许冠军 高昌盛

摘要:智能水表技术解决了用水数据获取实时性的问题,但新的获取用水量数据技术,在统计准确性上不如传统方法。为定位智能水表系统的可能错误数据,该文提出了基于历史数据的误差定位方法,可以有效发现疑似误差数据。
关键词:校验;智能水表;历史数据
中图分类号:G642? ? ? ? 文献标识码:A? ? ? ? 文章编号:1009-3044(2018)34-0193-03
1 引言
水务公司为便于分析区域用水情况和布局合理的管网等需求,对居民用水数据的实时性和准确性要求越来越高。智能水表技术有效地解决了获取用水数据实时性的问题,但无论是超声波智能水表还是基于图像识别的智能抄表系统,都存在较大比例的读数误差。误差数据的存在,尤其是明显的居民用水数据错误,会引起客户的投诉,造成客户和水务公司对系统数据的不信任,严重影响智能水表系统的进一步推广。
为提高用水量数据的准确性,应在初次统计的数据中,尽可能发现可能的误差数据,结合系统重读、人工筛查和智能预测等方法进行及时纠正。本文提出了基于历史数据的居民用水量数据校验和分析方法,具体实现步骤:(1)结合区域居民的历史用水数据,对居民的用水特点进行分类,形成不同类型的居民用水类型[1-2];(2)结合一年四季的用水差别,利用已分类的用户类型,拟合出各类型的年度月平均用水变化曲线[3];(3)结合区域用户的年度月平均用水曲线,得出月际用水量的变化幅度[4-5]。结合用户的历史用水数据,对当月的系统读数的进行合理性识别,并确定疑似误差数据。
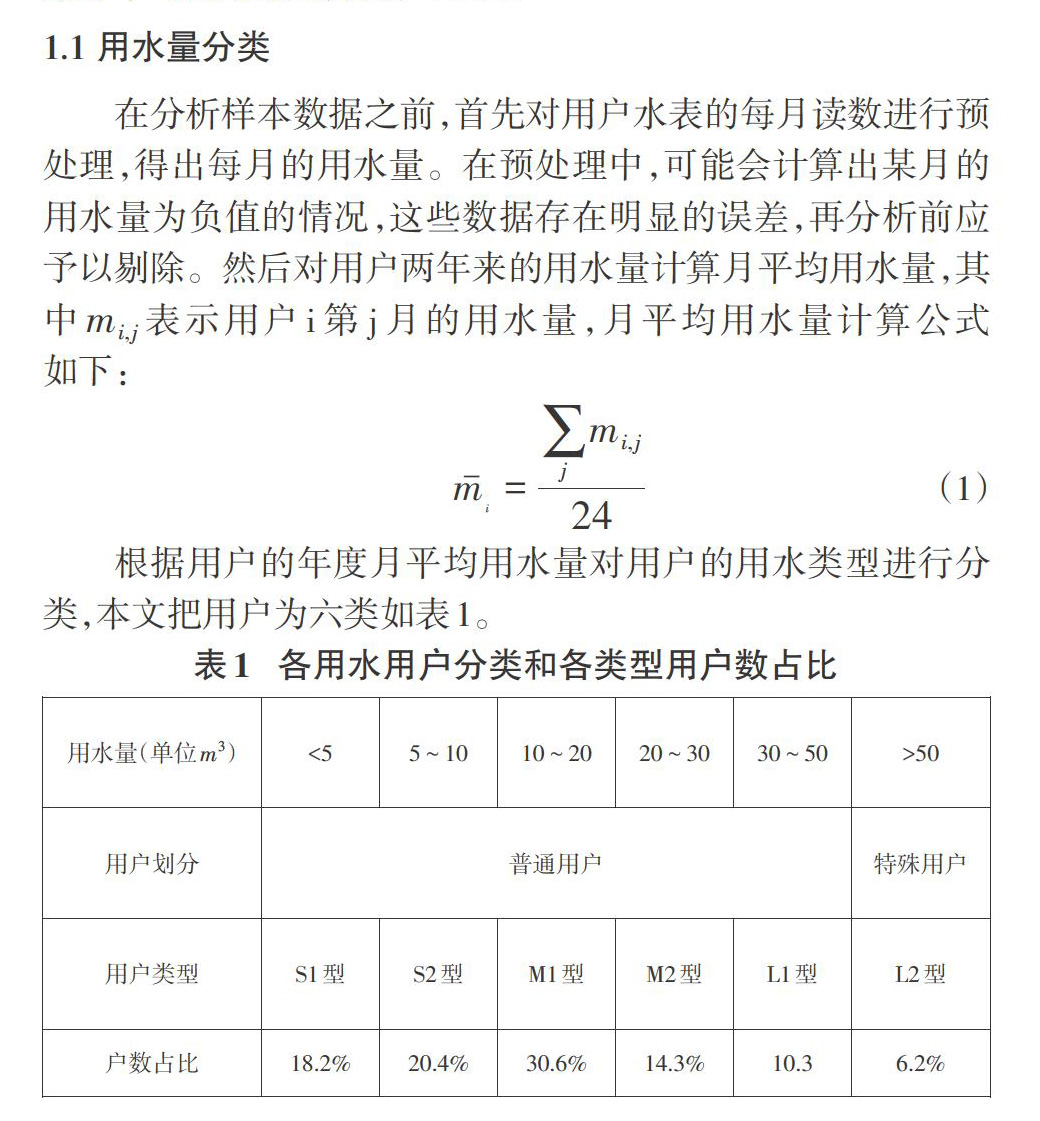
2 用水模式分析
本文对某市区的近万户居民连续两年用水历史数据进行分析,在用户类型划分和用水模式分析中,月平均用水量和用水时间波动性是最受关注的两个因素。经过初步的数据分析发现,月平均用水量能较好地区分用户的类别,因此,本文先利用月平均用水量划分用户类型。
3 数值实验
本文的實验数据来自基于图像识别的自动抄表系统,一般情况下该系统的读数自动识别正确率能达到95%,发现剩余5%的错误数据,是本文算法要解决的主要问题。
3.1 实验分析
实验中,对非样本的生产数据进行直接验证,本文算法与传统的直接基于上月数据校验算法进行比较。实验结果对正常数据误判率(把正常的数据标识成疑似误差数据的比例)、错误数据识别率(正确识别误差数据的比例)二组结果记录如表4。
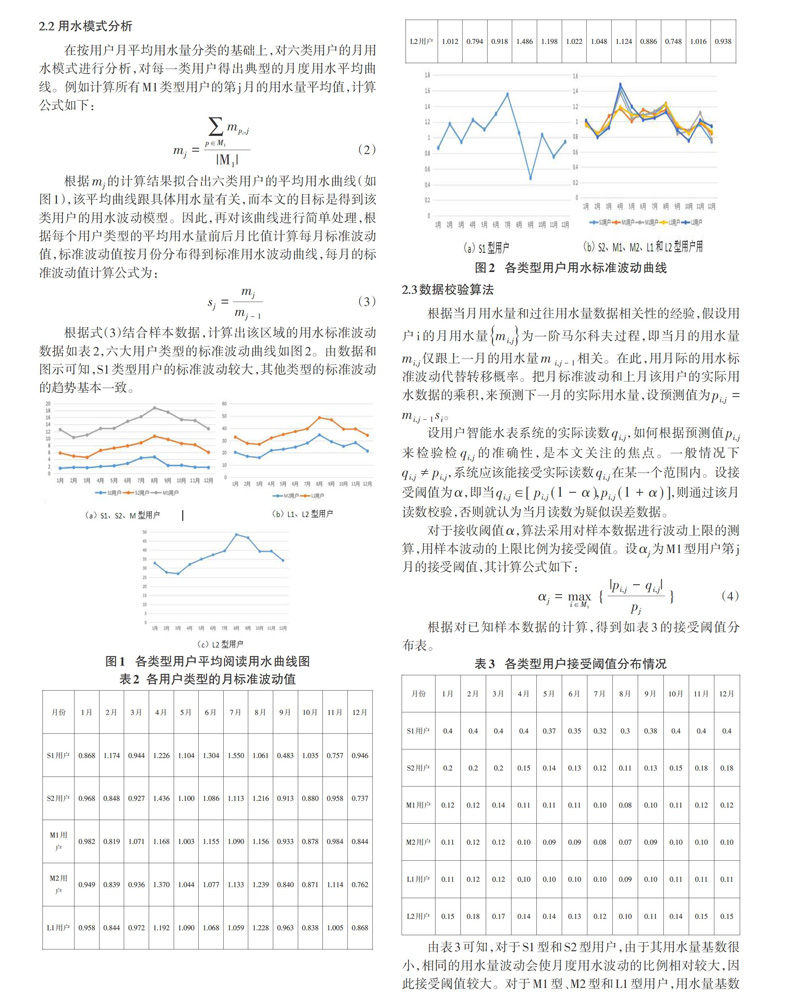
由表4的实验结果可以发现,和传统算法相比较,本文算法引入了用水量随季节变化的用水模式因素,降低了正常数据的误判率,且提高了错误数据的识别率。
3.2 算法分析
传统的直接和上月用水量进行比较的计算方法相对简单,可以粗略判断数据的合法性,但由于没有结合用水量随季节变化的因素,在季节交替月份的检验效果较差。本文提出的算法,弥补了传统算法的缺点,但相对计算量较大,具体特点如下:
1)算法依赖于往期数据的完整性。若对于不完备的用水数据或数据质量不高的情形,可以先应用传统方法进行数据积累,当数据量积累到1年以上时,便可应用算法。
2)区分用户类型的目标是对有相同用水模式的用户进行分类,本文的用户分类仅根据年度月平均用水量,相对比较粗糙,有待进一步改进。但无论何种分类方法,用水模式会随地域和时间变化而变化,此类算法需要定期更新区域用户用水模式数据。
3)模型只假设当月用水数据只和上月数据相关,若能考虑更多月份的用水数据和往年同期用水数据,可能会使模型更加完善。
4 小结
本文设计的用水量校验算法是抄表系统的一个重要的辅助模块,在系统实现中,增加了当月待核实数据的预测区间,用于抄表员及时发现疑似错误数据。由表4可知,该算法正常数据误判率在7%和11%之间,错误数据的识别率介于86%和90%之间,取得了相对满意的校验效果。进一步优化用户分类方法,形成更为精确的用水模式,将是以后的研究方向。
参考文献:
[1] 王保义,胡恒,张少敏. 差分隐私保护下面向海量用户的用电数据聚类分析[J]. 电力系统自动化, 2018,42(2):121-127.
[2] 刘春霞,王琰,沈磊,等. 城市典型用户四季用水模式变化规律的确定及分析[J]. 供水技术, 2015,9(4):49-52.
[3] 赵太飞,谷伟豪,段延峰. 农村居民用水行为的识别方法[J].水资源与水工程学报, 2016,27(4):70-74.
[4] 屈晓渊,张永恒,张锋,等. 矿区水环境数据预测模型研究[J]. 电子设计工程, 2016,24(10):45-48.
[5] 陈佳袁,闫杰. 基于ARMA模型的水文数据预测[J]. 浙江水利科技,2017(6):27-30.
【通联编辑:王力】
- 基于ERM框架的会计师事务所风险管理研究
- 中小型水库安全运行管理要点的相关研究
- 行政事业单位资金管理的困境及对策
- 绿色价值链下的钢铁企业成本控制研究
- 工程总承包施工安全管理问题探析
- 国有企业固定资产管理内控机制的构建及完善
- 我国星级酒店管理中酒店营销存在的问题及解决措施初探
- 关于煤矿企业安全成本核算的研究
- 浅析施工企业的索赔管理
- 如何实现集团性企业政工工作与企业管理的共同发展
- 网络经济时代如何优化事业单位人力资源管理
- 上市公司的内部控制对现金流管理的影响研究
- 企业人力资源管理对人事档案管理工作的新要求
- 大数据背景下管理会计新探讨
- “十四五”期间中小企业人力资源管理优化路径
- 企业管理标准化对于企业管理的重要意义
- 温控式电加热新型无涂层不粘锅的设计与研究
- F1600泥浆泵下导板与十字头间隙超差问题的分析
- 烟箱缺条金属检测装置
- 自动焊接技术在工业机械中的应用
- 自动识别技术在智能冰箱中的应用
- 双创平台运营绩效评价研究
- 智慧政府视角下四川省移动政务平台服务能力现状研究
- 我国数字货币监管对策研究
- 信息安全技术应用人才校企联合培养模式探索
- laurelling
- laurels
- lava
- lavalike
- lavas
- lavatories
- lavatory
- lavender
- lavendered
- lavendering
- lavenders
- lavender-water
- lavish
- lavished
- lavisher
- lavishers
- lavishes
- lavishest
- lavishing
- lavishingly
- lavishly
- lavishness
- lavishnesses
- lavish sth on
- lavish sth on sb
- 东吴招亲
- 东吴招亲——上当一回
- 东吴招亲——弄假成真
- 东吴招亲(乐吴招亲)——弄假成真
- 东吴杀人
- 东吴杀人——嫁祸于曹
- 东吹西倒,西吹东倒
- 东周
- 东周列国志
- 东周梦
- 东哥特王国
- 东嘉
- 东园桃李花,早发还先萎; 迟迟涧畔松,郁郁含晚翠
- 东园梓棺
- 东园秘器
- 东圊
- 东土文字
- 东土齐州
- 东场搬到西场,也要三日饭粮
- 东坡全集
- 东坡居士
- 东坡巾
- 东坡纸
- 东坡肉
- 东坡肘子