祁步法 夏战国 崔员宁 乐珍
摘要:如今互联网迅速发展,无论何时何地,我们都可以利用网络感受大千世界的万象更新,大数据也就应运而生。我们选用Python语言编写爬虫程序对微博的数据进行抓取。由于数据存在不可供我们可视化使用的数据,我们对数据进行了一系列处理,除去了所有的脏数据。对数据进行整合以后,我们根据情感词典对数据进行了情感分析,将得出的结果导入到AdobeIllustrator中的可视化分析字体FFChartwell生成对应的可视化视图,该论文通过分析了美国大选的大数据,并将分析结果可视化呈现。
关键词:微博;大数据;可视化分析
中图分类号:TP311
文献标识码:A
文章编号:1009-3044(2017)10-0205-03
1.概述
随着科技时代的飞速发展,信息交流也越来越畅通,大数据便是人类在信息时代的产物。大数据以它独特的优势占领了各种不断发展的领域,上至天文、下至地理,以大数据处理为中心的计算技术也逐渐渗透到各个领域,它通过数据资源共享与集成的方式完成对自然的探索以及对情感的动向等分析,可以说大数据打开了人类认知新世界的大门。微博是一个基于用户关系信息分享、传播以及获取的提供微型博客服务类的社交网站,是一种通过关注机制分享简短实时信息的广播式的社交网络平台,用户可以通过WEB、WAP等各种客户端组建个人社区,以140字的文字更新信息,并实现即时分享。微博以它的便捷性与原创性收获了众多用户,由于微博话题覆盖面极广,用户可以在任意时间、任意地点记录下所看所想的内容,因此分析微博数据的重要性可见一斑,同时也为大数据的研究提供了良好的载体。
2.数据采集
(1)新浪微博AH
新浪微博开放平台类似于Twitter,平台有相关接口,可以获取用户的用户名、头像图片、当前用户的粉丝和关注对象列表等信息。利用开放的AH进行数据抓取是一种容易上手的方式。其优点是抓取的数据冗余小,数据的结构清晰,便于进一步的处理与分析,抽取数据也十分方便。
(2)Python网络爬虫
Python是一种优雅而健壮的编程语言,它继承了传统编程语言的强大.陛和通用性,同时也借鉴了简单脚本和解释语言的易用性。我们采用Python编写的网络爬虫来进行微博数据抓取。
我们针对美国大选的相关关键词进行数据抓取。
由于要抓取的内容只包括微博正文、微博作者、微博发布时间、点赞转发量等,我们在抓取的过程中通过匹配筛选以上内容并保留,去掉不相关的内容,然后将其以XML格式保存在本机上。
为了应对新浪微博的反爬虫机制,在数据抓取的过程中,我们采用控制抓取频度的方法来应对反爬机制。即控制每次抓取后空隔几秒,每抓五条后进行一次长时间的空隔,并且限制每天访问的页面量。事实证明这种方法是简单而有效的。
3.数据预处理
(1)数据整理
原始数据从服务器上抓取下来,按照关键字分类有多个文件。经过整理,得到包括关键字、博主ID、博文、发布时间、评论数等内容的9列数据,总共50243条数据。
(2)数据去噪
抓取的微博数据中,含有同一博主转发自己微博的情况,因此会出现博主与博文内容一致的数据。为了保证数据的可靠性与精确性,将数据中博文一列的重复数据进行删除,共删除数据1025条,剩余数据49218条。
(3)清除无关数据
除了重复数据,数据中还存在借热门话题进行广告宣传或发表的无关内容,这类数据在笔者进行粗略审阅之后,对博文一列利用关键词进行筛选,然后删除,关键词包括:石油、产品、促销、订购等(这些通过数据文本提炼)。共删除数据478条,剩余有效数据48740条。
(4)数据集成
将整理好的数据,按照关键字保存整理至同一文件夹以便分析。整理后数据如图1所示:
4.情感值计算
(1)概况
情感分析与研究是一项重要的工作,很多研究团队开发了文本情感分析工具,我们采用的是武汉大学沈阳教授团队开发的专门做Emotion Analysis的软件ROST EA。这款软件的机制是根据情感词典对有情感色彩的词进行选取,然后通过预先输入的公式来统计文字的情感值。
但是由于这款软件开发时间较早,而词库没有实时更新,考虑到近几年新生的热词越来越多,有很多都是用来表达内心感情的,如“点赞”、“伐开心”、“也是醉了”等等,我们决定对词库进行补充,来满足研究需要。
(2)情感词典补充
微博热词、百度热词和很多网站每年都会统计当年新兴的热词,其中有很多用来表达强烈的感情。于是我们按年份在热词中选取近四年有感情色彩地加入到新增词中。
然后我们对这些词语进行分类,分为正面词汇和负面词汇。
我们在抓取的文本中抽取出有情感倾向的词语,其中微博表情包占了相当的一部分,因此我们把微博表情罗列出来并将其分成褒贬和中性三个类型。
5.可视化分析
(1)数据可视化过程
数据可视化的部分使用Adobe Illustrate软件,通过安装专门用来做数据可视化的字体FF Chartwell Font Family实现。具体步骤如下:
1)下载并安装FF Chartwell Font Family字体,以达到不同可视化效果。
2)给代表不同数据的内容修改不同颜色,以便获得更好的可视化体验。
3)在OpenType属性窗口选择连字便可得到数据可视化的结果。
(2)数据可视化结果
经过数据可视化过程后,我们将最终的结果以可视化的图表形式展示如下:
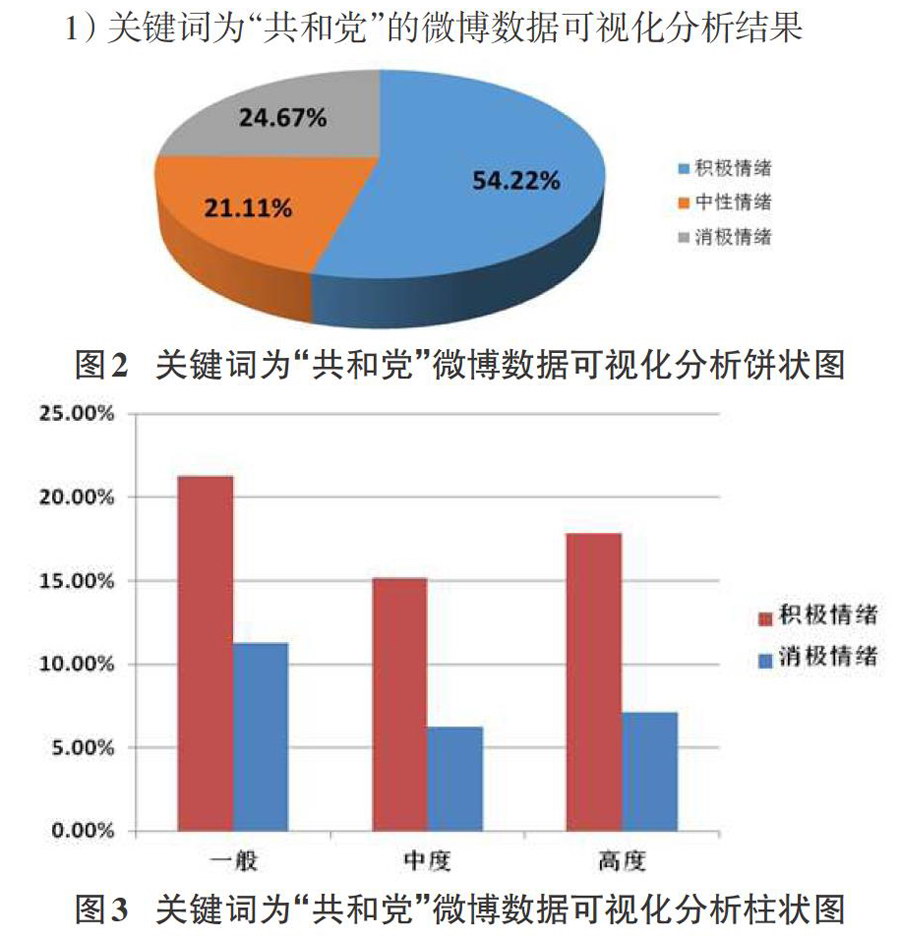
1)关键词为“共和党”的微博数据可视化分析结果
从“民主党”和“共和党”两个关键词的分析图不难看出,两党的情绪状况差别不大,微博用户对两党的支持率只有微小的差异,对于两者积极和消极情绪的程度也大致相同。总体上来说,微博用户对于民主党的支持率要略高于共和党。
3)关键词为“特朗普”的微博数据可视化分析结果
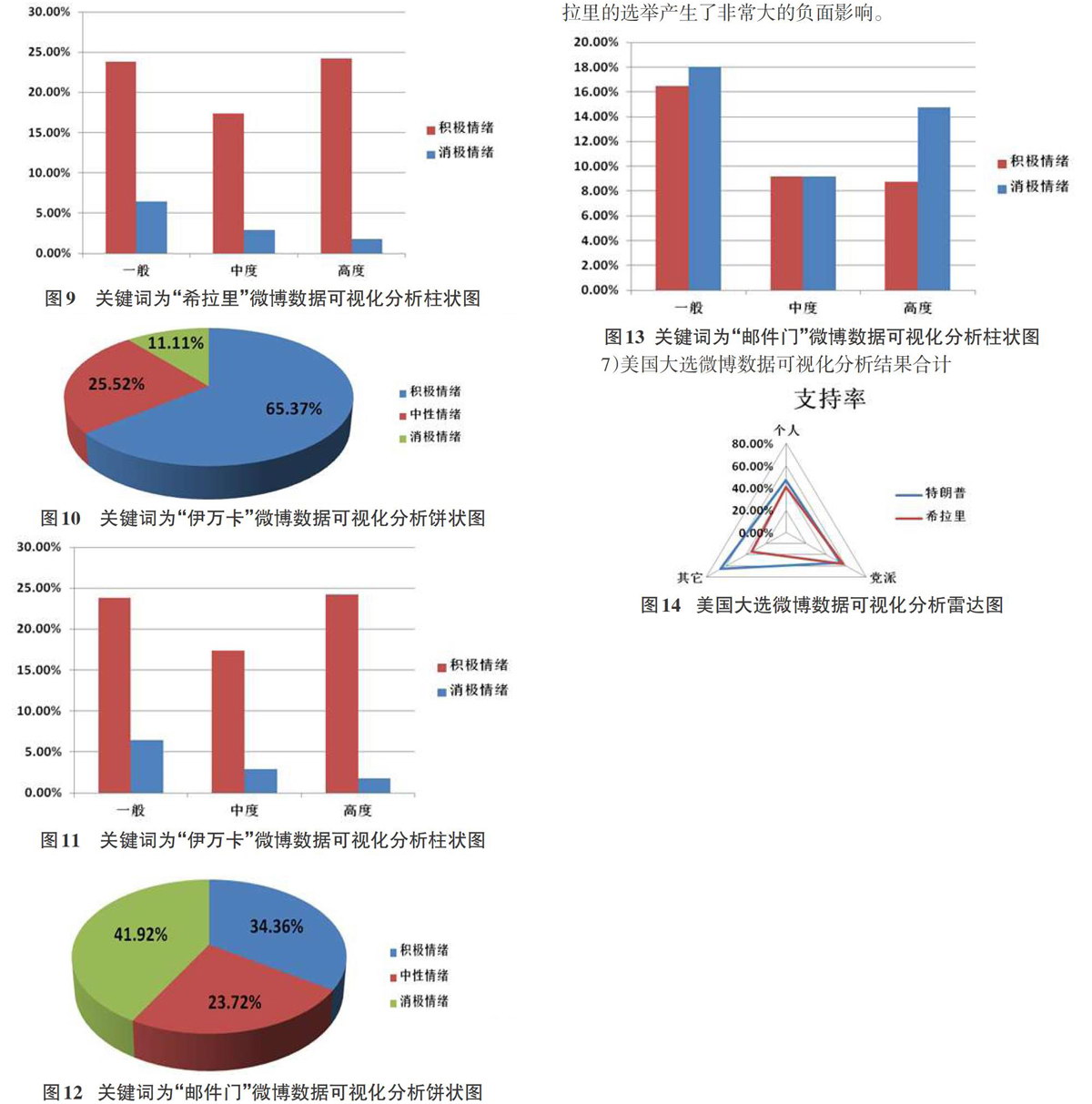
从“特朗普”和“希拉里”两个关键词的统计分析图来看,特朗普的支持率要明显高于希拉里。这里我们注意到一个很有意思的现象,微博用户对于希拉里的消极情绪趋于平和,程度都是很浅的;而反对特朗普的人消极情绪却十分高涨,可见反对特朗普的人对特朗普的厌恶程度是很深的。
5)关键词为“伊万卡”的微博数据可视化分析结果
我们从两个数据分析图中可以看出,微博用户对于伊万卡的积极情绪明显高于消极情绪,并且积极情绪的情绪程度也明显高于消极情绪。广大微博用户对于伊万卡的评价几乎是一边倒的,可见伊万卡为特朗普赢得了许多选票。
6)关键词为“邮件门”的微博数据可视化分析结果
从图12中可以推断微博用户对于邮件门事件的消极情绪要明显高于积极情绪,从图13中可以看出微博用户的高度消极情绪也是占有了相当大的比重。可以说,邮件门事件对于希拉里的选举产生了非常大的负面影响。
综合以上统计分析结果来看,特朗普的支持率要高于希拉里的支持率,其中两党本身对于选举并没有产生太大的影响,伊万卡是特朗普高支持率不可忽视的原因之一,而邮件门则是拉低希拉里支持率的重要因素。最终美国大选的结果也验证了我们的研究结论。
6.研究结果
我们通过用python所编写的爬虫抓取微博上关于美国大选的微博数据,并对这些数据进行去噪处理,通过情感计算统计出各关键词的情感数据和情感程度数据并分析建模,进行可视化处理,以直观易懂的统计分析图的形式展现出来,最终得出结论特朗普的支持率高于希拉里的支持率,而美国大选的最终结果也验证了我们这个研究。由此可推出,在一定条件下,对大数据的分析可以在一定程度上预测事件的走向及結果。
- 缬沙坦氨氯地平复方制剂治疗社区老年高血压患者的临床分析
- 诺和锐30和诺和灵30R治疗老年初诊2型糖尿病患者的疗效观察
- 改良“三明治”技术在腹主动脉腔内修复中保留髂内动脉的初步临床经验
- 关于糖尿病合并心血管病的临床治疗探析
- 托伐普坦治疗急性心肌梗死合并心力衰竭的疗效及对心肾功能的影响
- 哌拉西林-他唑巴坦与头孢哌酮-舒巴坦对冠心病老年患者手术后抗感染的临床疗效与安全性比较
- 微创针刀镜治疗难治性膝关节急性痛风性关节炎的临床疗效
- 阿托伐他汀与氯吡格雷联合应用于脑梗塞治疗中的影响评价
- 徐启春治疗胸痹心痛常用药赏析
- 肺癌患者生存质量的影响因素分析
- 左旋炔诺酮宫内缓释系统治疗围绝经期功血的临床效果观察
- 浅析中西医结合治疗原发性高血压病的优势
- 中西医结合治疗慢性阻塞性肺疾病急性加重期的临床疗效
- 中西医结合治疗糖尿病的研究进展
- 分析中医体质辨识下的中西医结合防治社区糖尿病疗效
- 酸枣仁汤加减治疗肝血不足型失眠症的疗效观察
- 半夏泻心汤联合常规三联疗法对胃溃疡的治疗效果分析
- 运用桂枝茯苓汤合黄连解毒汤治疗不稳定型心绞痛的效果观察
- 针刺放血疗法治疗急性咽炎的临床应用
- 曲美他嗪合并炙甘草汤治疗老年慢性心力衰竭合并窦性心动过缓的临床研究
- 脑卒中后睡眠障碍应用中医针灸疗法的效果观察及评价
- 补中益气汤联合舒利迭治疗支气管哮喘缓解期的临床疗效观察
- 养心汤联合穴位贴敷治疗稳定性心绞痛的临床研究
- 前列助阳中药包配合天惠牌陶瓷热灸器治疗前列腺炎及性功能障碍临床观察
- 逍遥散加减方治疗肠易激综合征52例临床体会关键思路分析
- welfare state
- welfare states
- welfaretowork
- welfare to work
- welfare-to-work
- welfarist
- we'll
- well
- well-abolished
- well-abounding
- well-absorbed
- well-accented
- well-accentuated
- well-accommodated
- well-accompanied
- well-accomplished
- well-accorded
- well-accredited
- well-accumulated
- well-accustomed
- well-achieved
- well-acquainted
- well-acquired
- well-adapted
- well-addicted
- 精细光滑
- 精细华丽
- 精细华美
- 精细周到
- 精细周密
- 精细周详
- 精细地挑选
- 精细巧妙
- 精细微小
- 精细敏捷
- 精细新颖
- 精细明察
- 精细柔软
- 精细深切
- 精细深奥
- 精细的米饭
- 精细的饭食
- 精细确凿
- 精细纤巧
- 精细美妙
- 精细考核
- 精细而敏锐
- 精细而聪明,做事干练而有成效
- 精细而聪明,廉洁而干练
- 精细而聪明,有才能和经验