房梦婷 陈中举
摘要:为提高图像识别的准确率,提出了一种基于卷积神经网络的图像识别模型。本实验使用Python编程语言实现模型的训练与测试。对图像数据集cifar-10进行预处理后,使用Python中的Keras框架进行模型的构建与训练,模型训练完毕后,对识别准确率进行评估,最后对测试集中的图片进行识别,获得预测准确率和混淆矩阵。通过增加卷积运算的次数,提高图像识别的准确率。
关键词:卷积神经网络;图像识别;Python;Keras
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)10-0190-03
1概述
卷积神经网络,简称CNN,是多层神经网络模型的一个变种,受到生物学的启发,卷积神经网络在图像领域得到了广泛的应用。最早的神经网络模型是1998年由LeCun等人提出的LeNet5m,它以交替出现的卷积层和池化层作为基础的主干网络,结合全连接层组成完整的网络结构。在2012年,Krizhevsky等人设计了AlexNetN网络,它的主干网络包含了五个卷积层,全连接层增加到三个,并且将传统的激活函数替换成ReLU函数。2013年,MinLin在NetworkinNetworkN中首次明确提出了在进行卷积运算的时候使用1Xl的卷积核。2014年,Szegedv等人提出了并行卷积的Inception模块。2015年,HeK等人提出了使用两个3x3的卷积核代替原来的5x5的卷积核的MSRA-Net[S],使网络的性能得到非常大的提升。同年,HeK等人提出的RestNet网络,进一步提升了网络性能。 2相关技术
2.1Keras框架
Keras是一个使用Python编写的模型级的高级深度学习程序库,只处理模型的建立、训练和预测等,使用最少的程序代码、花费最少的时间建立深度学习模型。对于深度学习底层的运算(如张量运算),使用的是“后端引擎”。目前Keras提供了两种后端引擎:TensorFlow与Theano。同Keras相比,单独使用TensorFlow这样低级的链接库虽然可以完全控制各种深度学习模型的细节,但是需要编写更多的程序代码,花费更多时间进行开发。
2.2卷积神经网络
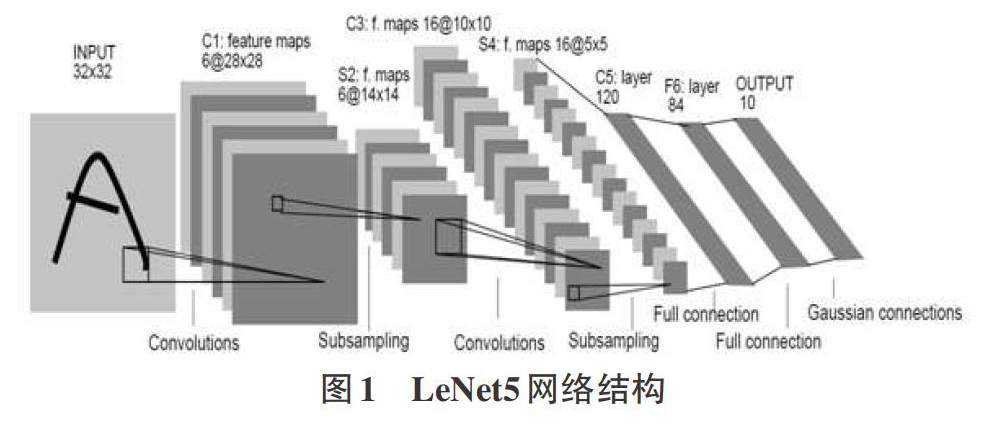
卷积神经网络是一种在监督学习下的多层网络模型,由多个卷积层和池化层(有时也统称卷积层)交替连接而成。最经典的卷积神经网络模型是LeNet5模型,它由YannLeCun设计,基本的操作包括:卷积运算和池化运算。其具体的网络结构如图1所示:
2.2.1卷积运算
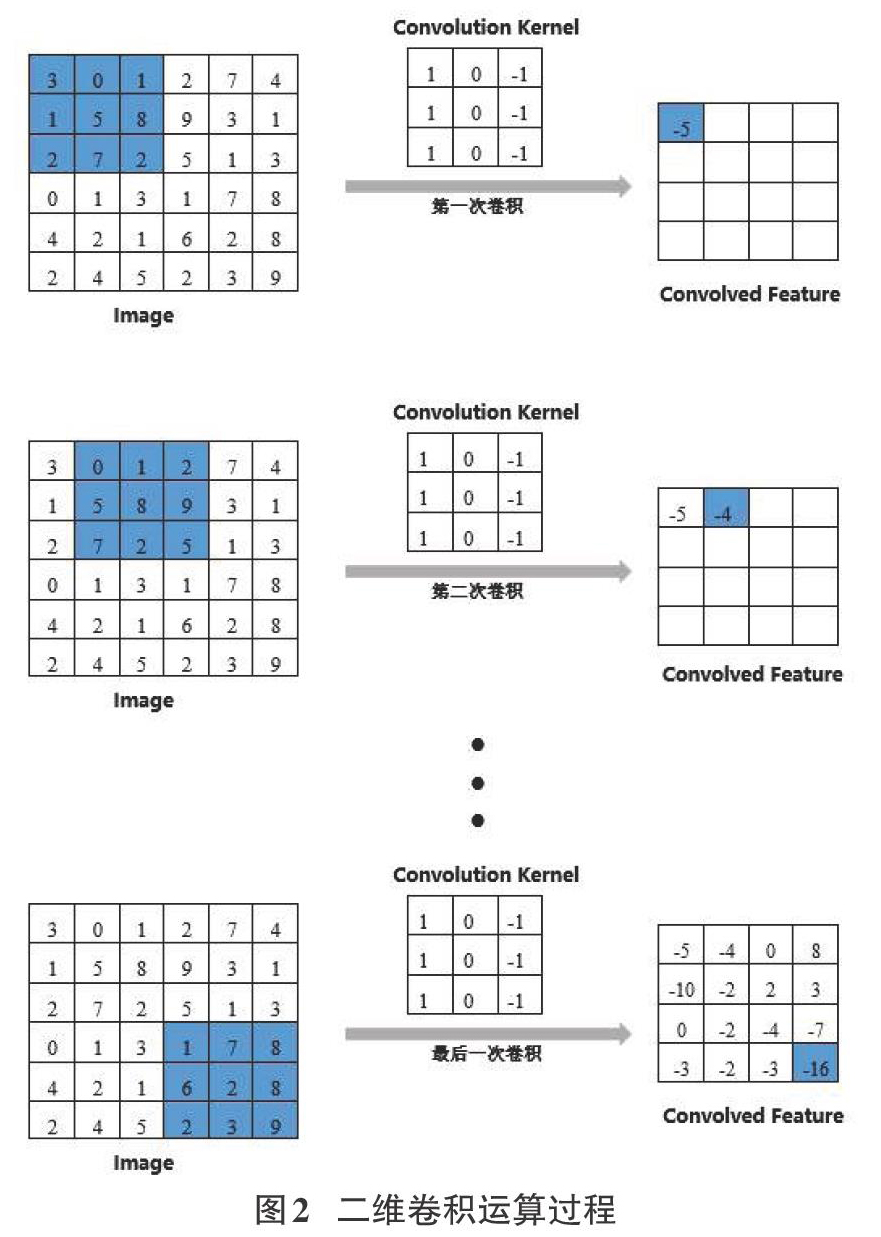
卷积层的意义是将原本一个图像经过卷积运算产生多个图像,每一个图像保有原图像的一些特征,卷积运算的效果很类似滤镜的效果,用于提取不同的特征。卷积运算的过程如图2所示:
在图3所示过程中,输入图片的大小为6×6,卷积核的大小为3×3,首先选取图片左上角一个3×3的矩阵(蓝色区域)与卷积核进行运算。运算的过程是:被选区域与卷积核对应位置元素相乘,得到一个3×3的矩阵,再将该矩阵中的所有元素相加,得到第一个卷积特征,即3×1+0×0+1×(-1)+1×1+5×0+8×(-1)+2×1+7×0+2×(-1)=-5。然后蓝色被选区域向右移动一个步长(在这里步长为1),利用新得到的矩阵继续跟卷积核做卷积运算,同样是先乘后加,得到对应位置的卷积特征-4。接下来蓝色被选区域按照从左到右、从上到下的顺序,依次遍历整个图片,得到图片卷积之后的所有特征值,是一个4×4的矩阵。在实验过程中,通常利用多个不同的卷积核来处理图片,从而提取出不同的特征。
从上面的卷积过程可以看出,通过卷积运算,图片大小由原来的6×6,缩小为4×4,若进行多次的卷积,图片一直缩小,会使得图片的边缘特征被忽略掉。要使得卷积过程中图片的大小不变,保留图片更多的特征,需要在图片外面进行填充,通常是填充0。
2.2.2池化运算
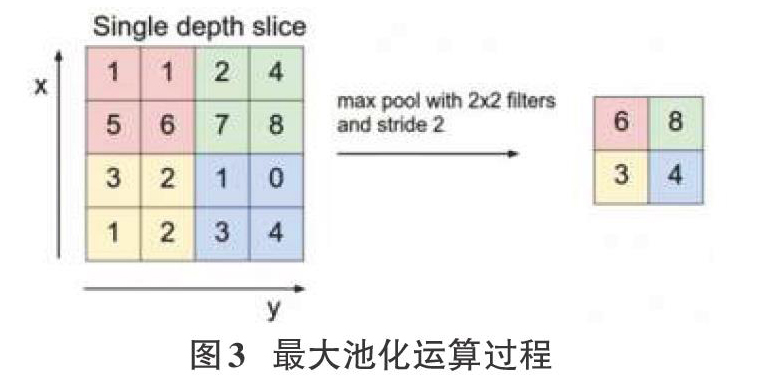
池化层(也称下采样层)意义是用一个特征来表达一个局部的特征,池化运算就是对图像进行缩减采样。池化运算中最常用的是最大池化,就是只取指定区域中的最大值,另外还有平均池化,k最大池化等。其中,最大池化运算的过程如图3所示,原本4×4的图像经过池化运算后,图像的大小变为2×2:
通过池化运算减少了需要处理的数据点,节省了后续运算所需的时间。同时也让参数的数量和计算量有所下降,这在一定程度上也控制了过度拟合。
3卷积神经网络的图像识别实验
3.1数据源
本实验使用cifar-lO图像识别数据集作为实验数据,该数据集中共有60000张彩色图片,图片大小为32×32,由两部分组成,一部分是训练图片共50000张,一部分是测试图片共10000张。该数据集中包含了10类事物,分别为:airplane,auto-mobile,bird,cat,deer,dog,frog,horse,ship,truck,每个分类有6000张图片。
3.2实验过程
本实验使用Pvthon的Keras框架来完成图像识别模型的设计,为比较不同卷积层数对识别准确率的影响,需要不断加深模型的卷积层数。具体流程如图4所示:
4实验结果
4.1训练结果
在模型训练阶段,将50000条训练数据按照8:2的比例随机分为训练数据和验证数据,设置损失函数的参数为categori-cal_crossentropy,优化器为adam,评估模型的方法为准确率,训练周期为15,batch_size设为128。模型一为只有两个卷积层的浅层神经网络,模型二将卷积层增加到了六层。为了防止模型出现过拟合的情况,在建模的过程中适当添加Dropout函数放弃部分神经元。训练过程中的准确率执行结果如图5所示。
如果训练准确率一直增加,验证准确率没有增加,可能是出现了过拟合的现象。比较两个模型,可以发现对过拟合程度控制更好的是模型二。
4.2测试结果
使用测试数据集,对两个模型预测的准确率进行评估,最终模型一的准确率为0.7384,模型二的准确率为0.8062。可以看出,模型二预测的准确率要高于模型一。
4.3效果展示
如图7是模型二对图片预测效果的展示。
5总结
为完成图像识别任务,本文利用Pvthon中的Keras框架,通过少量的代码完成了卷积神经网络模型的构建。通过不断加深网络的深度,得出如下结论,针对特定数据集,通过适当增加卷积层的数量可以有效地提高图像识别的准确率。由于实验机器的计算能力有限,实验数据量太小,本次实验构建的卷积神经网络的结构并不大。下一步的研究可以在改变參数设置、更换实验环境、使用更加庞大的数据集等方面进行展开,更加深入的学习和利用卷积神经网络。
- “银医通”项目在三甲医院中的效益评价
- 我国城市治理的新模式探索
- 做好新时代办公室工作的几点思考
- 论做好物资采购工作的重要性
- 浅析土壤污染原因及治理举措
- 论加快医保支付方式改革的对策
- 浅析高校学生营养搭配均衡存在的问题及对策
- 浅议企业干部人事档案管理工作的问题及对策
- 深化“放管服”改革推进实体政务大厅与网上服务平台有机结合
- 论新乡黄河湾旅游区资源特色与发展战略
- 第三方物流企业发展现状及对策分析
- 文化创意产业与现代制造业融合发展研究
- 借势雄安建设推进保定市养老产业高效发展
- 资产收益权为信托财产合法性分析
- “两权”抵押融资的发展困境与建议
- 影子银行对小微企业融资的影响分析
- 公司银行业务转型发展研究
- 浅析我国绿色金融发展的问题及对策
- 浅析大数据金融的应用与挑战
- 探讨加强煤矿企业经济管理的有效措施
- 我国风力发电企业的融资问题探讨
- PPP项目招投标阶段风险分担策略探析
- 金融及证券领域的应用统计学研究
- 新形势下国贸专业课程体系改革措施研究
- 浅析数据库课程的学以致用
- enclaves
- enclaving
- enclosable
- enclose
- enclosed
- encloser
- enclosers
- encloses
- enclosing
- enclosure
- enclosures
- encodable
- encode
- encoded
- encodement
- encodements
- encoder's
- encoders
- encodes
- encoding
- encompass
- encompassed
- encompasses
- encompassing
- encompassment
- 不二色
- 不二门
- 不亏
- 不亏不崩
- 不亚于
- 不亡何待
- 不亢不卑
- 不交往
- 不亦
- 不亦……乎
- 不亦乐乎
- 不亨不哈
- 不亲自调查了解,轻信传言
- 不亲近
- 不人物
- 不人虎穴, 不得虎子。
- 不人道
- 不仁
- 不仁不义
- 不仁之器
- 不仁起富
- 不仅
- 不仅不但
- 不仅是这样,不仅如此
- 不仅自己错了,而且还贻误别人