冯宇寒 陈琳 周刚
摘要:广告点击率预估模型在前深度学习时代工业界大多使用训练速度快、可解释强的LR以及挖掘联合特征的FM模型。2016年google提出的Wide&Deep模型为之后的预估模型开辟了一条双网格训练的道路。本文聚焦于Wide&Deep族的广告点击率预估模型,在代码上实现了各模型,并在数据集上进行了实验对比。
关键词:深度学习;广告点击率预估;Wide&Deep
中图分类号:TH69? ? ? 文献标识码:A
文章编号:1009-3044(2020)32-0224-02
Abstract:In the pre-deep learning era, the advertising click-through rate prediction model mostly used LR with fast training speed and strong interpretability and FM model with joint feature mining. The Wide&Deep model proposed by Google in 2016 opened up a dual-grid training path for the subsequent prediction model. This article focuses on the prediction model of advertising click-through rate of the Wide&Deep family,implements each model on the code,and conducts an experimental comparison on the data set.
Key words:deep learning; ad click-through rate estimation; Wide&Deep
1 引言
从1994年10月第一个banner广告出现开始,互联网广告已经发展成一个数十亿美元的规模的产业[1]。广告点击率模型在传统机器学习时代,主要的模型从2010年之前的逻辑回归(LR),进化到因子分解機(FM)、梯度提升树(GBDT)。在广告点击率模型进入到深度学习时代后,其中最为著名的是2016年google提出的Wide&Deep[2]模型,该模型创造性地提出了记忆能力与泛化能力,将线性模型与深度学习网络融合训练,能够同时兼具挖掘藏在数据身后规律和记住大量历史信息的能力。后续发展出现的深度学习模型DCN[3]、DeepFM[4]、AFM[5]以及NFM[6]和NFFM均是经过该模型为基础所调整。
本文对在业界影响力较大的几大模型[7]做了介绍,并且用代码实现了各个模型,在数据集上运行各个模型,在实验基础上对各模型优劣展开论述。
2 算法原理
本文着眼于Wide&Deep、DCN、DeepFM以及NFM模型。
2.1 Wide&Deep
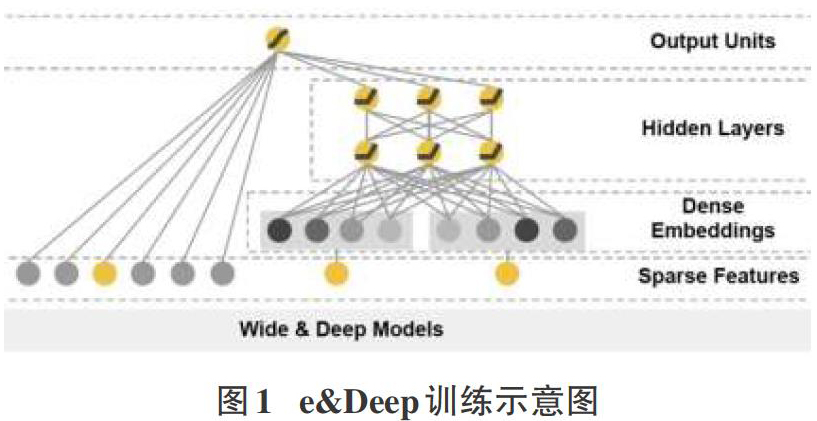
Wide&Deep模型创造性地提出了记忆性和泛化性两个概念,该模型把单输入层的Wide部分和经过多层感知机的Deep部分连接起来,一起输入最终的输出层。其中Wide部分的主要作用是让模型具有记忆性,单层的Wide部分善于处理大量稀疏的id类特征,便于让模型直接“记住”用户的大量历史信息;Deep部分的主要作用是让模型具有“泛化性”,利用DNN表达能力强的特点,挖掘藏在特征后面的数据模式。之后LR输出层将Wide部分和Deep部分组合起来,形成输出结果。Wide&Deep对之后模型的影响在于——大量深度学习模型采用了两部分甚至多部分组合的形式,利用不同网络结构挖掘不同的信息后进行组合,充分利用和结合了不同网络结构的特点。
2.2 FM
在Wide&Deep之后,诸多模型延续了双网络组合的结构,DeepFM就是其中之一。DeepFM对Wide&Deep的改进之处在于,它用FM替换掉了原来的Wide部分,加强了浅层网络部分特征组合的能力。事实上,由于FM本身就是由一阶部分和二阶部分组成的,DeepFM相当于同时组合了原Wide部分、二阶特征交叉部分与Deep部分三种结构,无疑进一步增强了模型的表达能力。
2.3 DCN
Google 2017年发表的Deep&Cross Network(DCN)同样是对Wide&Deep的进一步改进,主要的思路使用Cross网络替代了原来的Wide部分。其中设计Cross网络的基本动机是为了增加特征之间的交互力度,使用多层cross layer对输入向量进行特征交叉。单层cross layer的基本操作是将cross layer的输入向量xl与原始的输入向量x0进行交叉,并加入bias向量和原始xl输入向量。DCN本质上还是对Wide&Deep中的Wide部分表达能力不足的问题进行改进,与DeepFM的思路非常类似。
2.4 NFM
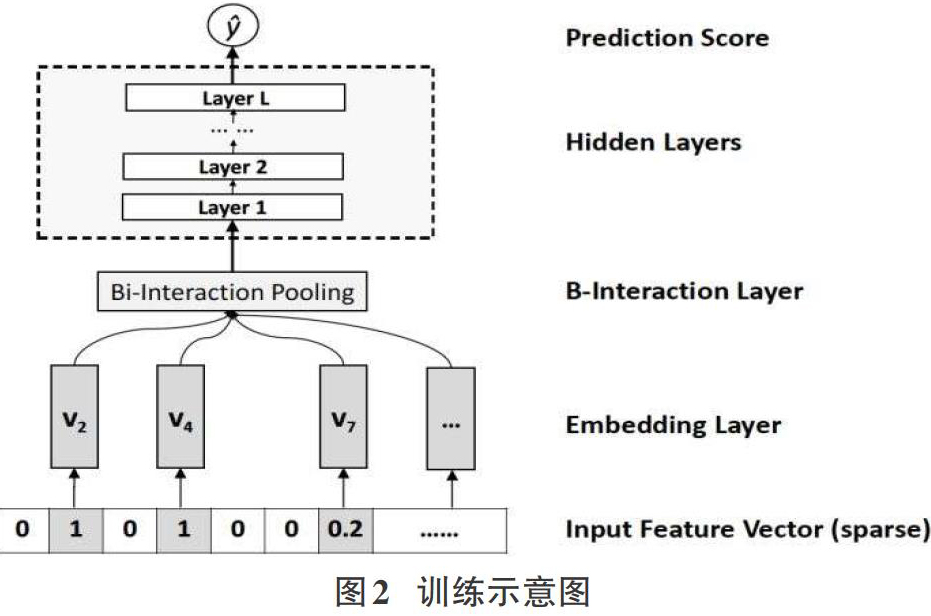
相对于DeepFM和DCN对于Wide&Deep中对Wide部分的改进,NFM可以看作是对Deep部分的改进。FM可以看作是由单层LR与二阶特征交叉组成的W&D架构,与W&D架构的不同之处仅在于Deep部分变成了二阶隐向量相乘的形式。再进一步,NFM从修改FM二阶部分的角度出发,用一个带Bi-interaction层的DNN替换了FM的特征交叉部分,形成了独特的W&D架构。其中Bi-interaction可以看作是不同特征embedding的element-wise product的形式。这也是NFM相比Wide&Deep的创新之处。
3 实验分析
3.1 实验数据以及预处理
本文选择了criteo在kaggle上举办的展示广告点击率预估挑战大赛的数据集,在该数据集中,criteo共享了一周的流量数据。该数据集共有四十个特征,第一个为标签,为二分类类型,含义为该用户是否点击广告。第二到十四个特征是连续性特征,全部为整数。剩下的26个特征为分类特征,并且值被hash处理过,以达到特征匿名的效果。
本实验将该数据集按9:1进行划分分为训练集和测试集。对连续性特征进行缺失值补0,离散分桶处理;对离散型特征过滤频率低于10的特征值处理。
3.2 评价指标
本实验采用AUC评价指标。
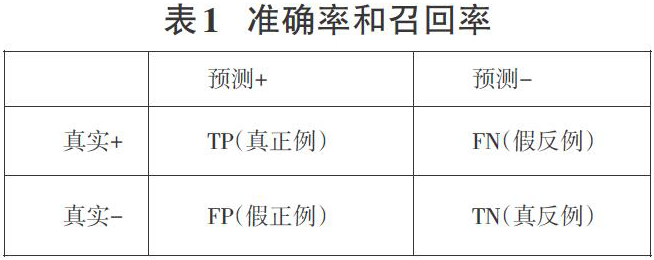
在介绍评价指标之前,要先介绍准确率和召回率两个概念。准确率P为预测为正的样本中,真实标签为正的样本的比例P=TP/(TP+FP);召回率R为真实标签为正的样本中,预测为正的比例R=TP/(TP+FN)。
而在ROC曲线中,横轴为假正例率FPR,纵轴为真正例率TPR。其中假正例率为真实标签为负的样本中,预测为正的样本比例FPR=FP/(FP+TN);真正例率实际上就是召回率。如果模型A的ROC曲线能完全包住模型B的ROC曲线,则可断言A的性能比B好,但是两个模型的ROC往往是相交的,这时为了比较性能就需要用到AUC。
AUC就是ROC曲线和x轴(FPR轴)之间的面积。AUC考虑的是模型预测的排序质量,反映了模型把正例排在反例前面的比例,如果AUC=1,说明模型100%将所有正例排在反例前面。
3.3 实验结果与分析
在运行时间上,如表2所示,7万两千个样本Wide&Deep只训练了1686秒,DeepFM训练了2641秒,DCN训练了8549秒,NFM训练了2502秒。在表中我们可以直观看出Wide&Deep在样本上训练的时间极短、极快,而相应的DCN的训练时间上很难达到Wide&Deep的量级,达到了2.4个小时。
如表2所示,更多的训练时间使得DCN在评价指标上拿到了最好的表现,AUC值比最差的Wide&Deep高出了两个千分点,相比于表现第二好的NFM模型提升了一个千分点。在实验中,我们也看到另一指标LogLoss的值,虽然DCN在这些模型中的表現并不好看,但从指标意义来看,LogLoss是一个通用性的指标,AUC则更加希望正类得分尽可能高,故我们仍然可以说DCN在这些深度学习模型中表现最好。
4 结论
在实验中,我们简单地实现了模型,用这些基础模型来对深度学习中的广告点击率模型做综述,并未对参数进行调优,故我们得出有限的结论:在运行时间上,Wide&Deep有着巨大的优势,训练时间短,相比于DCN缩短了五倍。在理论上和实践中,DCN模型的优势则更突出,超参数数目更多,模型更复杂。更充分地挖掘了特征背后的关系,联合特征对结果的影响。在此实验中,网络结构更为复杂的DCN确实拿到了最好的表现效果。
参考文献:
[1] 刘鹏, 王超.计算广告:互联网商业变现的市场与技术[M].北京:人民邮电出版社, 2015.
[2] CHENG H T, KOC L, HARMSEN J, et al.Wide & Deep Learning for Recommender Systems[C]//The Workshop on Deep Learning for Recommender Systems.Boston, USA, 2016:7-10.
[3] WANG R, FU B, FU G, et al.Deep & Cross Network for Ad Click Predictions[C]//Proceedings of AdKDD and TargetAd.Halifax, 2017:1-7.
[4] GUO H, TANG R, YE Y, et al.DeepFM:A Factorization-Machine based Neural Network for CTR Prediction[C]//Procee-dings of the Twenty-Sixth International Joint Conference on Artificial Intelligence.Melbourne, Australia, 2017:1725-1731.
[5] XIAO J, YE H, HE X N.Attentional Factorization Machines:Learning the Weight of Feature Interactions via Attention Networks[C]//Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence.Melbourne, Australia, 2017:3119-3125.
[6] HE X G, CHUA T S.Neural Factorization Machines for Sparse Predictive Analytics[C]//The 40th International ACM SIGIR Conference on Research and Development in Information Retrieval.Shinjuku, Tokyo, Japan, 2017:355-364.
[7] 刘梦娟,曾贵川,岳威,等.面向展示广告的点击率预测模型综述[J].计算机科学,2019,46(7):38-49.
【通联编辑:梁书】
- 河西走廊日光温室“中农金辉”油桃促早栽培技术
- 永靖县金银花产业现状与发展对策
- 试论新时代农业新业态的特征和实践要求
- 8个食用向日葵品种(系)在环县旱地的引种初报
- 4个青贮玉米品种在庄浪县旱作区引种初报
- 适宜会宁县半干旱区旧膜穴播的胡麻品种筛选试验
- 烘烤工艺对上部烟叶化学品质的影响
- 平凉市黑垆土土壤养分平衡状况及其评价
- 苹果蠹蛾雄虫发生动态及其与气温和降水的相关性研究
- 红笋叶与玉米秸秆混贮工艺条件优化
- 河西地区赤霞珠葡萄果实发育期糖代谢及相关酶活性的变化
- 栽植方式对盐碱地枸杞幼苗的影响
- 甘肃民勤野生黑果枸杞果实营养成分分析
- 7个戈壁日光温室越冬茬番茄品种的品质及产量比较
- 外源ALA对板蓝根幼苗光合特性及叶绿素荧光参数的影响
- 播期和密度对白银沿黄灌区冬小麦产量的影响
- 玉米品种龙博士7号选育报告
- 棉铃虫成虫发生动态及其与气温和降水的相关性
- 矮秆高产优质多抗冬小麦新品种陇麦479选育报告
- 地面覆盖方式对马铃薯产量和水分利用效率的影响
- 棉花新品种陇棉10号选育报告
- 向日葵全膜双垄沟播覆盖二比一空垄栽培技术
- 苯氧菌胺研究开发综述
- 灵台县小杂粮生产现状及发展建议
- 6个菜用型马铃薯品种在麦积区山旱地的引种初报
- entrant
- entrants
- entreat
- entreatable
- entreatance
- entreated
- entreater
- entreatful
- entreaties
- entreating
- entreatingly
- entreative
- entreatment
- entreatments
- entreats
- entreaty
- entrenched
- entrepreneur
- entrepreneured
- entrepreneurial
- entrepreneurialism
- entrepreneurialism, entrepreneurism
- entrepreneurialisms
- entrepreneurially
- entrepreneuring
- 开卷考
- 开卷诵读
- 开卷,读书
- 开厂
- 开原
- 开厨门
- 开去
- 开发
- 开发区
- 开发商
- 开发收闭
- 开发智力的教育
- 开发治理
- 开发矿藏
- 开发票
- 开取
- 开口
- 开口不客气
- 开口不怕大
- 开口不言钱
- 开口不骂笑脸人
- 开口乞讨
- 开口僧
- 开口儿
- 开口副韵