须秋梦 章民融


摘? 要: 为了更好地识别针对大额保险的欺诈行为,总结了大额保险的主要风险类型,明确了大额保险反欺诈系统的主要构建方向。基于Apriori算法提出了大额保险大数据智能反欺诈系统模型,重点分析了数据统计识别、保险欺诈规律挖掘、保险欺诈行为识别。构建的大额保险大数据智能反欺诈系统经实证运行,结果表明,基于Apriori算法构建的大额保险大数据智能反欺诈系统能快速完成对大额保险欺诈行为的有效识别。
关键词: 大数据技术; Apriori算法; 反欺诈系统; 实践
中图分类号:TP311.52? ? ? ? ? 文献标识码:A? ? ?文章编号:1006-8228(2021)07-117-03
Design of big data intelligent anti fraud system for large amount insurance
Xu Qiumeng, Zhang Minrong
(1. PICC Property and Casualty Company Limited Shanghai Branch, Shanghai 200010, China; 2. Shanghai Institute of Computing Technology)
Abstract: In order to better identify the fraud against large amount insurance, this paper summarizes the main risk types of large amount insurance, and defines the main construction direction of large amount insurance anti fraud system. A big data intelligent anti fraud system model for large amount insurance is proposed based on Apriori algorithm, focusing on the analysis of data statistical identification, insurance fraud rule mining, insurance fraud behavior identification. Empirical operation of the constructed big data intelligent anti fraud system for large amount insurance shows that the system based on Apriori algorithm can quickly complete the effective identification of the fraud behaviors against large amount insurance.
Key words: big data technology; Apriori algorithm; anti fraud system; practice
0 引言
大額保险是指投保的保险金额相对较大的人身保险,通常保险金额是在50万以上,投保时需要对其实施契约调查,充分掌握投保人的资产情况,明确投保人的投保动机,身体健康情况等[1]。近年来,在中国经济飞速发展的影响下,国内保险行业迅速崛起,为广大社会群体提供了健康保障。大额保险作为保险行业非常重要的一类产品,具有“避债、避税、传承”的作用,成为了高净值人士投资理财的热门选择,这使得大额保单量持续增加,保额也在不断攀升。
本文拟根据大额保险的特点,基于关联规则挖掘算法的经典算法Apriori算法,设计一套具有较高可行性的反欺诈系统,期望以此降低保险运营成本,营造一个良好的保险行业环境。
1 大额保险大数据智能反欺诈系统模型设计
本文从变量筛选、数据预处理、保险欺诈规律挖掘和行为识别等方面,挖掘数据信息,基于Apriori算法建立大额保险大数据智能反欺诈系统。
1.1 数据统计识别
1.1.1 变量选择
变量筛选主要是从个人行为数据中选择能够反映个人信用的变量。因为互联网上个人行为种类繁多,有些变量能很好体现个人信用度,有些变量则对个人信用的影响不明显。因此,我们需要选择合适变量,才能够准确评价用户的信用度[2]。
大额保险用户大致可分为以下几个方面。
用户数据:包括用户的年龄,性别,婚姻,职业,教育程度,收入情况等。
信用数据:包括用户在银行的征信记录,用户在银行或其他征信公司的征信记录。
交易数据:包括用户的交易金额,交易频率,交易地点,交易账户等。
消费数据:包括用户的消费时间,消费地点,消费习惯,消费金额等。
社交数据:包括用户的好友数量,好友的信用评级,好友的身份特征等。
除此之外变量之间可能存在一定联系,共同反映用户的某种特性,所以我们要尽量从多个维度来刻画用户的特征。
1.1.2 数据预处理
原始数据集常规情况下很难直接将其作为系统数据来源,针对该情况,必须对所收集到的数据作出相应的处理,以确保建模和统计处理的相关要求。
1.2 保险欺诈规律挖掘
保险欺诈尽管花样百出,但保险公司有丰富的经验和积累了丰富的数据,那么就能够结合数据掌握其具体规律。目前,不少的保险公司,针对大额保险的欺诈处理,多以保险人员个人的经验为主,并从中总结出相应的规律。
大额保险所出现的欺诈行为分析指标主要包括了欺诈特征、行为特征指标两个部分,抽取其中的一部分的指标用来对Apriori算法进行演示。
1.3 保险欺诈行为识别
经由保险公司的信息系统数据库来进行数据的构建,在对传统分析模型进行使用的过程中,结合Apriori算法数据关联挖掘技术,对欺诈行为进行分析、识别和评价。借助欺诈行为发生风险、可能性和成本、指数的分析,总结出一套相应的欺诈风险评价结果,并基于提出反欺诈风险管理策略与监督管理体系。
考虑到保险欺诈行为的识别业务的特殊性,如果将保险欺诈的挖掘业务模式应用与保险欺诈行为的识别业务中是不可行的。为此,本文在进行欺诈行为识别业务过程中,首先提出了先分布、然后再集中的流程处理模型。保险欺诈行为的详细识别业务模型如图1所示。各个保险公司首先将内部数据库中的业务数据进行数据预处理,所有的公司处理后的数据结构应该是一致的。
2 大额保险大数据智能反欺诈系统实证分析
2.1 数据预處理及描述
本文基于Apriori算法构建大额保险大数据智能反欺诈新系统,具体的操作步骤如下。
首先扫描整张事务数据库D,设置一个最小支持度Smin,根据最小支持度Smin产生第一个频繁项集S1;由S1执行连接和剪枝操作,产生候选项集的集合,并根据Smin产生频繁项集S2;接下来再由S2产生S3;这样的操作一直进行下去,直到Sk成为空集时结束。
根据聚类分析中运行效率高低的类别,所有的事务也可以分为五大类。对这五类数据分别使用Apriori算法,找到各自情况下的主要影响因素。所以频繁项集的最小支持度满足:
[Sminn
公式⑴中,[An]主要用于表示第n类运行效率的事务集;[Sminn]主要用于对该事务集的频繁项集的最小支持度进行表示。
每个影响因素都产生五个“项”,假设最终数据产生的项为B1, B2,B3,B4, C1, C2,C3,D1,...,扫描整张数据表格,根据最小支持度Smin找到第一个频繁项集的集合;在此基础上,连接下一个项,产生含有两个项的候选项集(例如:B1BC2,B1BC3,C2D2,...);剪枝后根据最小支持度得出第二个频繁项集的集合。以此类推,直到最后产生的频繁项集是空集。最终,该算法一共得到五个频繁项集。
该算法分别找出了可以欺诈行为风险高、较高、一般、较低、低的频繁项集。在这些项集中,所有出现的疑似欺诈行为,都是导致大额保险管理风险的主要影响因素。
2.2 大额保险大数据智能反欺诈系统实证结果
2.2.1 系统主体业务流程
系统的主体业务流程分为四个阶段:
Step1:数据抽取,系统通过把各个保险公司的大额保险业务数据集合起来并进行预处理,然后把保单数据保存至汽车保险反欺诈系统的中央数据库。
Step2:数据加工,大额保险反欺诈系统的核必系统通过这些数据进行挖掘,发现其中的规律,并将规律与数据进行保存。
Step3:数据查询,当各个保险公司的业务员在建立保单时,需要通过大额保险的反欺诈系统进行风险分析,以确定该保单是否接受,当投保人要求理赔时,可以根据分析结果来确定是否应该赔付与赔付的具体额度。
Step4:数据保存,对于风险特别高的数据,业务员应该保存到大额保险反欺诈系统中。
2.2.2 试验结果
将已有的数据分别分为训练集和测试集两个部分,训练集用于反向传播训练系统,测试集用来检验系统输出的误差与精度。将所有数据循环处理一次,时间在0.5s左右,此时的测试误差约15%;循环处理100、1000、2000次系统的预测精度会有明显的提升。最终将2000次循环后的结果等价为:运行效率与其主要影响因素的定量关系。
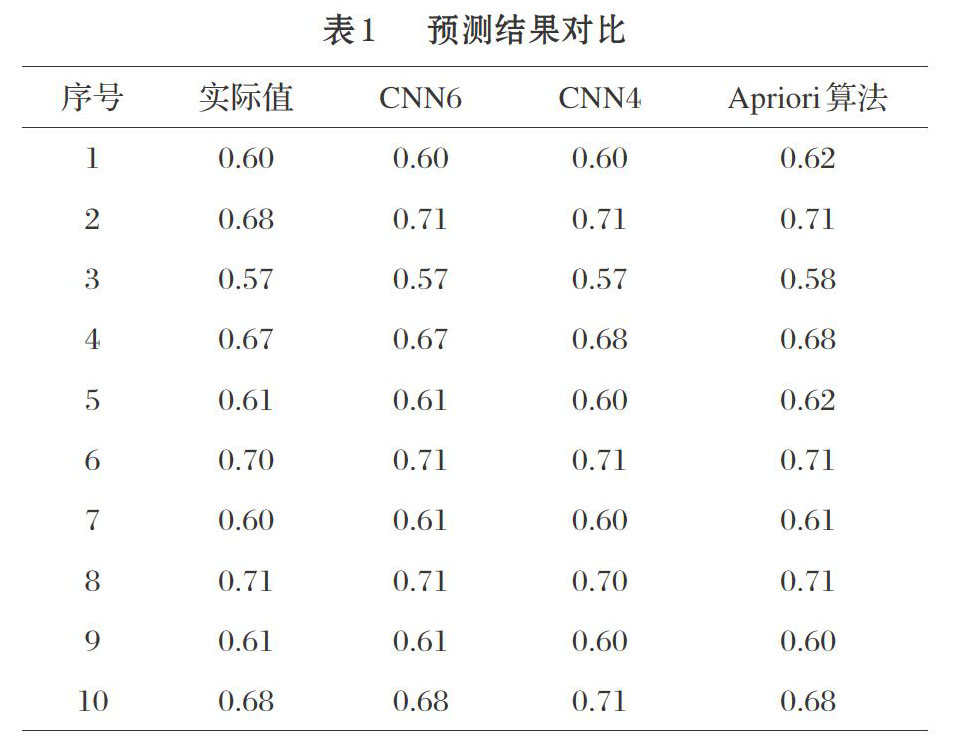
将提取主要影响因素的训练结果(CNN4)、不提取主要影响因素的结果(CNN6)以及使用Apriori算法的结果放到一张表中进行对比,结果见表1。
从表1对比结果来看,Apriori算法考虑全部影响因素的运行效率预测值误差为0.98%;而仅考虑主要影响因素的预测误差0.71%,预测精度都很高,都可以很好地预测运行效率值。
本系统已经在某财险的部分分公司与某保险的部分分公司试运营,通过半年内的152件减损与拒赔的案件的处理,总共为保险公司减损或拒赔的金额达9638.84万元。
3 结束语
近年来,我国各个地区保险欺诈事件的频频出现,且发生率日渐明显。面对这种层出不穷的欺诈行为,保险人士很难经由个人经验来进行有效识别,但随着大数据技术的发展,基于Apriori算法就能够实现对各项数据的关联处理,从而快速完成对大额保险欺诈行为的有效识别。为了能够尽可能地减少欺诈案件,推动社会资金的合理分配与保险行业的正常发展,本文基于Apriori算法构建起了大额保险大数据智能反欺诈系统,较好的实现对现阶段大额保险欺诈行为的有效识别,但该系统还存在一定的局限之处,还需要借助数据挖掘技术对各项业务数据做进一步的挖掘,提高系统运作的有效性。
参考文献(References):
[1] 白浩,袁智勇,孙睿等.基于Apriori算法和卷积神经网络的配电设备运行效率主要影响因素挖掘[J].电力建设,2020.41(3):31-38
[2] 翟继强,马文亭,肖亚军.Apriori-KNN算法的警报过滤机制的入侵检测系统[J].小型微型计算机系统,2018.39(12):2632-2635
- 如何完善集团公司对子公司内部控制的措施
- 温州南麂岛景区游客满意度提升研究
- 工业反哺农业视角下精准扶贫的“互联网+”模式探析
- 基于企业内控视角下的全面预算管理工作分析
- 关于投标保证金管理中存在问题及建议的思考
- 医院财务内部控制的问题与对策
- 城市轨道交通运营成本管理研究
- 目前县级财政监督检查工作存在的问题和建议
- 国有资产清查及管理建议
- 集团管控模式下国企内部审计的问题与对策研究
- 试论作业成本法在制造企业成本管理中的应用
- 固定资产管理的问题与分析
- 基于“营改增”背景下事业单位涉税问题探讨
- “商誉及其减值”相关问题的思考和建议
- 我国国有企业绩效评价与财务评价的相关性研究
- 专利证券化概述
- 城乡融合视野下台州市小城镇发展研究
- 我国居民家庭保险规划现状及问题调查研究
- 明股实债金融工具会计确认及风险防范问题的探讨
- 论小微企业融资问题
- 高等学校实施政府会计制度工作流程简析
- 管理会计在国有企业中的应用
- 财务共享服务中心下高校财会专业学生的发展方向与提升路径
- 信息化时代下医院门诊收入账务处理研究
- 管理会计在电力企业成本控制中的应用探讨
- plateaus
- plateaux
- plated
- plateful
- platefuls
- plate glass
- plate glasses
- plateless
- platelet
- platelets
- platelike
- plates
- platesful
- plate tectonic
- plate tectonics
- plate-tectonicses
- plate tectonicses
- platform
- platformless
- platform-neutral
- platformneutral
- platform's
- platforms
- platinum
- platinums
- 酸痛剧烈的样子
- 酸的气味
- 酸碱平衡
- 酸秀才
- 酸笋鸡皮汤
- 酸箕
- 酸而甜
- 酸耿
- 酸腐
- 酸臭
- 酸臭的陈淘米水
- 酸苦
- 酸薄
- 酸蛋
- 酸衷
- 酸论
- 酸败
- 酸赭
- 酸软
- 酸软倦怠
- 酸辛
- 酸辣
- 酸辣辣
- 酸迂
- 酸透、酸透