of LIC algorithm for rendering,a parallel liner integral convolution algorithm for vector field visualization based on CUDA is proposed. The streamline generation and texture value calculation in the traditional LIC algorithm are parallel reconstructed. Using GPU to calculate the streamline of all pixels by numerical integration method,and parallel simultaneously computing all pixel values corresponding to the output image texture. The rendering efficiency is significantly improved. In the end, the experiment validates the effectiveness of proposed algorithm.
Key words:LIC; CUDA; Vector field; Visualization
1 概述
空间数据场是一类重要的科学计算数据,广泛应用于海洋、气象、电磁、医学等领域。矢量场是空间数据场的重要组成部分,可同时表征数据大小(如场强)与方向,如海面风场、涡旋、流场等。深刻认知并理解矢量场特征,发现其内在规律,对海洋活动、天气预报、军事指挥等均具有重要意义。
矢量场可视化一直是图形学与可视化领域的研究热点,借助计算机图形学的基本理论,可形象直观地展示研究对象,并在此基础上进行知识挖掘与知识发现。经典的矢量场可视化方法,如点标法、流线法等具有方法简单、易于实现等优点,一直广泛应用。但是由于可视化结果离散且不连续,容易造成视觉混叠、图像杂乱无章、以及关键特征遗漏等问题,因此多用于小范围矢量场局部特征的可视化。基于纹理的矢量场可视化方法,以图像形式展示矢量场的全貌,可以表现细节变化,且较好地展示了矢量场的方向信息,因此是近来的研究热点。线积分卷积算法[1](Line Integral Convolution,LIC)是一种典型的基于纹理的矢量场可视化方法。通过将某一时刻矢量场的前后若干幅图像进行叠加,使得合成图像中像素的灰度,与当前时刻以及前后一段时间在矢量场中所流经像素点(即流线)的矢量相关联。该算法利用同一流线上相近像素点的相关性生成纹理,然后展现矢量场的方向变化趋势。算法具有表现丰富、信息准确、前后关联性强等优点,但计算量巨大,较大程度制约了其广泛应用。
为了解决计算量大的问题,Stalling和Hege在LIC算法的基础上提出了Fast LIC算法[1],将原始算法的效率提升了近一个数量级;随后Zockler等人提出了并行LIC[2],该算法通过挖掘多帧图像中图像空间上的并行性来生成动画序列,使交互式矢量场可视化成为可能。然而,该算法是在大规模并行计算机上实现的,对硬件的要求过高;Hlawatsch等人提出了分级线积分策略[3],利用多核架构对算法中的积分计算过程进行加速,使得算法的计算时间从原先的线性增长关系下降到对数增长关系。尽管如此,当输入矢量场的分辨率增加时,该算法的计算耗时依然较快增长。国内外相关研究人员在提高算法效率方面已经做了大量的理论和方法研究,目前已经形成了一些具有代表性的研究成果[4-6]。
随着计算机技术的发展,低成本、高性能计算日益成熟。通用并行计算架构(Compute Unified Device Architecture,CUDA)由Nvdia公司提出,较好地利用了图形处理器(Graphics Processing Unit,GPU)的浮点运算能力,因而能够较大程度提高计算效率。本文结合CUDA架构,针对LIC算法计算量大的问题,探讨LIC算法的并行化改造方法,以期利用GPU的硬件加速来提高矢量场的可视化效率。首先对LIC算法并行化的可行性进行分析,然后针对流线生成和纹理生成两个关键阶段进行并行化改造,将计算密集型的部分转移到GPU中进行快速并行计算,最后通过实验验证了方法的有效性。
2 LIC算法的基本思路
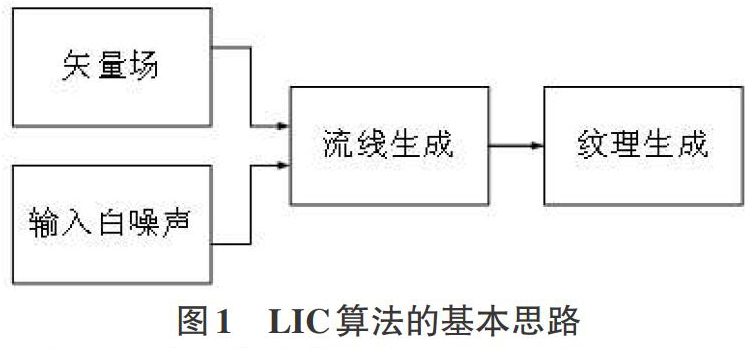
LIC算法的基本思路如图1所示,首先生成一个与矢量场分辨率相同的白噪声作为输入纹理,然后将输入噪声纹理沿矢量场的中的流线进行线积分卷积低通滤波处理,从而得到能够展现矢量场方向信息的输出纹理。
算法的核心步骤为流线生成和纹理生成两个过程,流线生成过程一般采用线积分卷积法,通过流线终止条件(到达临界点、边界点或流线长度上限)的限制,依据矢量数据逐点计算出整条流线对应的所有像素点;纹理生成以相应流线对应像素点的噪声纹理值作为输入,按卷积核函数进行加权求和,遍历全部矢量数据后得到输出图像每一点的输出纹理值,进而形成能够展现矢量场方向变化的纹理图。显然,影响LIC算法时间复杂度的因素主要在流线生成和纹理生成两个阶段,计算过程较为繁琐,耗时较长,如果能够将其并行化,则能有效提高算法效率。
3 基于CUDA的LIC并行计算
2007年6月,Nvdia推出了CUDA架构,利用GPU进行数据的并行计算,其不需要借助图形学API,采用类C语言进行开发,降低了开发难度[7],利用CUDA的关键,是找到算法中适合GPU计算的部分。现针对图1的LIC算法思路,即流线生成和纹理生成两个过程,基于CUDA进行并行计算,将计算密集型的部分交由GPU进行处理,以提高算法的运算效率。
3.1 流线生成的并行计算
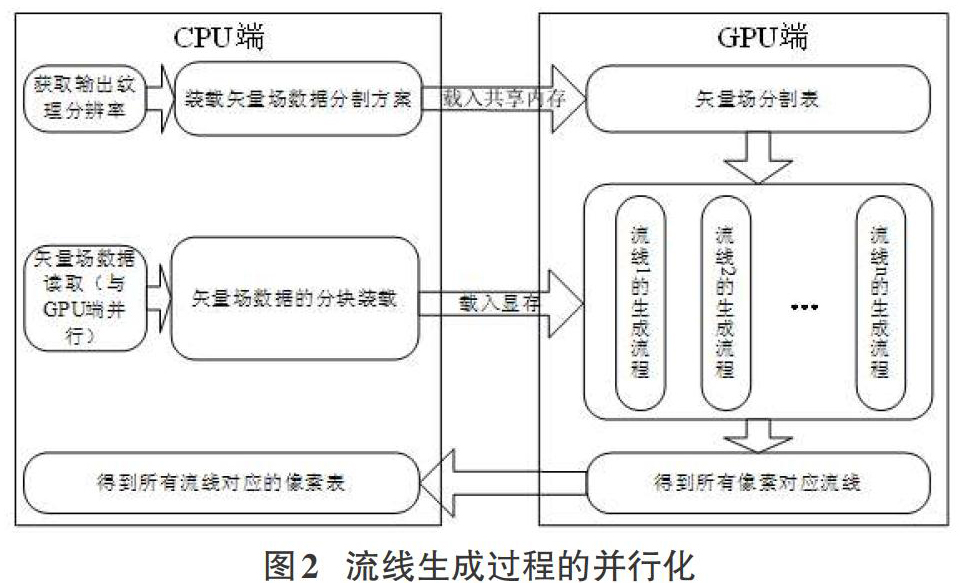
图2给出了流线生成过程的并行化处理流程,其中左半部分由CPU端执行,右半部分由GPU端执行。
其中,CPU端的计算任务主要包括:
1)依据输出纹理图像分辨率,在外部存储器中分配存储空间,供流线像素表使用;
2)读取矢量场数据,并载入GPU共享内存,使得在流线生成时可以快速获取;
3)当矢量场数据量较为庞大时,有时难以一次性载入到显存,所以在CPU端需要对其进行基于空间位置的分块,将每一块数据分别载入显存中进行运算。块的大小将由显存的大小决定。
4)对GPU返回的流线表正确性进行判断,并存储于外部存储器。
可以看出,在CPU端进行的大部分都属于逻辑判断任务,并且具有分支。这使得CPU的逻辑运算以及分支预测能力能够得到最大限度的运用。与CPU端对应,CPU端的计算任务主要包括::
1)读入矢量场数据,分块装载入显存,从每一个像素点出发,采用数值积分的方式(欧拉法、龙格库塔法等)并行计算出所有像素对应的流线,流线的生成过程要满足流线终止条件;
2)将所有流线所覆盖的点按像素存储为流线对应像素表,传回CPU端。
3.2 纹理生成的并行计算
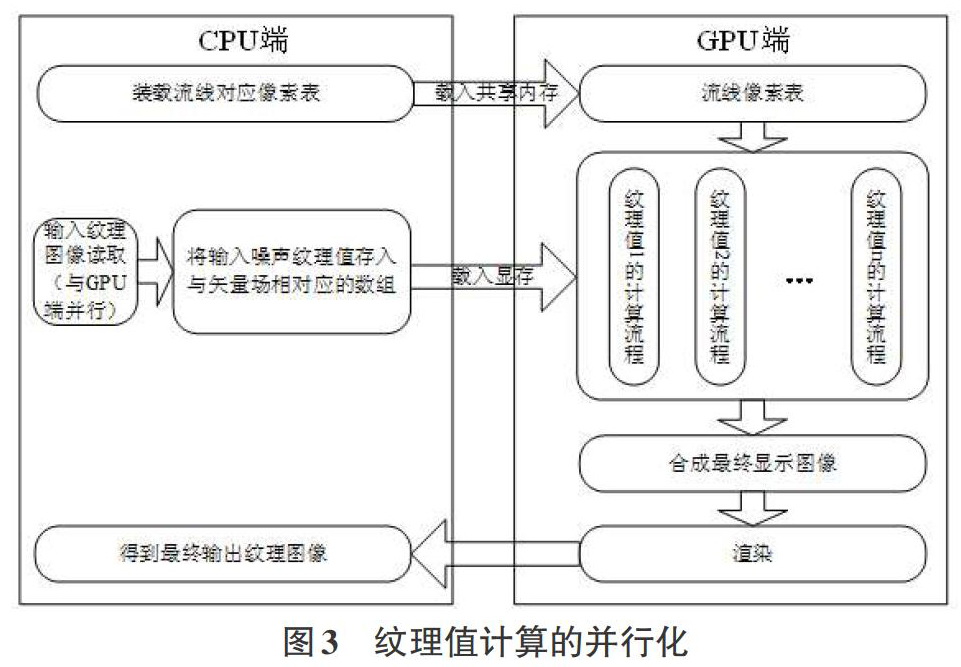
图3给出了纹理生成过程的并行化处理流程。
其中,CPU端的计算任务主要包括:
1)读取流线像素表,载入共享内存,使得在纹理值计算时能够快速读取输入噪声的纹理值;
2)读入输入噪声图像并转化为与矢量场相对应的数组,载入显存;
3)当矢量场数据量较大时,流线像素表可能无法一次性载入共享内存,因此在CPU端同样需要对数据进行分块。
CPU端的计算任务主要包括:
1)依据输入纹理(白噪声)数据和流线像素表,分别读取相应流线各像素点所对应输入纹理的纹理值,而后并行地依据卷积核函数进行加权求和运算,得到各像素所对应的输出纹理值。
2)将所有输出纹理像素值合成显示图像,经过渲染,得到最终输出纹理图像。
4 实验结果及分析
采用数值方法得到的模拟涡旋场作为实验数据,其尺寸为[256×256],与传统LIC算法进行对比实验。同时,为了验证本算法对绘制效率的影响,我们采用双线性插值和等间距采样的方式,对实验数据进行处理,构造出一组尺寸不同的数据,如表1所示。通过对算法运算耗时的统计,综合验证本文方法的加速效果。
实验环境的硬件配置CPU为Intel Core2 quad 2.33Ghz,内存为3G,显卡为NVIDIA GeForce GTS 250,显存为1G。
由图4可以看出,两种算法的绘制效果并没有明显的区别,这主要是因为将算法并行化后并没有改变算法的逻辑顺序和具体方法,只是将其中计算密集型的程序部分交由GPU进行并行的计算,因此从绘制效果的方面来说,两种算法的效果是一致的。
(2)绘制效率对比
绘制效率通过算法运算耗时长短来比较,将五组实验数据算法运算时间分别进行统计,结果如下表所示:
由图5(a)可以看出,传统LIC算法的运算时间随着数据规模的增大迅速增长,不能够满足实时性要求较高的应用场合。本文算法由于运用GPU并行处理大量的数值计算,大幅提高了算法的绘制效率。当数据尺寸较小时,运算效率提高比率在10左右,但由图5(b)可以看出,随着数据规模的增大,由于CPU端的数据分割处理任务愈加繁重,CPU与GPU之间数据传输量不断增长,导致加速比不断下降。
通过实验,本文提出的基于CUDA的线积分卷积矢量场可视化算法不但能够保持原有的绘制效果,还大大提高了绘制效率,能够满足实时性要求较高的应用场合。
5 结论
纹理法作为矢量场可视化的一种较为卓越的表达形式受到广泛关注,但算法运算效率问题一直限制其发展。随着硬件技术的不断发展,使得低成本高效运算成为了可能。本文把LIC算法与CUDA架构相结合,将传统LIC算法的流线生成和纹理值计算过程进行并行化改造,实验结果表明,算法的运算效率得到了较大幅提升,并能够适应大尺寸矢量数据的运算要求。
参考文献:
[1] Stalling D, Hege H. Fast and resolution independent line integral convolution[C]. New York: Proceedings of the ACM SigGraph95, ACM SIGGRAPH, 1995:249-256.
[2] Zockler M, Stalling D, Hege H. Parallel line integral convolution[J]. Amsterdam: Parallel Computing, 1997, 23(7):975-989.
[3] Hlawatsch M, Sadlo F, Weishkopf D. Hierarchical line integration[J]. Los Angeles: IEEE Trasactions on Visualization and Computer Graphics, 2011, 17(8):1148-1163.
[4] S. Bachthaler, D. Weiskopf: Animation of orthogonal texture patterns for vector field visualization[J]. Los Angeles: IEEE Transactions on Visualization and Computer Graphics, 2008, 14(4):741-755.
[5] G. Karch, F. Sadlo, D. Weiskopf. Visualization of advection-diffusion in unsteady fluid flow[J]. New Jersey: Computer Graphics Forum 3, 2012:1105-1114.
[6] D. Weiskopf. Iterative twofold line integral convolution for texture-based vector field visualization[C]. Berlin: Mathematical Foundations of Scientific Visualization, Computer Graphics, and Massive Data Exploration, 2009:191-211.
[7] 朱琪. C到CUDA编译架构研究与实现[D]. 长沙:国防科学技术大学,2011.
- 单板U形池造型大战
- 超级大回转
- 越野滑雪
- 冰球
- 现代冬季两项
- 模拟冰雪游戏 感受冬奥乐趣
- 用一双球鞋和你谈人生
- 校园足球发展的实践探索
- 法国青少年足球教学训练课的组织过程和教学模式
- 落实主题式校本教研 提高教研活动实效
- 巧用体育游戏为主教材添彩增趣
- PDCA循环管理在体育精品课磨课中的应用研究
- 精准分析学情针对实施教学
- 农村小学“一师两班”体育教学模式解码
- 同课异构教学之差异教法辨析
- 同课异构教学之差异教法辨析
- 谈观察、发现、评判、纠正学生运动技术问题的难点与对策
- 对课程标准下课时教学设计的认识
- 一次备课组活动引发的思考及启示
- 体育教学中德育实施的思与行
- 中小学跳远起跳技术训练手段与方法
- 小足球
- 水平三(六年级)小篮球行进间体前变向换手运球教学设计
- 原地单手肩上投篮教学设计
- 水平四《合作障碍跑》教学设计
- of sound mind
- oft
- often
- oftener
- oftenest
- oftenly
- oftenness
- oftennesses
- oftens
- of that/his/their etc ilk
- of the essence
- of use
- of your choice
- of your own
- of your own free will
- ofˌficial receiver
- ofˌficial strike
- ogle
- ogled
- ogler
- oglers
- ogles
- ogling
- ogre
- ogreishly
- 表示祈求、盼望
- 表示祈祷或感叹的唱词
- 表示祈福
- 表示祝愿和感谢
- 表示祝愿平安
- 表示祝贺
- 表示祝贺的信
- 表示祥瑞的景象
- 表示禁戒性的否定
- 表示禁止
- 表示离别
- 表示离别的琴曲
- 表示称赞
- 表示称赞、羡慕、惊讶等
- 表示称马桶
- 表示程度
- 表示程度、数量或方式
- 表示程度不深
- 表示程度加深或减少
- 表示程度或数量的逐步增减
- 表示程度或数量过分
- 表示程度极为严重
- 表示程度极深
- 表示程度极深,使人难以忍受
- 表示程度深