李婧文 朱毅
摘要:随着互联网技术的发展与进步,网络技术已经渗透到人们生活的各方各面。借助于网络平台,网络招聘以其高效便捷、范围广、无地域限制等优点,逐渐超越人才招聘会等传统招聘方式,成为现今求职的首要渠道。该文以北京市python开发工程师这一职位的需求量为例,运用时间序列预测模型(ARIMA模型),对未来该职位需求量进行预测,利用创新型招聘技术提高求职效率、提升网络招聘的服务质量。
关键词:网络招聘;时间序列;预测
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2020)15-0022-02
1引言
中国劳动人口众多,就业形势日趋严峻,网络招聘和求职没有时间、地域的限制,节省了时间、精力和费用,越来越受到广大求职者的青睐。对于高校毕业生来讲,选择一个前景广阔的行业十分重要,目前网络招聘信息繁杂,而且相当多的招聘网站提供的是网络中介服务,功能过于单一,用户满意度不高,跟不上市场需求的变化。因此为求职者提供直观数据,是现今网络招聘服务网站的发展目标。
2原理与统计方法
2.1 ARIMA模型的基本原理
ARIMA模型的全称叫作自回归移动平均模型,是统计模型中最常见的一种用来进行时间序列预测的模型,是由博克思(Box)、詹金斯(Jenkins)于20世纪70年代初提出的著名时间序列预测模型,又称为Box-Jenk ins模型。其中AR是自回归,p为自回归项;MA为移动平均,q为移动平均项数,d为时间序列成为平稳时间序列时所做的差分次数。ARIMA(p d,q)模型的实质就是差分运算与ARMA(p,q)模型的组合,即ARMA(p,q)模型经d次差分后,即为ARIMA(p,d,q)模型。
2.2数据获取与统计方法
以“北京市python开发工程师”的职位为例,分别对智联招聘、百度招聘等招聘网站中该职位的招聘信息进行调查。选取2018年4月~2018年10月的数据,用于模型的建立;2018年11月至2019年1月的数据,用于模型检验。对于缺失数据,取各月份职位需求量的平均值。
受到经济、企业招聘周期等制约因素影响,职位信息具有非平稳性、非线性的属性。以职位的需求量为例,其数据随着时间的推移而产生变化,呈现一定的规律性。使用ARIMA模型来拟合,采用自相关分析与偏相关分析的方法来确定模型的类别,即进行模型结构辨识;采用差分的方式进行数据平稳化。如果时间序列的不平稳是由于存在趋势特征时,如数值总体上逐渐增加或者减少,则进行一次差分运算,将差分后的序列作为模型的输入序列。如果一次差分后仍不平稳,则继续进行差分运算,直到序列平稳为止。经过差分运算后,可将带有趋势特征的非平稳序列转化到一个较为平稳的时序数据。
3模型拟合过程与结果
3.1模型的辨识
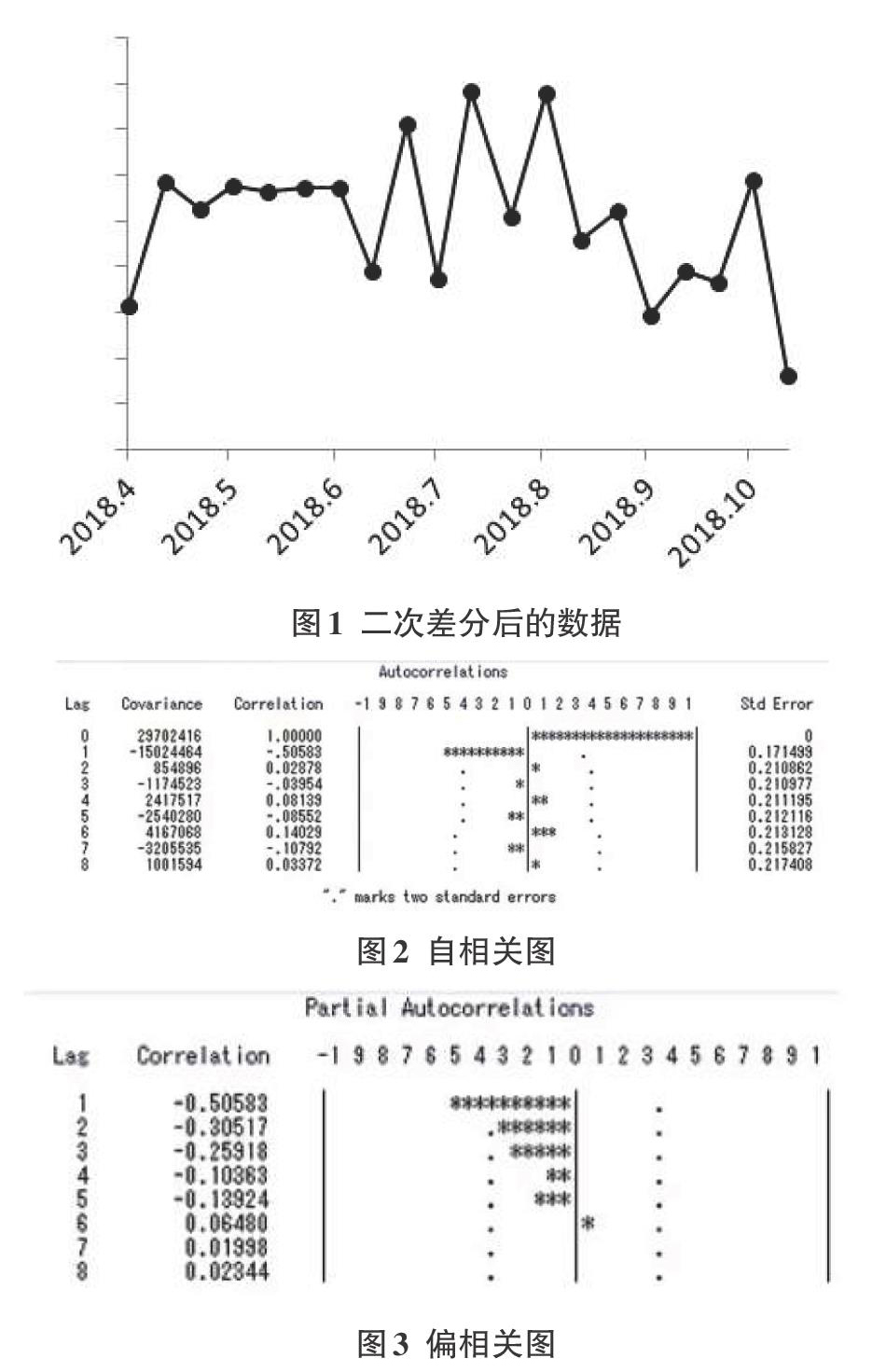
将实验数据处理,进行对数变换后,发现非平稳性并未消除,则需要通过差分将数据平稳化。数据进行一次差分后仍为非平稳序列,则进行二次差分。经过二次差分后的数据(如图1所示),近似平稳。对进一步对其进行单位根检验(ADF检验),检测值小于5%时的临界值,显示为平稳序列。将处理后的数据,进行自相关分析及偏相关分析(如图2、图3所示),偏自相关系数一阶截尾,自相关图显示拖尾性。根据上述结论,判断为ARMA(p,q)模型。
3.2模型的参数估计与检验
由3.1可知,观察自相关图及偏相关图,偏自相关系数一阶截尾,自相关图显示拖尾性,初步判定p=1、q=0。为精确起见,选用p,q=0、1为模型参数进行拟合。
为弥补根据自相关图和偏自相关图定阶的主观性,在模型拟合优度的问题上,本文采用AIC定阶准则。该准则在极大似然值的基础上对模型的阶数和参数给出一组最佳估计。AIC准则是在给出不同模型的AIC计算公式的基础上,选取使AIC值最小的那一组阶数为最佳阶数。对于模型ARMA(0,1)、ARMA(1,0),通过计算取得他们的AIC值为3.2245和3.2386。根据AIC定阶准则,ARMA(0,1)模型的AIC值小于ARMA(1,0)模型的AIC值,因此选择ARMA(0,1)模型。
模型的检验主要是进行残差项的白噪声检验。由于AR—MA(p,g)模型的识别与估计是在假设随机扰动项是在白噪声的基础上进行的,因此,如果估计的模型确认正确的话,残差应代表白噪声序列。如果通過所估计的模型计算的样本残差不是白噪声,则说明模型的识别与估计有误,需重新识别与估计。观察ARMA(0,1)模型的残差序列,并未存在明显特征,可看作是无规律的随机白噪声,即模型拟合成功。
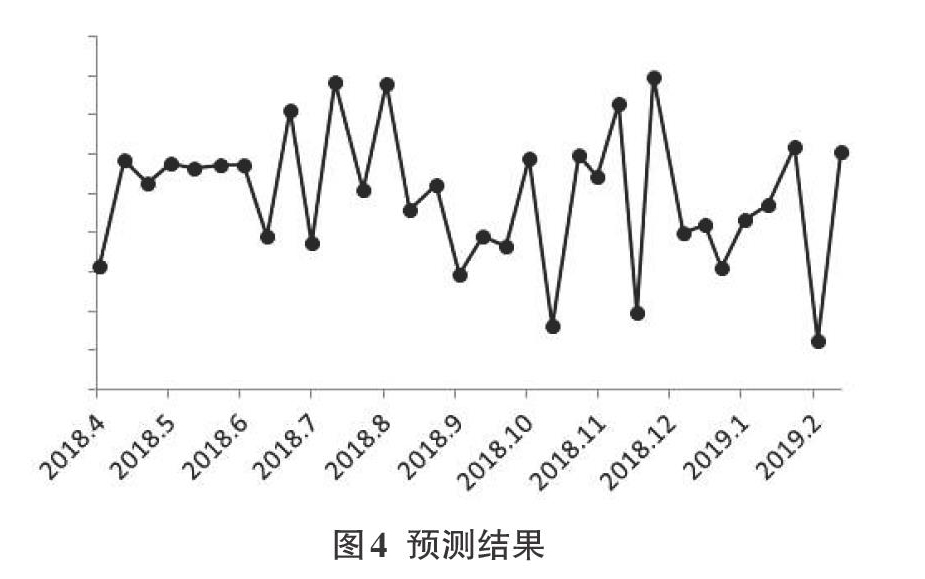
应用该模型对2018年4月至2019年1月北京市python开发工程师职位需求量进行预测,预测结果如图3-4所示。该模型得到的预测值与真实值平均误差率在1.03%。从数据及图形上,该模型预测结果较为合理。
4结论
ARIMA模型适用于数据量小的短期预测,预测结果精确程度较高。当数据量增大时,为提高预测准确度,可根据补充的数据修正该模型。但随着预测期的延长,模型的预测误差将逐渐增大,故可使用该模型进行短期预测。
本文利用ARIMA模型针对某一地区某一职位的需求量进行预测,并取得了较好的预测效果,为网络招聘服务提供巨大的发展空间。对于该领域其他方面的预测,可以把影响因素作为输入变量,进行多变量的时序分析,拟合出更加合理精确的模型。
- 普适计算技术支持下的泛在学习研究
- 基于泛在学习环境的职业教学新方式
- 基于文献计量分析的国内翻转课堂研究综述
- 独立学院计算机公共基础课程改革新思路
- 我国MOOC发展现状及展望
- 基于Selenium进行Web应用测试研究
- Android移动平台中NDEF标签的扫描应用研究
- 基于Web的数据挖掘技术研究
- 基于元数据映射机制的异构数据操作
- 基于Kinect的3D医学影像辅助诊疗系统研究
- 基于GDI+的图像格式转换与几何变换研究
- 规则灰色图片拼接技术研究
- 典型视频目标跟踪方法实现与分析
- 虚拟实景技术在管道展示中的应用
- 基于GIS的三维地形建模及应用研究
- 基于局部三进制模式的边缘检测方法
- 基于开源平台的高校党建网站设计与实现
- 常熟市食物中毒公共卫生事件现场调查处置系统设计
- 公共自行车智能控制系统设计
- 基于社会性软件的农村教师个人学习环境构建策略
- 基于Blackboard的《C++程序设计》PBL教改研究
- 移动互联时代社交媒体在教育教学中的应用
- Scratch及其在课堂教学中的应用优势
- 高校微课建设策略研究
- 利用L2TP VPN搭建高校虚拟专用网络
- antiresistants
- antiresonance
- antirestoration
- antirevolution
- antirevolutionaries
- antirevolutionary
- anti-riot
- antiriot
- antiriots
- antiritual
- antiritualism
- antiritualisms
- antirobbery
- antirock
- antiroll
- anti-romans
- antiromantic
- antiromanticism
- antiromanticisms
- antiromantics
- antiroyal
- antiroyalism
- antiroyalisms
- anti-royalist
- antiroyalist
- 灯宵
- 灯尽油干
- 灯局子
- 灯市
- 灯常拨才亮,刀常磨才快
- 灯座
- 灯彩
- 灯影
- 灯影子作揖——下毒(独)手
- 灯心
- 灯心绒
- 灯或火熄灭
- 灯挂
- 灯捻
- 灯明火彩
- 灯晚儿
- 灯月之下看佳人,更比白日胜十倍
- 灯月圆
- 灯月赋
- 灯果
- 灯架
- 灯标
- 灯檠
- 灯毬
- 灯油