富春岩+葛茂松+张立铭+李微娜+赵佳彬
摘要:该文通对MapReduce调度器中准实时调度算法的研究, 实现了在MapReduce调度器上能够依据正在进行的任务的进度,对任务的完成时间进行估计,在运行时给每个任务动态的分配资源。实验表明,本算法提高了MapReduce系统的资源利用率,达到了准实时MapReduce调度的预期目标。
关键词:MapReduce;调度策略;调度算法
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)15-0003-02
1 引言
MapReduce是一个用于大规模数据集的并行运算模型. 广泛应用于分布式查询、分布式排序、Web访问日志分析、机器学习以及基于统计的机器翻译等领域[1]。MapReduce系统中现有的三种调度器:FIFO调度器、Capacity Scheduler调度器以及Fair Scheduler调度器[2]。目前这三种调度算法,在作业提交前,必须对系统的参数进行预先设定。而且,一旦作业提交,MapReduce系统给每一个任务的资源分配策略就已经确定下来,不能根据任务执行的实际情况进行动态的调整[3]。本文提出的算法使MapReduce调度器能够对正在进行的任务的进度及任务的完成时间进行估计,并在运行时给每个任务动态的分配资源,从而提高了MapReduce系统的资源利用率。
2 算法思想
准实时MapReduce调度算法主要由作业性能估计及任务调度策略两部分组成。
1)作业性能估计的主要思想是:通过作业m中,已完成任务集合的完成时间和任务数量的统计,推测作业m中的任务平均完成时间,并且以此推测正在执行任务的剩余完成时间。然后,准实时调度算法就可以以此作为判断任务性能的依据,确定任务的优先级并对任务进行调度。
2)任务调度策略的主要思想是:根据作业性能估计中得到的任务平均完成时间,通过公式推导,得出作业还需要的任务执行单元的数量,以此确定作业的优先级,调度器再根据作业的优先级,给不同的作业分配相应的资源。任务调度策略包括两部分:一是将合适的优先级赋给作业;二是基于作业优先级的分配算法。
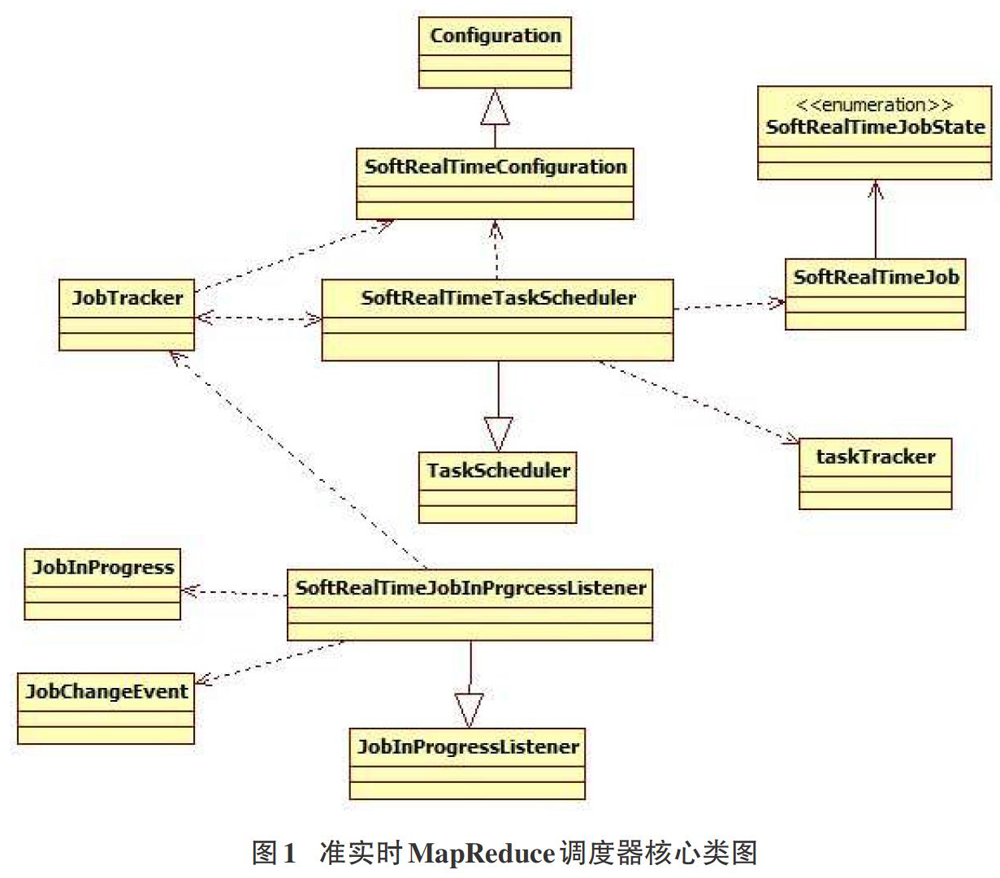
3 准实时MapReduce调度器的核心类及主要功能
准实时MapReduce调度器的核心类由SoftRealTimeConfiguration类、Soft Real Time Operation In Progress Listener类、Soft Real Time Task Scheduler类、Soft Real Time Operation类、Operation Tracker类和Operation In Progress类等组成。准实时MapReduce调度器的核心类图如图1所示,核心类及主要功能如下:
1)SoftRealTimeConfiguration类继承自org.apache.hadoop.conf.Configuration类,功能是进行配置文件管理。在Hadoop MapReduce启动加载时,SoftRealTimeConfiguration会读取配置文件中的参数,并保存至相应的数据结构中。
2)Soft Real Time Operation In Progress Listener类该类继承自org. apache. hadoop. Map red. Operation In Progress Listener类,功能是当作业添加或者删除时,通知调度器。该类包含三个主要函数:operation Added、operation Removed以及operation Updated,功能是当有作业添加到作业队列,从作业队列删除;作业的状态有更新时,该类侦听到这些事件并且执行对应的函数。
3)Soft Real Time Task Scheduler类继承自org. apache. hadoop.mapreduce. server. operationtracker. Task Tracker类,实现核心调度算法。Soft Real Time Task Scheduler类除了包含init Schedule Queue,priority Op及add Operation To Queue三个主要函数以外,还包括assign Tasks和getOperations函数。assign Tasks函数的功能是用于返回正在某个Task Tracker上执行的任务集合;getOperations函数的功能是通过作业队列的名称返回该队列中的作业。
4)Soft Real Time Operation类记录作业的状态和估计作业完成时间,并以此为依据比较正在运行的两个作业之间的优先级大小。
5)Operation Tracker类用于调度作业,其主要功能有:
1获取集群的状态,比如task tracker列表,map过程中空闲的slot任务执行器总数,reduce过程中空闲的slot任务执行器总数,当前正在运行的map/reduce 任务的总数等;
2获取QueueManager对象,通过该对象,可以获取MapReduce系统中所有作业队列的名称,以及每个队列的权限访问列表;
3停止某个作业;
4停止某个任务,用于资源抢占。
6)Operation In Progress类,当用户向Hadoop MapReduce提交一个作业后,Hadoop MapReduce会为该作业创建一个Operation In Progress的对象,该对象中包含了作业相关的基本信息,并会伴随某个作业的生命周期。该对象中包含该作业的所有任务的信息,作业的优先级,作业的提交时间,开始运行时间,运行结束时间等作业信息。
4 结论
本文提出了一种准实时MapReduce调度算法,及对作业性能的估计和任务调度的策略。在算法实验中,分别进行了估计完成时间准确率实验和性能比较实验。还对调度器估计作业完成时间的准备率与实际作业完成时间进行了对比,并将该调度器和其他三种已有的调度器进行了对比实验。实验结果表明,本算法基本达到了准实时MapReduce调度的预期目标,具有推广价值。
参考文献:
[1] 陈艳金. MapReduce模型在Hadoop平台下实现作业调度算法的研究和改进.[D].华南理工大学,2011.
[2] 张霄宏,雒芬,贾宗璞,等. 一种适用于Hadoop MapReduce环境的数据预取方法[J]. 西安电子科技大学学报,2014(2).
[3] Z. Guo,G. Fox,M. Zhou.Investigation of data locality inMapReduce[C]. Proceedings of the12th IEEE/ACM International Symposiumon Cluster, Cloud and Grid Computing,2012.
- 纳布啡对瑞芬太尼诱发患者术后痛觉过敏和寒颤的预防作用分析
- 螺内酯联合缬沙坦治疗慢性充血性心力衰竭的临床应用
- 巴曲酶与阿加曲班联合用药方案治疗急性缺血性脑卒中的临床效果及安全性评价
- 氟西汀联合奥氮平治疗伴躯体症状抑郁症的临床效果
- 达克罗宁胶浆在肛周脓肿手术喉罩全麻中的应用
- 40例支气管哮喘急性发作患者行中西医结合治疗的疗效探究
- 颅内压监测下侧脑室穿刺脑室外引流术治疗脑室内出血的临床效果
- 伊托必利、莫沙必利、多潘立酮联用黛力新治疗功能性消化不良的疗效评价
- 阿替普酶溶栓治疗急性脑梗死的临床效果
- 瑞芬太尼联合丙泊酚在无痛人流手术麻醉中的应用效果
- 轻型缺血性脑卒中发病4.5 h内患者重组组织型纤溶酶原激活剂静脉溶栓治疗的临床效果
- 创伤骨科中应用人工关节治疗技术的临床治疗效果分析
- 固定义齿修复对牙齿重度磨耗伴牙列缺损的疗效分析
- 慢性心力衰竭患者血清氨基末端脑钠肽前体和心肌肌钙蛋白I联合检测的临床意义
- 输尿管支架置入术治疗输尿管恶性梗阻伴肾功能不全的应用价值
- 美托洛尔联合曲美他嗪对冠心病心力衰竭患者炎症因子及心功能的影响
- 经尿道前列腺1 470 nm激光剜除术与钬激光剜除术治疗良性前列腺增生的疗效对比分析
- FTS理念在腹腔镜辅助全胃切除术围手术期中的应用
- 有氧运动在慢性心力衰竭患者中的应用效果
- 腹腔镜下无张力疝修补术治疗成人疝气的效果分析
- 多索茶碱和噻托溴铵粉联合治疗对慢性阻塞性肺疾病患者肺功能的影响分析
- 精准肝切除治疗肝内胆管结石的应用及有效性分析
- 持续气道正压通气对阻塞性睡眠呼吸暂停综合征患者血管内皮及纤溶系统的影响
- 早期颅骨修补术治疗脑外伤的临床效果及并发症评价
- 乌司他丁联合生长抑素治疗急性胰腺炎的效果
- shut off
- shut off/down
- shut out
- shut-out
- shuts
- shut sb in (sth) / shut yourself in (sth)
- shut sb/sth away
- shut sb/sth off (from sth)
- shut sb/sth out
- shut sb/sth up
- shut sb/sth up (in sth)
- shut sb/sth ↔ away
- shut sb/sth ↔ down
- shut sb/sth ↔ off
- shut sb/sth ↔ out
- shut (sb) up
- shut sb up
- shut sth down
- shut (sth) down
- shut sth off
- screws
- screw somebodyup
- screw somethingup
- screw (sth) up
- screws up
- 塔尖
- 塔尖上亮相——高姿态
- 塔尖上功德
- 塔尖上开天窗——好高的眼眶子
- 塔尖上点灯
- 塔尖上点灯——高明
- 塔希提岛
- 塔庙
- 塔形建筑物
- 塔形的彩灯
- 塔楼
- 塔灰
- 塔的美称
- 塔葬
- 塔西佗
- 塔里木河
- 塔里木盆地
- 塔顶
- 塔顶上挂灯笼——高明
- 塔顶上散步——无路可走
- 塔顶上迈步——没路可走
- 塔顶散步
- 塔香
- 塕
- 塗