陈绣瑶

摘? 要: 为了提高视频的识别检测速度,提出基于融合特征的网络不良视频识别框架。先分离视频音频,利用MFCC特征匹配筛查部分恐怖视频,减少视频图像提取、识别总量,以达到提高检测速度目的;再通过OpenCV视觉软件库,结合颜色直方图+SURF算法进行视频镜头边界检测及MoSIFT特征、颜色信息等其他视频特征的检测,在保证识别准确率的基础上进一步提升视频检测速率。
关键词: MFCC特征; SURF特征; MoSIFT特征; 镜头边界检测; OpenCV
中图分类号:TP37? ? ? ? ? 文献标识码:A? ? ?文章编号:1006-8228(2020)11-19-04
Abstract: In order to improve the video recognition ability and detection speed, this paper proposes a network bad video recognition framework based on features. Firstly, the video and audio are separated, and MFCC feature matching is used to screen some horror videos to reduce the total amount of video image for extraction and recognition, so as to improve the detection speed. In addition, by using OpenCV, combining with colour histogram and SURF algorithm, video lens boundary detection, and the detection of MoSIFT feature and motion, colour information and other video features are carried out to further improve video detection rate on the basis of ensuring recognition accuracy.
Key words: MFCC feature; SURF feature; MoSIFT feature; Lens boundary detection; OpenCV
0 引言
移动互联网时代,视频分享的规模呈现爆炸式增长,网络视频成了信息传播的重要手段之一。然而,网络视频资源共享為人们提供便利的同时,一些恐暴、色情等不良视频趁虚而入,严重危害青少年的身心健康,成为诱发青少年犯罪的重要因素。我国《宪法》《未成年人保护法》等对不良视频内容明文禁止,广电总局、各地公安局对遏制不良视频内容的传播也采取了相应措施,但收效甚微[1]。因此,如何有效、快速地过滤不良视频,己成为视频分析领域的研究重点。
网络不良视频主要包括恐怖、暴力和色情三种。不良视频的过滤,其关键技术在于视频内容的识别。在视频检测分析的相关研究中,通过查阅已有文献发现,大部分只注重视频的图像信息,忽略了视频的音频及运动信息特征。因此,本文综合各类不良视频的信息特征如音频、运动、纹理及颜色信息等进行视频识别。另外,为了提高视频识别速率,引入了MFCC特征匹配及直方图结合SURF算法的镜头边界检测。
1 基于融合特征的不良视频识别
1.1 不良视频系统识别框架
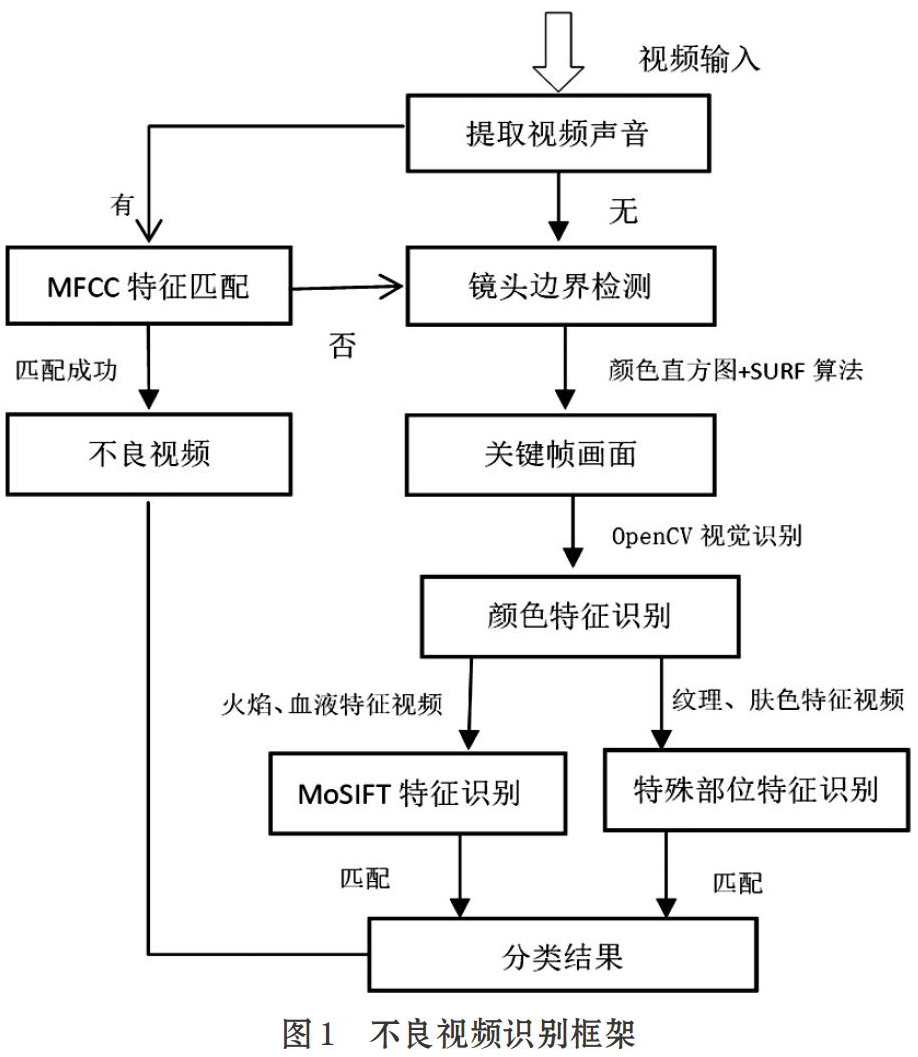
视频识别框架总体思路如图1所示:首先通过视频的音频轨道提取视频背景音乐,进行MFCC特征匹配,判断输入视频是否符合不良视频特征,有的话则直接判别为不良视频,没有则进一步进行视频画面的提取,并根据颜色特征、运动特征及特殊部分等特征进行视频内容识别,直至分类结束。
1.2 基于MFCC特征的视频检测
常用的声音特征提取方法有线性预测倒谱系数LPCC、多媒体内容描述接口MPEG7、梅尔频率倒谱系数MFCC等,其中MFCC是在Mel标度频率域提取出来的倒谱参数,其特征信息不依赖于信号的性质,对输入的信号无任何限制要求,而且利用了听觉模型的研究成果,相比其他方法更具鲁棒性,当信噪比降低时仍然具有较好的识别性能[2]。
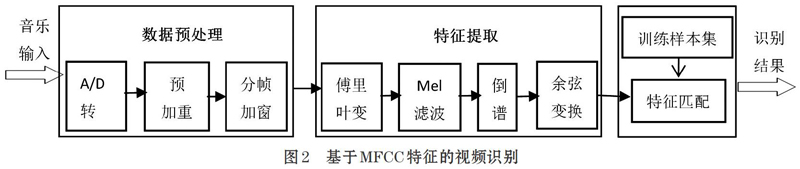
因此,本文采用MFCC方法对提取的背景音乐进行音频特征提取,再利用隐马尔科夫模型(HMM) 算法对提取的特征进行匹配识别,如图2所示。首先提取视频背景音乐,对声音做前期处理:模数转换、预加重和分帧、加窗等操作,预加重的目的是使信号的频谱维持在高低频区间,以达到用同样的信噪比求频谱[3]。“分帧加窗”是将每一帧乘以汉明窗,以增加帧的连续性。接着对各帧信号进行快速傅里叶变换得到各帧的频谱,然后对频谱取模平方得到语音信号的谱线能量,再将能量谱通过一组Mel尺度的三角形滤波器组,对频谱进行平滑化处理[3]。最后经离散余弦变换(DCT)得到MFCC参数向量,利用隐马尔科夫模型( HMM)获取隐藏语音信号背后的字符序列,和已训练好的样本集进行匹配识别,即可得到识别结果。
1.3 融合直方图及SURF特征点的镜头边界检测
常用的镜头边界检测方法包括图像颜色直方图对比、基于图像块的对比、基于像素的对比、基于特征的视频切割以及基于聚类的方法等[4]。其中,颜色直方图是一种全局特征检测方法,通过判断相邻两个图像帧的相似度进行检测。其优点是算法简单、计算迅速,缺点是容易丢失图像的细节信息,导致颜色相似的渐变镜头漏检。
尺度不变特征变换(SIFT)和加速稳健特征(SURF)属于局部特征检测算法:能够较好地弥补渐变镜头漏检问题。其中SIFT特征算法对旋转变换、尺度缩放、亮度变化等保持不变的特性,具有较好的稳定性,但效率低,实时性不高,不适合大量视频的检测。SURF算法采用快速Hessian算法检测关键点,与SIFT算法相似,如图3所示。不同之处在于SURF算法通过特征向量描述关键点周围区域的情况,改良了SIFT算法的特征点提取方式,而且SURF算法采用了Harr小波特征和积分图像的方法,运行效率大大提高,适合用于海量视频的检测[5]。
因此,为了提高视频的检测速度和准确率。整合全局特征检测颜色直方图算法与局部特征检测SURF算法进行视频镜头边界检测及关键帧的提取。对每段视频进行分帧读取,利用颜色直方图的自适应阈值算法对镜头边界识别,再采用SURF 特征点匹配算法对检测后属于同一镜头的视频帧进行二次检测,得出最终的视频关键帧图像[6]。
1.4 基于OpenCV的不良视频颜色特征信息的提取
OpenCV是一个开源的计算机视觉库,提供多种函数及语言接口,能够高效实现计算机视觉算法。利用OpenCV图像处理库RGB模型,将图像分离为RGB三通道,定位血液、火焰的像素位置,利用直方图均衡化处理成二值图像,识别、分割目标像素区域。其中火焰识别比较特殊,其颜色由红色、绿色和蓝色三种颜色组成,单一颜色模型的判据存在较大的误差。因此,在RGB判据基础上,先转换成HSV模式,并添加HIS约束,条件如下[7]。
// HIS约束条件:
Rule1:R[≥]G[≥]B
Rule2:R[≥]RT
Rule3:S[≥]((255-R)*ST/RT)
其中,Rt是红色分量阈值,St是饱和度阈值。为提高火焰识别的准确率,设置两个滑动块,改变Rt和St阈值的大小,选取最佳阀值。
同样的方法,在形成的RGB数据基础上,将RGB图像转换到YCrCb颜色空间,利用openCV自带的椭圆函数生成肤色椭圆模型,相关代码如图4。皮肤像素点分布近似椭圆形状,因此根据CrCb的形状分布,判断像素点坐标(Cr, Cb)是否在椭圆内(包括边界),是则判断为皮肤,否则排除[5,7]。
1.5 基于MoSIFT特征的暴恐视频检测
暴恐视频通常包含大量打斗动作画面,并伴有血液,火焰等特征信息。因此在1.4.1筛选出火焰及血液图像的基础上,使用MoSIFT算法进行跟踪提取。MoSIFT算法能够检测空间上具有一定运动且区分性强的兴趣点,运动强弱由兴趣点周围的光流强度来衡量,方法如图5所示[8,10]。输入相邻两帧图像,通过高斯差分形成多尺度金字塔;接着找出DoG空间中的局部极值点作为SIFT特征点,同时通过光流计算,分析判断是否存在足够的运动信息,提取运动兴趣点;最后将SIFT 特征点与光流相结合,去除与运动无关的兴趣点,提取最终描述运动的MoSIFT特征。
2 实验与分析
为了验证上述识别方法的实时性和准确性,根据以上框架及算法,收集正负样本视频共200份,各視频时长介于10-60秒之间,总时长112分钟。由于色情视频比较敏感,因此以负样本为主进行反验证。得出各类不良视频查准率如表1所示。
另外,在同样实验环境下对比不同的关键帧提取方法的查准率及运行速度,选取K-Means聚类算法与本文的直方图+SURF算法进行识别测试,得出各种类型视频查准率如图6所示。
从图6中数据显示不同的关键帧提取方法查准率比较接近,不同类型视频总的查准率如表2所示,直方图+SURF算法为91.1%,K-means算法为91.4%。但由于直方图+SURF算法不需要反复迭代,因此检测总时长优于K-means算法,如表2所示。
根据实验结果,对于不同类型的视频,总的查准率接近 91%,说明使用的特征匹配得到的结果均较为稳定,也验证了1.1框架算法的鲁棒性。另外,总时长112分钟的视频,56分钟之内完成检测,检测速率接近48F/S,基本上能够满足在线视频检测要求。
3 结束语
从以上实验结果可以看出,本文提出的基于融合特征的网络不良视频识别框架,能够有效地识别暴恐等不良视频,且检测速度优于基于K-Means的边界检测算法,能够较好满足在线检测要求;而且利用MFCC特征提前匹配筛查恐怖视频,减少视频图像提取、识别总量,有效提升视频检测识别速度,能够满足海量视频的检测需求。但从实验结果数据角度看,还存在进一步的提升空间。因此,接下来将会继续改进识别框架,进一步提高视频的检测速度和准确率。
参考文献(References):
[1] 齐振国.视频内容识别算法研究[D].北京交通大学电子信息工程学院,2014.
[2] 邵明强,徐志京.基于改进MFCC特征的语音识别算法[J].微型机与应用,2017.21:48-50
[3] JamesJuZhang.语音特征参数MFCC提取过程详解[EB/OL].2014-01.https://blog.csdn.net/jojozhangju/article/details/18678861
[4] 蔡轶珩,胡朝阳,崔益泽.融合颜色信息与特征点的镜头边界检测算法[J].计算机应用,201737.S2:95-98,111
[5] 王辰龙.基于结构和整合的特定敏感视频识别技术[D].北京交通大学,2015:32-35
[6] 张昊骕,朱晓龙,胡新洲,任洪娥.基于SURF和SIFT特征的视频镜头分割算法[J].液晶与显示,2019.36: 512-516
[7] csdn:https://blog.csdn.net/coldplayplay/article/details/70212483
[8] 米阳,孙锬锋,蒋兴浩.基于联合特征的暴恐视频检测算法[J].信息技术,2016.10:152-155
[9] 陈攀,王泰.一种不良视频检测方法[J].计算机工程,2011.12:386-387
[10] 王文诗,黄樟钦,王伟东,田锐.视频镜头分割与关键帧提取算法研究[J].湘潭大学自然科学学报,2018.4:75-78
- 新形势下探究高校思想政治教育新载体
- 科学运用“十廉”方法 推进干部廉洁从业
- 对基层干部如何做好群众工作的几点思考
- 陈云经济思想研究及其现实价值
- 农村基层党组织建设存在的问题与对策思考
- 论高校学习型党组织的“四型”特征
- 提高党建工作信息化水平研究
- 建筑施工企业基层党建工作创新的探讨
- 农户经营风险与土地适度规模经营的实现
- 关于非公企业对党管人才工作的探索
- 我国刑法中严格责任之体系地位
- 知识产权视角下遗传资源保护探析
- 浅议加强高校基层党支部建设的对策建议
- 构建大学生预备党员与高校基层党组织互动回应机制研究
- 论李大钊与时倶进思想观
- 文化建设中的价值凝炼、价值坚守与价值回归
- 建立经巴基斯坦通向世界的“现代丝绸之路”
- 毛泽东遗物蕴涵的墨家文化精神
- 怀特海共同体思想研究
- 马克思社会形态理论系统研究的力作
- 南疆兵团红枣产业发展面临的困境与出路
- 试论红卫兵运动在延安各地的兴起及其影响
- 兵团“三化”建设中金融支持问题研究
- 浅议创建和谐社区的新思路
- 浅淡如何做好国企工会的维权工作
- insufferableness
- insufferablenesses
- insufferably
- insufficiency
- insufficiency's
- insufficient
- insufficiently
- insufficientness
- insular
- insularisms
- insularities
- insularity
- insularize
- insularly
- insulars
- insulary
- insulate
- insulated
- insulates
- insulating tape
- insulating tapes
- insulation
- insulations
- insulator
- insulators
- 当然
- 当然咯
- 当熊
- 当爪牙
- 当牛马
- 当牢
- 当猴儿耍
- 当猴耍
- 当班
- 当理
- 当璧
- 当生贵子或日后大贵的征兆
- 当番
- 当病授药
- 当皇后,作为天下妇女的榜样
- 当盐不咸,当醋不酸
- 当真
- 当眼
- 当着
- 当着众人打算盘——一是一,二是二
- 当着众人的面商议
- 当着和尚骂秃子
- 当着和尚骂秃驴——自骂自
- 当着对方或大家的面
- 当着真人不说假话