刘思林

摘要:随着大数据时代的到来,信息的获取与检索尤为重要。如何在海量的数据中快速准确获取到我们需要的内容显得十分重要。通过对网络爬虫的研究和爬虫框架Scrapy的深入探索,结合Redis这种NoSQL数据库搭建分布式爬虫框架,并结合Django框架搭建搜索引擎网站,将从知乎,拉钩,伯乐等网站抓取的有效信息存入ElasticSearch搜索引擎中,供用户搜索获取。研究结果表明分布式网络爬虫比单机网络爬虫效率更高,内容也更丰富准确。
关键词:网络爬虫;Scrapy;分布式;Scrapy-Redis;Django;ElasticSearch
中图分类号:TP311? ? ?文献标识码:A? ? ?文章编号:1009-3044(2018)34-0186-03
1 引言
爬虫的应用领域非常广泛,目前利用爬虫技术市面上已经存在了比较成熟的搜索引擎产品,如百度,谷歌以及其他垂直领域搜索引擎,这些都是非直接目的的;还有一些推荐引擎,如今日头条,可以定向给用户推荐相关新闻;爬虫还可以用来作为机器学习的数据样本。
论文研究的主要目的是更加透彻的理解爬虫的相关知识;在熟练运用Python语言的基础上,更加深入的掌握开源的爬虫框架Scrapy,为后续其他与爬虫相关的业务奠定理论基础和数据基础;进一步理解分布式的概念,为大数据的相关研究和硬件条件奠定基础;熟练理解python搭建网站的框架Django,深入理解基于Lucene的搜索服务器ElasticSearch,最终在上述基本知识的基础上,搭建出一个简易版本的搜索引擎,实现从网络上爬取数据,存储到分布式的Redis数据库,并最终通过Django和ElasticSearch,实现搜索展现的目的。
2 爬虫基本原理
网络爬虫是一种按照一定规则,自动抓取万维网信息的程序或者脚本。如果把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)。爬虫指的是,向网站发起请求,获取资源后分析并提取有用数据的程序。
从技术层面来说就是通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码,JSON数据,二进制数据(图片、视频)等爬到本地,进而提取自己需要的数据,存放起来供后期使用。
3 Scrapy-Redis分布式爬虫
3.1 Scrapy
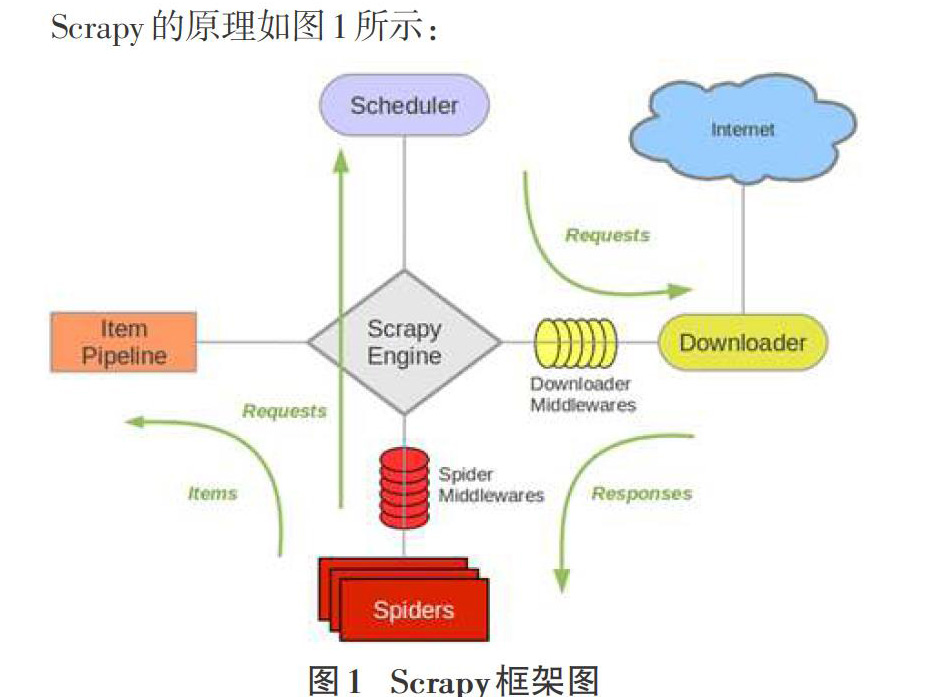
Scrapy的原理如图1所示:
各个组件的解释如下:Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等,相当于人的大脑中枢,机器的发动机等,具有显著的作用。Scheduler(调度器):负责接收引擎发送过来的Request请求,并按照一定的方式逻辑进行整理排列,入队,当引擎需要时,再交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。Spider(爬虫):负责处理所有的Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。Item Pipeline(管道):负责处理Spider中获取到的Item,并进行后期处理(详细分析、过滤、存储等)。Downloader Middlewares(下载中间件):可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):可以理解为是一个可以自定义扩展和操作引擎以及Spider中间通信的功能组件(例如进入Spider的Responses;和从Spider出去的Requests)。
整个Scrapy爬虫框架执行流程可以理解为:爬虫启动的时候就会从start_urls提取每一个url,然后封装成请求,交给engine,engine交给调度器入队列,调度器入队列去重处理后再交给下载器去下载,下载返回的响应文件交给parse方法来处理,parse方法可以直接调用xpath方法提取数据了。
3.2 Redis
Redis 是完全开源免费的,遵守BSD协议的,高性能的key-value数据库。Redis 与其他key - value 缓存产品有以下三个特点:(1)Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。这样可以防止数据的丢失,在实际生产应用中数据的完整性是必须保证的。(2)Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。这些功能更强大的数据存储方式极大地节约了存储空间,优化了查询的性能,大大提高了查询效率。存储的目的是为了后期更好的取出,Redis很好地做到了这一点。(3)Redis支持数据的备份,即master-slave模式的数据备份。主从结构目前是大数据里面的主流结构,主从模式能保证数据的健壮性和高可用。当出现电脑宕机,硬盘损坏等重大自然原因时,主从模式能很好的保证存储的数据不丢失,随时恢复到可用状态。正是考虑到Redis的以上强大特点,才选择Redis作为分布式存储的数据库。
4 Django搭建搜索网站
Django是一个开放源代码的Web应用框架,由Python开发的基于MVC构造的框架。在Django中,控制器接受用户输入的部分由框架自行处理,因此更加关注模型,模板和视图,即MVT。模型(Model),即数据存取层,处理与数据相关的所有事物:包括如何存取,如何验证有效性,数据之间的关系等。视图(View),即表现层,处理与表现相关的逻辑,主要是显示的问题。模板(Template),即业务逻辑层,主要职责是存取模型以及调取恰当模板的相关逻辑。控制器部分,由Django框架的URLconf来实现,而URLconf机制恰恰又是使用正则表达式匹配URL,然后调用合适的函數。因此只需要写很少量的代码,只需关注业务逻辑部分,大大提高了开发的效率。使用Django搭建搜索引擎的界面,简单便捷且界面交互效果良好,适应需求,无须成本。
5 ElasticSearch搜索引擎
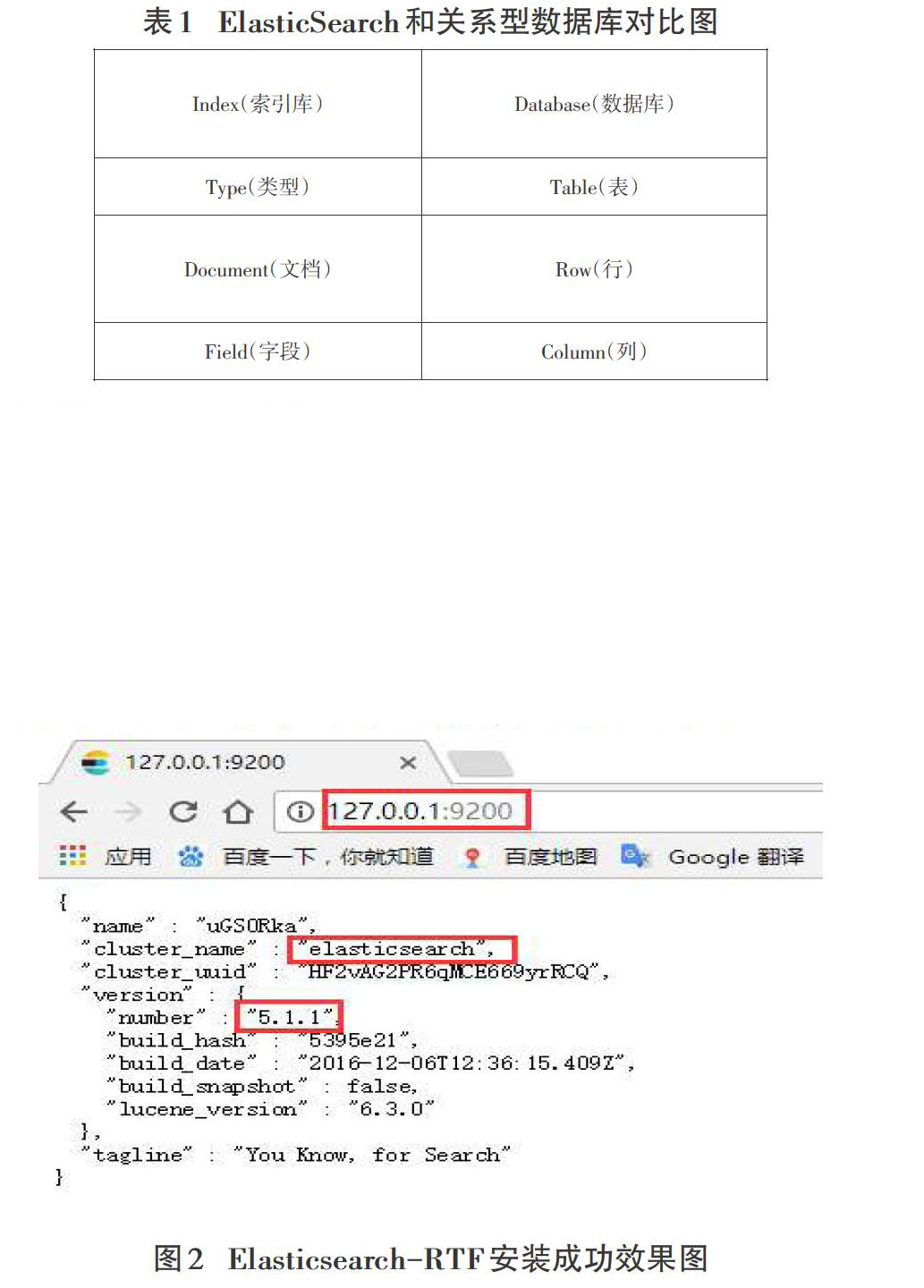
ElasticSearch是一个基于Lucene的实时的分布式搜索和分析引擎,设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用非常方便。基于RESTful接口。ElasticSearch具有广泛的用户,如DELL,GitHub,Wikipedia等。ElasticSearch和关系型数据库之间的对比如表1所示:
5.1 Elasticsearch-RTF
RTF是Ready To Fly的缩写,在航模里面,表示无需组装零件即可直接上手即飞的航空模型。Elasticsearch-RTF是针对中文的一个发行版,即使用最新稳定的Elasticsearch版本,并且下载测试好对应的插件,如中文分词插件等,目的是可以下载下来就可以直接的使用。项目构建过程中选择的是Elasticsearch-RTF 5.1.1版本。安装后启动,效果如图2所示:
5.2 Elasticsearch-head
ElasticSearch-head是一个Web前端插件,用于浏览ElasticSearch集群并与之进行交互,它可以作为ElasticSearch插件运行,一般首选这种方式,当然它也可以作为独立的Web应用程序运行。它的通用工具有三大操作:ClusterOverview,显示当前集群的拓扑,并允许执行索引和节点级别的操作;有几个搜索接口可以查询原生Json或表格格式的检索结果;显示集群状态的几个快速访问选项卡;一个允许任意调用RESTful API的输入部分。
5.3 Kibana
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等。kibana能够很轻易地展示高级数据分析与可视化。Kibana使理解大量数据变得容易。它简单、基于浏览器的接口能快速创建和分享实时展现Elasticsearch查询变化的动态仪表盘。Kibana启动完成后,可看到插入数据和页面查询显示结果如图3所示:
6 结论
通过对爬虫理论的相关理解,将互联网上海量的信息按需要加以分类和存储,并最终展示给特定用户的特定领域需求的信息,避免网上海量信息的视觉冲击,从而达到准确,高效检索的目的。利用Python语言以及其丰富的知识库,结合开源的Scrapy爬蟲框架,能够高效的将网上海量的信息爬取下来,并利用Redis分布式数据库的特点,将数据安全,快速的存入,方便后期的获取与检索,使用开源的Django框架搭建搜索引擎网站,提供灵活便捷的可视化操作界面,方便广大用户的使用,结合ElasticSearch强大的搜索功能,将所有组件结合到一起,完成搜索引擎的全部功能,最终达到搜索的目的。
参考文献:
[1] 郭一峰.分布式在线图书爬虫系统的设计与实现[D].北京交通大学,2016.
[2] 王敏.分布式网络爬虫的研究与实现[D].东南大学,2017.
[3] 胡庆宝,姜晓巍,石京燕,程耀东,梁翠萍.基于Elasticsearch的实时集群日志采集和分析系统实现[J].科研信息化技术与应用,2016,7.
[4] 曾亚飞.基于Elasticsearch的分布式智能搜索引擎的研究与实现[D].重庆大学,2016.
[5] 姚经纬,杨福军.Redis分布式缓存技术在Hadoop平台上的应用[J].计算机技术与发展,2017,27(6):146-150+155.
[6] 马联帅.基于Scrapy的分布式网络新闻抓取系统设计与实现[D].西安电子科技大学,2015.
[7] 吴霖.分布式微信公众平台爬虫系统的研究与应用[D].南华大学,2015.
[8] 李春生.基于WEB信息采集的分布式网络爬虫搜索引擎的研究[D].吉林大学,2009.
【通联编辑:梁书】
- 建党前中国化马克思主义的重大理论成果
- 恽代英独立探索建党的理论与实践
- 把中国介绍给世界是我们神圣的使命
- 略论马克思主义在中国早期传播的三个问题
- 赓续传统让“初心”变为“恒心”
- “十个全覆盖”工程的出发点和落脚点在于覆盖民心
- 站在新时代之巅 为马克思主义鼓与呼
- 区域型高校农村教育智库的建设研究
- 走过千山万水,仍需跋山涉水
- 传统理性主义的现代性指向
- 历史视阈下思潮与社会思潮的比较辨析、历史进程与当代规谏
- 论新形势下的党性修养
- 高考应该超越“恢复”的水平
- 早期传播唯物史观的经典:《唯物史观解说》
- 我的初心:为消贫鼓与呼
- 让理想之花永远绽放
- 高等教育区域协调发展与政府理性决策
- 党员干部要守住赤子之心
- 初心使命让中国共产党永远年轻
- 浅析警务效能建设的难点、成因及对策
- 初心与新时代的中国共产党
- 马克思实践论生成性思维方式与科学决策
- 走得再远也不能忘记为什么出发
- 党员领导干部要敢担当、善作为
- 百年未有之大变局下的党性教育
- unrecollective
- unrecompensable
- unreconcilable
- unreconciling
- unreconsidered
- unrecounted
- unrecoupable
- unrecoverable
- unrecovered
- unrecreational
- unrecruitable
- unrecruited
- unrecuperated
- unrecuring
- unrecurrent
- unrecurrently
- unrecyclable
- unrecycled
- unredeemed
- unreefed
- unreferred
- unrefilled
- unrefining
- unreformable
- unreformative
- 人有百巧,天有千变
- 人有百算,天有一算
- 人有眼力,善于识别人才
- 人有能力,能做各种事情
- 人有脸,树有皮
- 人有脸,树有皮(人活脸,树活皮)
- 人有脸,树有皮,不争名誉也要争口气
- 人有良心,狗不吃屎
- 人有薄技不受欺
- 人有见面之情
- 人有贵子
- 人有贵贱,不可概论
- 人有道理,马有缰绳
- 人有错漏,马有失蹄
- 人有隔宿之智
- 人有霎时一身银
- 人有骨气,刚正坚贞
- 人有骨气,坚贞不屈
- 人望
- 人望人好,阎王望鬼好
- 人望人好,阎王望鬼好。
- 人望幸福树望春
- 人望幸福树望春,日望太阳夜望灯
- 人望所归
- 人望高头,水往低流