张银杰 揣锦华 翟晓惠
摘要:针对微软恶意软件预测数据集,文章结合特征工程的思想和集成学习算法实现恶意软件感染的预测。为了更好地适应算法的输入要求,对数据集进行预处理和特征构建,并提出一种利用LightGBM算法以提高预测性能的启发式搜索方式,得到最终的特征集。以筛选后的特征构成的数据集实现了LightGBM,XGBoost和CART算法的预测,并对预测性能进行了比对分析。通过完全相同的交叉验证证明,在恶意软件预测时,集成学习算法有更好的预测性能,AUC值明显高于传统决策树算法。
关键词:恶意软件预测;特征工程;LightGBM;XGBoost
中图分类号:520.4070 文献标识码:A 文章编号:1006-8228(2020)07-07-05
0引言
近年来,恶意软件在PC端的传播感染和攻击行为日益频繁,给企业和个人计算机用户的信息安全和财产带来严重威胁,在此背景下微软提供Windows计算机恶意软件感染数据集,旨在实现对计算机是否感染恶意软件的概率预测。机器学习在网络安全领域的应用也越来越广泛嘲,boosting集成学习算法是近年来机器学习中较为流行的算法,例如基于树模型集成的LightGBM和XGBoost算法,近年来常用于基于数据集的预测。本文对数据集进行了预处理,并根据特征工程的理论进行特征的构建与选择,最终使用boosting算法,实现对恶意软件感染的有效预测。如何从大量原始数据中尽可能地挖掘出与预测恶意软件相关联的信息,并借助集成学习的预测性能实现恶意软件的预测是本文研究的主要内容。
1数据认知与预处理
1.1数据认知
本文数据引用自kaggle网站的微软恶意软件预测数据集。本文预测目的为Windows计算机是否感染恶意软件,预测标签为计算机是否检测出恶意软件(检测出记为1,未检测出记为0),即原数据集中的HasDetections字段。为探究boosting算法在该数据集上的预测效果,本文取其前120万条数据进行研究。
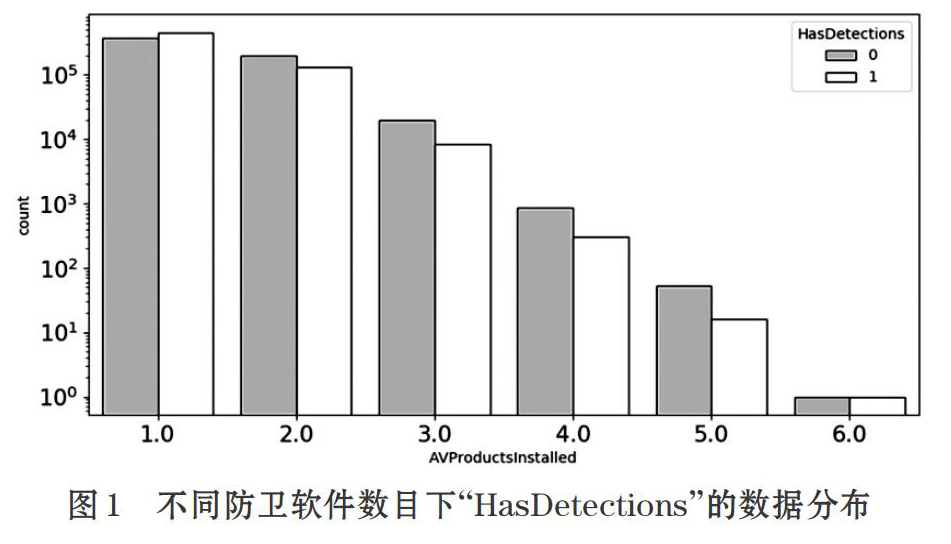
所取样本中预测标签的正负样本分布大致相同,因此不需要进行额外的分层抽样以确保训练集中的正负样本比例。将其他特征与预测标签进行了数据趋势分析,例如,图1所举的示例为不同“AVProduc-tInstalled”(安装防卫软件数目)下“HasDetections”的数据分布,从中可以看出,在感染恶意软件的数据更集中于防卫软件数目较少的情况。通过以上特征间的分析过程,证明其他特征与预测标签有一定关联性。
1.2数据预处理
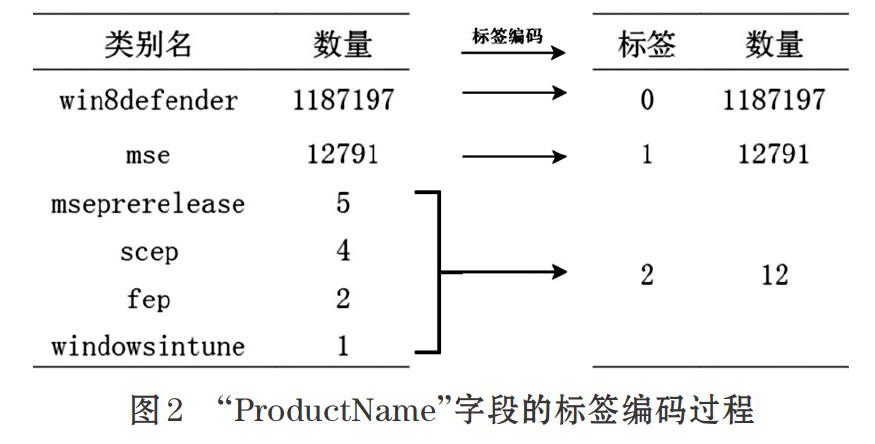
数据集中大部分特征都为类别特征。为了使数据更适用于机器学习算法的训练,对于原始数据集中的类别型数据采用标签编码的方式。例如,图2给出“ProductName”字段的标签编码过程,该字段原有6个类别,在特征编码时将数量少于1000的所有类别视为异常值,合并划为同一标签。
对于数据集中的数值型数据与布尔型数据不作处理,保留原有数据格式。经过数据预处理后,得到可以投入机器学习训练的数据集。
2相关方法与理论
2.1特征工程及特征选择方法
特征工程(Feature Engineering),是一系列工程活动的总称。特征工程的目的,是最大限度地从原始数据中找到适合模型的特征。此过程不仅能够降低计算的运行速度,提高模型的预测性能,也使得模型更好理解和维护。
特征选择是特征工程中关键的一步,实际的特征构建过程中,特征之间可能存在依赖,也可能存在与预测目标不相关的特征。特征选择是筛选出合适特征的过程,本文提出一种启发性特征搜索方式以提高预测性能,主要思想是以分类器的预测性能作为判断准则,从当前的特征集合中移除最不重要的特征,其次根据准则决定部分特征是否删减或保留,重复上述过程,直到最终的特征集不再发生变化。
2.2分类算法
CART算法,即分类与回归树(classification andregression tree,CART),是一种常用于分类和回归任务的决策树算法。在执行分类任务时,用基尼指数选择判断最优特征及最优切分点的依据来构造分类树。最后基于子树的平方误差或基尼指数,剪去部分子树,减少过拟合以更适应未知数据的预测。
XGBoost是以分类回归树(CART树)进行组合的一种boosting集成学习方法。XGBoost在使用CART作为基分类器时增加了正则项,大大提升了模型的泛化能力。基于分类回归树的XGBoost算法能很好地处理本文中的表格性数据,还可以自动对缺失值进行处理,同时提供更好的优化参数的方式。
作为boosting集合模型中的新进成员,LightGBM是一种基于决策树算法的分布式梯度提升框架,原理上采用损失函数的负梯度作为当前决策树的残差近似值去拟合新的决策树。在特征重要性判断上,LightGBM相对于其他集成学习算法有很多重要的优势,例如支持直接输入类别特征,能输出特征重要性分数,以及较低的计算代价等。
2.3二分类模型評估指标
2.3.1混淆矩阵
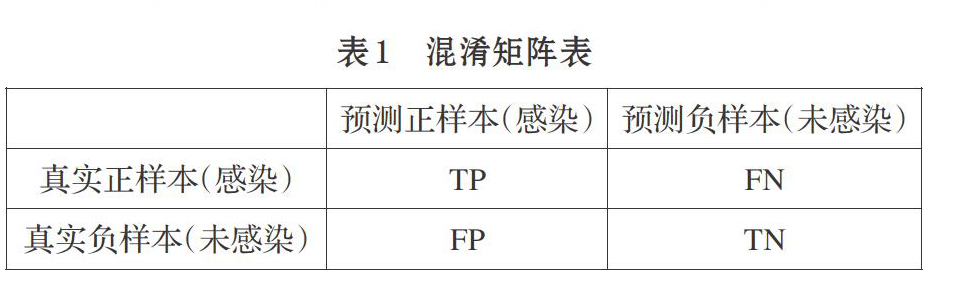
混淆矩阵是用来评估二分类模型的一种可视化工具。本文根据模型的预测结果与真实分类结果的比较将所有样本划分为四部分,具体如表l所示。
表1中的四部分具体如下。
真正(True Positive,TP):当一个正样本被模型预测为正类。
假正(False Positive,FP):当一个负样本被模型预测为正类。
假负(False Negative,FN):当一个正样本被模型预测为负类。
真负(True Negative,TN):当一个负样本被模型预测为负类。
2.3.2 ROC曲线与AUC值
ROC曲线是衡量二分类模型的一个指标工具,ROC曲线的横纵坐标由混淆矩阵四部分计算得到。ROC曲线横坐标为FPR(False Positive Rate,假正率),FPR公式如下:
TPR即被预测为正的正样本数/真实正样本数。一般情况下,ROC曲线都处于(0,0)和(1,1)连线的上方。
本文中采用AUC(Area Under Curve)作为二分类模型的判断指标。AUC被定义为ROC曲线下的面积(ROC的积分),通常大于0.5且小于1。AUC可以理解为随机挑选一个正样本以及一个负样本,分类器判定正样本的值高于负样本的概率。使用AUC可以对多个分类器的预测性能作出准确的性能度量。AUC值越大的分类器,性能越好。
2.4 k折交叉验证
k折交叉验证指将整个数据集分成大小几乎相等的k部分。然后将第k个数据子集作为测试集,剩余部分全部作为训练集,从而完成k次训练预测,返回整个测试集的测试结果的平均值。常见的k值有5、10、20等。为了全面评估预测模型的性能,本文皆采用五折交叉验证的方式评估预测结果。
3特征工程与集成学习在恶意软件预测上的应用
3.1特征工程在恶意软件预测上的应用
3.1.1特征的构建
将数据集中的属性字段转换为原始特征,共得到类别型特征53个,数值型特征10个,布尔型特征18个。基于这些原始特征可以构造更多的衍生特征,以进一步提高模型预测精度。新的衍生特征主要通过以下几个方向完成衍生特征的构建。
(1)原特征的分解
因为版本信息具有时间变化的趋势,不同版本下感染恶意软件的概率可能有所不同,因此提取防卫软件引擎版本EngineVersion、防卫软件APP版本AppVersion等字段按照版本层次的差异分割成若干特征。
(2)特征间的组合
①特征间的加减乘除:根据计算机安全的相关业务逻辑构造新的特征。例如,根据计算机可使用的防卫软件/计算机已安装的防卫软件,可以得到计算机防卫软件可使用率这一新衍生特征,用以进一步表示计算机安装防卫软件的情况。
②根据特征值的不同构建新特征:例如根据计算机是否存在于计算机设备普及比较高的国家,构建一个新的0/1变量作为衍生特征(0表示否,1表示是)。
(3)构造哑变量特征
因为数据集中部分类别型特征存在缺失值的情况,可以将某特征是否存在缺失值作为一个新的布尔型衍生特征。
根据以上三个维度进行特征构建,得到最终的特征分布如表2所示。
3.1.2特征的筛选
过多的特征对于分类器来说计算开销太大,而且分类性能不一定更好。因此,需要对特征的重要性进行判断,再对特征进行筛选,得到最终预测使用的特征集。在特征重要性判断上,LightGBM算法具有支持直接输入类别特征,能输出特征重要性分数以及较低的计算代价等特点。因此本次实验选择LightGBM算法对特征进行选择。
结合LightGBM算法,由特征全集训练可以得到特征重要性排名,在此过程中,剔除了所有重要性为0的特征;另外需要再对剩下的特征进行选择,筛选过程中选择AUC值作为模型效果评价指标,AUC值越大说明模型越好。
根据特征重要性排名,剔除所有重要性为0的特征后还有158个待筛选特征,随后以五折交叉验证的AUC平均值作为目标函数,执行特征集的启发性搜索以得到最终特征集。该启发陛搜索过程的流程图如图3所示。
多次执行上述过程,直至输入的特征集与输出的特征集完全相同,此时删除任何一个特征都会导致AUC值降低,确保最终找到一个局部最优的特征集。在实际对原始特征筛选过程中,第七次筛选输入的特征集与输出相比不再发生变化,因此取第六次筛选结果的特征集。筛选过程中的AUC变化如表3所示。
由表3得,这种特征选择方式使得在特征数缩减的情况下模型AUC值仍能提高。说明这种特征选择方式不但可以降低计算开销,也使模型的预测能力得到提高。经过特征选择后预测模型的特征数目确定为129。
3.2集成学习算法在恶意软件上的应用
经过特征选择过程后,得到只包含筛选后的129特征的实验数据集。Python编程环境中可以方便的调用机器学习算法,在Python环境中选择合适的参数利用LightGBM和XGBoost算法对该数据集进行训练和交叉验证。为了比较两种集成学习算法与传统算法性能上的差异,选择决策树算法CART算法作为对比。
由以上三种算法对数据集进行五折交叉验证,得到如表4所示五次验证过程中验证集AUC的对比结果。
由表4的结果得,集成学习算法中的LightGBM与XGBoost算法在每一折验证集的AUC值上均高于CART算法,说明boosting集成学习的预测性能明显高于传统决策树算法,基于XGBoost算法得到的大部分交叉验证结果在AUC上的表現比LightGBM要略高。
上述实验结果表明,对于恶意软件感染数据集,结合集成学习算法,经特征工程筛选过后的特征集在预测效果上优于全部特征集的预测结果,此外,集成学习算法的预测效果也远好于传统决策树算法预测效果。利用本文特征选择方法与集成学习算法的结合,可以较好的实现对恶意软件的预测。
4结束语
本文通过特定的特征选择方法和集成学习算法,解决了基于数据集预测恶意软件感染这一实际问题。不仅实现了较为准确预测恶意软件的目标,也找到了影响恶意软件感染的一系列特征,为防治恶意软件提供了部分依据。下一步期望通过进一步优化特征选择过程,或者选择模型融合的方法,实现恶意软件预测的优化过程。
- 农村电商与乡村振兴互动发展的系统动力学研究
- 高速公路现浇箱梁施工过程中成本控制的研究
- 配网规划原则与运维难度的分析
- 关于高压电缆附件的界面压力相关因素研究
- 社会责任视角下绿色金融体系研究
- 体育舞蹈对青少年身心健康影响研究
- 隋唐时期中国汉传佛教建筑探究
- 水库维修养护规范化管理研究
- 10kV 配电房配电设计研究
- 后疫情时代雇主品牌运营为国有企业赋能
- 当前新形势下普法工作举措探析
- 浅谈加油站改造工程安全风险管控
- 简析我国农业技术推广对提升农业种植业的作用
- 地铁行业设备维修维护方式的探究
- 水文与水资源工作面临的问题与对策
- 注册会计师个体异质性与审计质量
- 国际绿色债券的界定标准及启示
- 论当今我国发展的战略机遇期存在的合理性
- 发电厂汽轮机组运行效率的优化
- 高浓瓦斯发电效率探析
- 综合实践活动让低段数学摇摆起来
- 医院保卫处在医患纠纷中的作用探究
- 探讨农村饮水安全水质检测问题
- 浅析新时代下电力企业经济责任审计的程序和方法
- 电网新媒体营销服务渠道现状分析
- patentpending
- patent pending
- patentprotection
- patent proˌtection
- patent right
- patentright
- patents
- patent²
- patent³
- patent¹
- paterist
- paterists
- paterist's
- paternal
- paternalism
- paternalisms
- paternalistic
- paternalistically
- paternalists
- paternality
- paternally
- paternities
- paternity
- paternityleave
- paternity leave
- 褊狭
- 褊狭刻薄
- 褊狭吝啬
- 褊狭忌刻
- 褊狭猜忌
- 褊狭的识量
- 褊狭苛察
- 褊率
- 褊短
- 褊窄
- 褊苣
- 褊薄
- 褊衣
- 褊衫
- 褊褼
- 褊躁
- 褊迫
- 褊逼
- 褊量
- 褊陋
- 褊隘
- 褋
- 褋衣
- 褌
- 褌带