洛松求培+安见才让
摘 要: 互联网的发展带动了另一种形式的信息传播,人们越来越多地依赖于电子产品,Web网页也随之变为了最大的信息源,利用好这些资源便涉及信息提取。为了从Web网页中获取关键藏文信息,文章提出了基于文本密度的藏文网页正文提取方法,利用半结构化的HTML网页中正文内容的连续性特点,结合正则表达式过滤HTML标签。此方法针对主题型网页,类似新闻类网页中的正文提取具有较高的准确率。
关键词: 藏文信息; 藏文网页正文提取; HTML; Web网页
中图分类号:TP391 文献标志码:A 文章编号:1006-8228(2017)08-46-02
Abstract: The development of the Internet has led to another form of information dissemination, people are increasingly relying on electronic products, Web also become the largest source of information, and the use of these resources will involve the extraction of information. In order to obtain the key Tibetan information from the Web, this paper proposes a method to extract the Web text based on text density, which uses the continuity characteristics of semi-structured text content in HTML pages and the regular expression. This method has higher accuracy for text extraction in theme pages and similar news pages.
Key words: Tibetan information; Tibetan Web content extraction; HTML; Web
0 引言
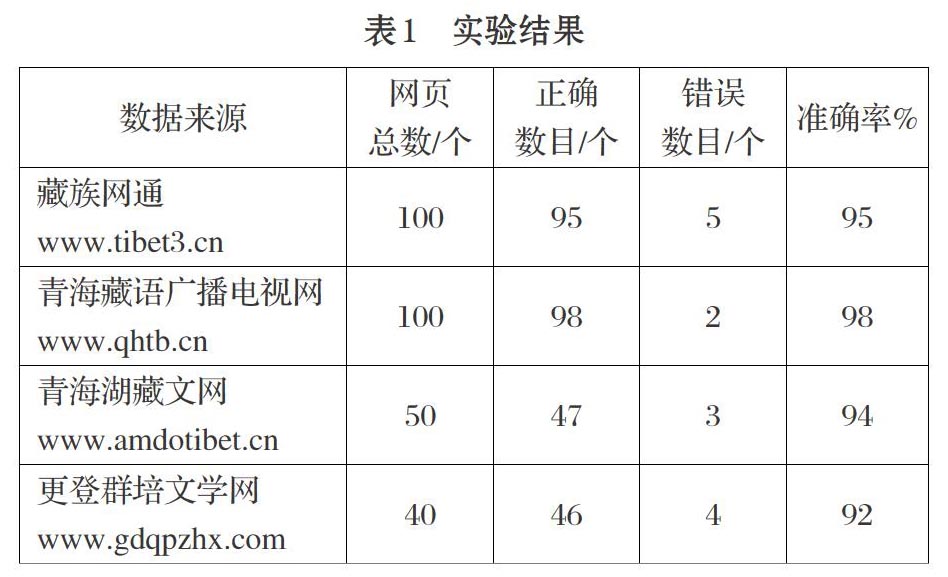
随着互联网的迅速发展,计算机应用技术在藏族地区的不断普及应用,出现了大量的藏文网页,为广大藏族群众提供了极其丰富的藏文信息资源。目前搜索引擎能帮助人们快速地搜索到想要的信息,但每个网页除了正文内容外还掺杂了很多用户不需要的信息。如网页中的导航链接、广告链接、版权信息和相关主题阅读推荐链接等。这些信息在网页中出现,影响了用户对主题内容的浏览。按照现在的发展情况,藏文网页的数量呈现上升趋势,用户的数量也在逐年增加。
因此,从大量噪音信息的网页中将正文信息准确、完整地提取出来,显得尤为重要。Web信息提取是将Web作为信息源的一类信息提取,就是从半结构化的Web文档中抽取数据。国内外在这方面关注的时间比较早,研究提出的方法也很多,技术已趋于成熟。目前藏文网页正文提取研究较少,西藏大学提出了一种基于标签分段的藏文网页正文提取[1],利用HTML标记用途分析提到的此方法对标签的依赖性高,加之HTML语言的规范性不是很好,网页设计人员的语言风格也不尽相同,如遇未使用标记的网页很难实现有效提取。有些论文中提到了关于网页除噪[2]的问题,但是没有进一步研究与之结合及提出行之有效的藏文网页正文提取。本文提出的方法意在避免复杂的算法,利用简单可行的方法将其实现。
1 基于文本密度的藏文网页提取
藏文网页大部分都是以国内外新闻、藏族文化历史、藏族风土人情、藏文论坛等为主要内容。由于大量的藏文网页中多数是以文字内容为主体,本文针对此类主题型网页进行分析,实现基于文本密度的正文提取算法。互联网上藏文网页常用的标记语言主要包含HTML和XML等格式,其中HTML语言是大部分网页的基础。由于HTML存储的网页信息资源是半结构化,用户使用和提取信息无法直接操作,因此,需要对其结构进行分析。
1.1 正文内容的结构特征
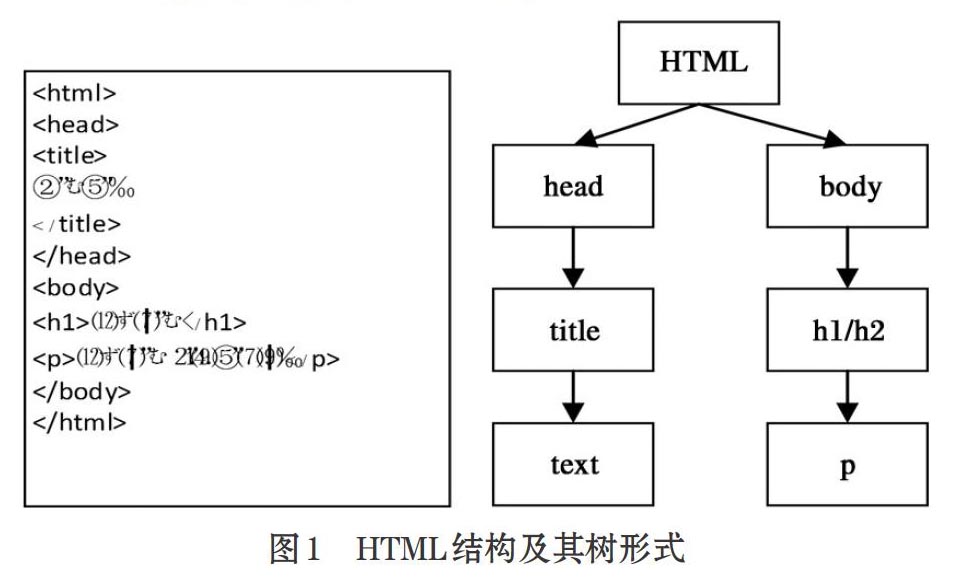
一个网页的正文内容具有很好的连续性,结构都非常相似,在HTML格式中正文出现在标签中,如图1所示。通过对大量的主题型网页进行分析,我们发现正文内容的连续性和集中性的特点普遍的存在。HTML标签使用上也存在着很多的共性,例如对于篇幅较长、文字較多的内容,利用
标签将其段落分明。鉴于此,在标签中找到文本密集的连续段落就能准确获取正文内容。
1.2 正文提取
按照HTML语言的规范,标签通常都成对出现,基于这个规范,将每对标签内容作为基本处理单位,存储于字符数组lines以便分析。接着循环字符数组中的元素对其进行HTML标签过滤,这样做是为了降低干扰,因为我们关注的只是正文内容。HTML标签过滤直接使用正则表达式替换,其表达式为:Regex.Replace(html, "(?is)<.*?>", ""),表达式中字符串html是数组中的元素,即每对标签的内容。考虑到非正文的噪音信息也掺杂在其中,因此必须在数组中找到除去噪音信息的正文文本的起止行号。但是如何判断行号的起始与终止,从正文内容的结构来看,发现了都有这么一个特征:正文部分的文本密度要高出非正文部分很多。本文按照这个特征将方法实现,其原理就是基于阈值分析正文所在位置。通过字符限定数来确定阈值,根据藏文网页通过统计分析得出一个比较好的取值,在实际处理过程中,发现这个值取550是比较适合的。在分析文本时,如果分析文本超过设定的阈值,我们就判断出正文所在位置。鉴于正文内容不可能为一行,逐行分析不可行,因此确定按行分析的深度Depth为6,将字符累加后判断是否达到预定的阈值。具体算法如下。
- 儿童钢琴学习启蒙时期的视奏能力培养探究
- 浅析人声及音乐在电影中的作用
- 小剧场曲艺发展面临的问题分析
- 钢琴曲《太极》与《易经》八卦之关联
- 现代二人转唱词写作的传承与创新
- 二胡曲中戏曲风格类型及其演奏技法研究
- 昆曲竹笛和民乐竹笛的演奏技巧对比
- 从多代“江姐”看民族歌剧演唱的变化和发展
- 地域差异对中国传统音乐的影响
- 浅析朝鲜族横笛在演奏中的呼吸作用
- 浅谈蒋风之及“蒋派”二胡艺术
- “流动的传统之河”
- 新时代下陕北民歌的发展初探
- 浅谈民族歌剧《星星之火》李小凤的咏叹调《我是个穷苦的小姑娘》的演唱分析
- 云南民族音乐的美学艺术审美特征分析
- 陕西埙乐现状及发展趋势研究
- 二胡演奏中人物形象的塑造
- “江苏二胡”代表性演奏家演奏风格探析
- 中国民族歌剧的传承与创新结合考究
- 纪念越剧大师傅全香
- 论四川号子的艺术特征
- 浪漫主义时期西方音乐中的“中国因素”刍议
- 大提琴在民族管弦乐队中的地位
- 大提琴演奏中艺术表现力的培养思考
- 人文传统背景与中西声乐文化差异比较分析
- pro-bohemian
- pro-bohemians
- probono
- pro bono
- proboycott
- pro-british
- pro-buddhist
- pro-buddhists
- pro-budgeting
- probusiness
- pro-capitalism
- procapitalism
- procapitalisms
- procapitalist
- procapitalists
- procarcinogen
- procarcinogenic
- pro-cathedral
- reapprove
- reapproved
- reapproves
- reapproving
- reaps
- rear
- rearbitrate
- 开从
- 开仓
- 开仓出谷赈济
- 开仓救济
- 开仓济贫
- 开仓赈济
- 开仗
- 开付
- 开价
- 开伏
- 开伙
- 开会
- 开会厂长
- 开会差半点
- 开会或商讨问题时提出供讨论的议案或意见
- 开会无人发言的局面
- 开会时无人发言
- 开会议事的大房间
- 开会请了假——没出席
- 开会请了假——没出席(息)
- 开佛光明
- 开例
- 开信
- 开倒车
- 开假