孙云
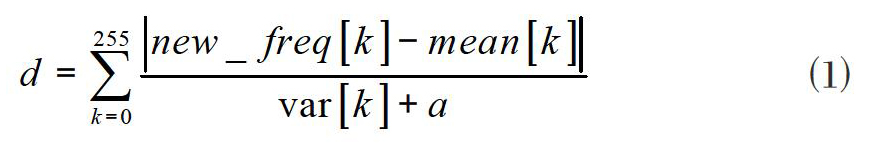

摘 要: 入侵检测系统通常会产生大量的报警,需要大量的人力进行分析,这严重降低了系统的可用性。文章在对入侵检测算法和网络攻击进行详细分析的基础上,提出一种基于异常检测的报警融合技术,将低层次的报警归并为高层次的攻击事件,减轻了人工分析的工作量。研究和实验表明,该算法能有效地对Web攻击报警进行聚类和融合,提高了系统的可用性。
关键词: 入侵检测; 异常检测; 报警融合; 网络安全
中图分类号:TP393.08 文献标志码:A 文章编号:1006-8228(2016)08-39-05
Abstract: IDS (Intrusion Detection System) usually generates a lot of alerts, and the need for a large number of human analyses seriously reduces the availability of the system. In this paper, an alerts fusion method is put forward after thoroughly analyzing anomaly intrusion detection algorithm and network attacks. The methods can reduce the number of alerts and alleviate security expert's workload. The experiments show that the method can fuse Web attack alerts effectively and improve IDS's availability.
Key words: intrusion detection; anomaly detection; alerts fusion; network security
0 引言
随着网络安全问题的日益严峻,传统的网络安全技术如防火墙难以提供足够的安全防护,入侵检测系统被认为是继防火墙之后的第二道安全防护系统,在保障网络安全中担负起重要的角色。然而,入侵检测系统运行时往往会产生大量的报警,单凭人力难以处理日益增长的海量报警,严重降低了系统的可用性。如何对报警进行有效处理,减少人工分析的工作量,提高系统的实用性,一直是困扰入侵检测系统的难题。本文介绍了异常入侵检测算法Payload AD(Anomalous Payload-based Network Intrusion Detection)的原理,并分析其对Web攻击的检测,在此基础上提出一种报警融合技术,将低层次的报警归并为高层次的攻击事件,进而减少报警的数量,提高了报警的质量。
1 入侵检测算法Payload AD概述
Payload AD(Anomalous Payload-based Network Intrusion Detection)[1]是一种基于数据包负载的异常入侵检测算法,算法基于如下的观察事实:将网络数据包看成由字节组成的数据流,每个字节的取值范围为[0,255],对于不同目的端口(对应于不同网络协议)的数据包,包中负载的字节取值分布是不同的,比如:对于端口21(FTP命令端口),23(TELNET),80(HTTP)等,包中的字节多为可打印字符(例如:FTP命令,TELNET交互命令,HTTP请求),而对于20(FTP数据端口),22(SSH),由于传输的是文件或加密的数据,包中的字节多为随机分布;同样,对于相同端口的数据包,不同长度数据包的字节取值分布也会不同,小包往往是一些命令字符,取值分布比较规则,而大包多为文件和数据传输,取值分布较为随机。将正常流量的数据包按照目的端口和包长度分类,对于每一类数据包,统计其字节取值分布,将其作为正常分布,将新来数据包的字节取值分布与正常分布对比,计算新包与正常分布的偏离,如偏离过大则判定新数据包属于异常。
该算法实现简要步骤如下。
⑴ 给定一个正常网络流量的数据包集合作为训练集,对于每一个数据包,统计向量freq[0..255],freq[k]为字符值k(k∈[0,255])在该数据包中出现的频率,该向量反映了数据包的字符分布特征。
⑵ 将数据包按长度和目的端口分类,对长度为i、目的端口为j的数据包类,计算参量值M[i,j]={mean[i,j][0..255],var[i,j][0..255]},其中mean[i,j][0..255],var[i,j][0..255]是两个向量,分别表示字符值0~255在该类数据包中出现频率的均值和标准差,用M[i,j]表示长度为i目的端口为j的数据包正常分布参量值。
⑶ 当新的数据包到来时,统计其字节分布向量new_freq[0..255](定义同1),根据数据包的长度length和目的端口dport查找相应参量M[length,dport],计算偏离量d=f(new_freq,M[length,dport]),如果偏离量超过一定阈值t,则认为是异常数据包。
⑷ 对于正常数据包(偏离值没超过阈值),使用增量算法更新参量,使参量能实时反映流量的变动。
计算新数据包与正常流量的偏离f(new_freq,M[length,dport])使用的是马氏(Mahalanobis)距离,马氏距离的优点在于,不但考虑了均值,还考虑了协方差,克服了变量之间相关性的干扰。为避免复杂的平方和开方运算,计算时采用了简化的马氏距离公式[1]:
new_freq,mean和var分别是新数据包的字符分布向量、参量M[length,dport]的均值向量mean[length,dport]和标准差向量var[length,dport],a(0
- 浅谈森林火灾调查及损失评估存在的问题与建议
- 农业栽培技术推广应用探究
- 林业技术创新与现代林业发展分析
- 浅谈植树造林技术及营林生产管理的有效途径
- 农业工程技术在农业现代化中的运用分析
- 林业资源保护管理现状与可持续发展对策
- 城市湿地公园园林绿化及养护管理策略的探讨
- 森林灾害对我国林业经济增长的影响分析
- 论生态理念下园林绿化工作的创新
- 水稻全程机械化绿色增产模式攻关成效与措施
- 现代林业育苗理念与育种技术研究
- 刺槐育苗技术措施探析
- 试析林业种苗繁育技术
- 人工造林及抚育管理技术研究
- 园林绿化施工中苗木种植施工研究
- 青海云杉育苗栽培及管理技术
- 园林绿化施工中乔木栽植难点分析
- 现代林业育苗技术及造林方法
- 新时期森林抚育经营技术与措施分析
- 浅谈喀左地区影响苹果低产的主要原因及其病虫害防治方法
- 基于病害防治技术的水稻种植常见病虫害研究
- 花生主要病虫害特点及防治技术
- 盐碱地改良及园林绿化施工技术研究
- 水稻病虫害绿色防控技术
- 云杉常见病虫害及其防治技术
- manipulable,manipulatable
- manipulate
- manipulated
- manipulates
- manipulating
- manipulation
- manipulations
- manipulative
- manipulatively
- manipulativeness
- manipulativenesses
- manipulatives
- manipulator
- manipulators
- mankind
- mankind/humankind
- mankinds
- manlessly
- manlessness
- manlessnesses
- manlessness's
- manlier
- manliest
- manlihood
- manlily
- 讨伐消灭
- 讨伐消灭凶恶叛逆的人
- 讨伐程度
- 讨伐绥靖
- 讨伐者声威强大,不战而降服对方
- 讨伐芟除
- 讨伐贼寇
- 讨伐,攻击
- 讨便宜
- 讨便宜即是吃亏的后门
- 讨便宜处失便宜
- 讨俏
- 讨保
- 讨信
- 讨债
- 讨债公司
- 讨债块
- 讨债鬼
- 讨公道
- 讨冷饭吃
- 讨击
- 讨分上
- 讨分晓
- 讨删
- 讨力