朱革 余浩源 王先全 周锡祥
摘要:随着互联网的迅速发展普及以及手机App的快速壮大,服务器需要承受的用户访问量变得越来越大,加上现在用户对上网体验的重视,这些都对当前服务器设计提出了新的挑战。单一服务器架构已经不适合用来承受高并发请求,前几年流行的SSM框架能通过集群提高性能,但单体应用不适合做大型系统,且仅通过服务器集群带来的性能提升也会遇到瓶颈,故需要新的架构来满足当前的需求。从集群、分布式、数据库几个方面入手对服务器设计进行分析,提出适合高并发环境的服务器架构。
关键词:高并发;集群;分布式;架构
中图分类号:TP311? ? ? 文献标识码:A
文章编号:1009-3044(2021)12-0069-04
Abstract: With the rapid development and popularization of the Internet and the rapid growth of mobile phone apps. The server has to bear more and more user visits, and now users attach importance to the Internet experience, which all pose new challenges to the current server architecture. The single server architecture is no longer suitable for handling high concurrent requests, The popular SSM frameworks of the past few years can improve performance through clustering, but monolithic applications are not suitable for large system, and the performance improvement only through server clusters will also encounter bottlenecks, therefore, a new architecture is needed to meet the current needs. Analyze server design from the aspects of cluster, distributed, and database, and proposes a server architecture suitable for high-concurrency environments.
Key words: high concurrency; cluster; distributed; framework
1 背景
互联网发展初期对服务器的要求不高,通常在一台服务器上搭建服务就能够满足需求,随着上网人数的增多以及网速的提高,服务器需要承受的压力也越来越大。比如淘宝在双十一凌晨0点的时候所承受的访问量巨大,12306铁路购票网站曾经就出现过由于服务器压力过大系统崩溃的情况,解决服务器在高并发情况下的性能低下问题是必要的。增强服务器的并发能力除了提升硬件性能,参数调优等方式外,还能通过优化服务器的架构来提高系统的性能,增强系统的容灾性与稳定性。本文从集群、分布式、数据库等方面来对服务器架构设计进行分析,为高性能服务器的设计提供一种可行的方案。
2 架构优化的必要性
对服务器性能进行提升有多种方式,进行硬件的升级是最为简单的方式,但这种方式成本高且不能从根本上解决问题[1]。对单体应用进行集群部署能有效地提高系统的并发能力与稳定性,但单体应用存在着不易迭代及部署效率低等问题,并发到了一定程度仅靠集群并不能完全解决性能问题,此时就需要从其他部分进优化,单靠某一个技术无法满足需求,所以需要对服务器架构进行设计。
3 设计方案
在实际的使用中,影响服务器性能的因素有很多,架构的不同会使服务器的性能有很大的差距。本节主要从集群、分布式的使用以及数据库方面进行分析。
3.1 使用服务器集群
客户端发送多个请求到单个服务器,服务器对请求进行处理并且连接数据库,处理完毕后再将结果返回到客户端。这种架构的成本低,代码编写也较为简单,是比较适合早期并发较少的情况的。但随着现在请求并发变得越来越大,如果想要继续采取单一服务器来处理请求,就得提升服务器的性能,随着摩尔定律[2]逐渐失效,硬件性能的提升已经跟不上需求的提升,就算不考虑成本将硬件的配置提升到最好仍然不能满足需求,那通过提升硬件配置这条纵向解决问题的道路就走不通。服务器集群[3]这种通过横向增加服务器数量的方式就正好能够解决这个问题。
3.1.1 服务器集群的作用
服务器集群就是将多个做同种服务的服务器集中起来,利用多个计算机来进行并行的计算以提高性能,每个服务器是一個节点,所有节点构成了集群[4]。当单个服务器处理高并发请求遇到瓶颈的时候使用集群可以提升系统的处理能力,当集群的性能不够时也可以适当增加节点数量。对客户端而言,访问服务器的集群就和访问一个服务器是一样的,客户端不用专门为此做配置。
3.1.2 用负载均衡服务器搭建服务器集群
服务器集群是由多个服务器组成,但是用户的请求到底由哪个服务器来进行处理,需要一个调度者来进行调度,这个调度者就是负载均衡服务器。用户的请求先发送给负载均衡服务器,然后服务器再根据相应的设置以及当时负载的情况,来选出一个合适的节点对请求进行处理。
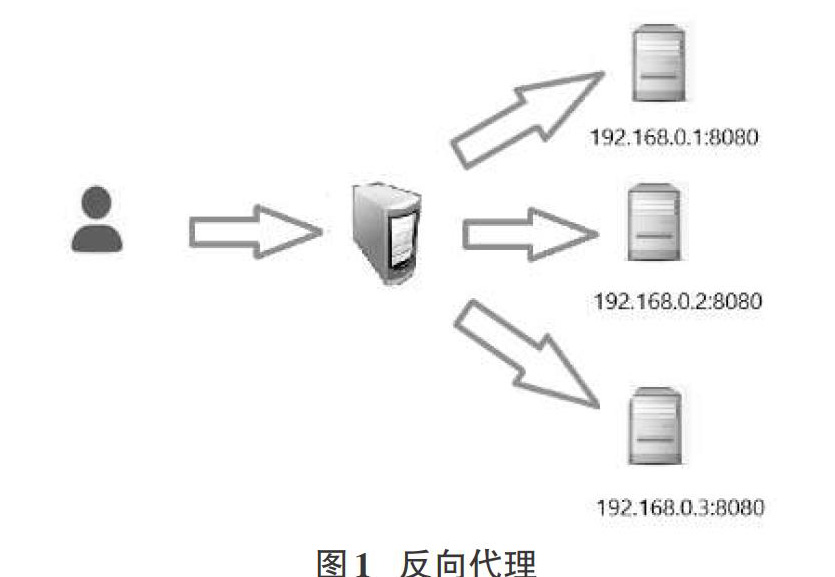
本文选用Nginx作为负载均衡服务器,它可以通过反向代理来实现软件负载均衡,反向代理时客户端不需要做任何配置[5]。如图1所示客户端对代理是无感知的,请求发送到了反向代理服务器,由反向代理服务器去选择目标服务器,从目标服务器获取返回的数据后再返回给客户端,客户端访问的实际是代理服务器的地址,而不是直接访问的被隐藏了的真实服务器地址。
使用Nginx作为负载均衡服务器首先需要对其配置文件nginx.conf进行修改,在http块中添加:
upstream myserver {
server 192.168.0.1:8080;
server 192.168.0.2:8080;
server 192.168.0.3:8080;
}
表示使用默认的负载均衡策略轮询将请求分配给三个服务。然后将http块里的server部分修改为:
server{
listen 80;
server_name localhost;
location /{
proxy_pass http://myserver ;
}
......
其中listen为监听的端口,server_name为监听的地址,proxy_pass则为请求的转向,值为前面upstream定义的服务器列表。除轮询外常见的负载均衡策略还有Weight、ip_hash、fair、least_conn等。
3.2 采用分布式架构
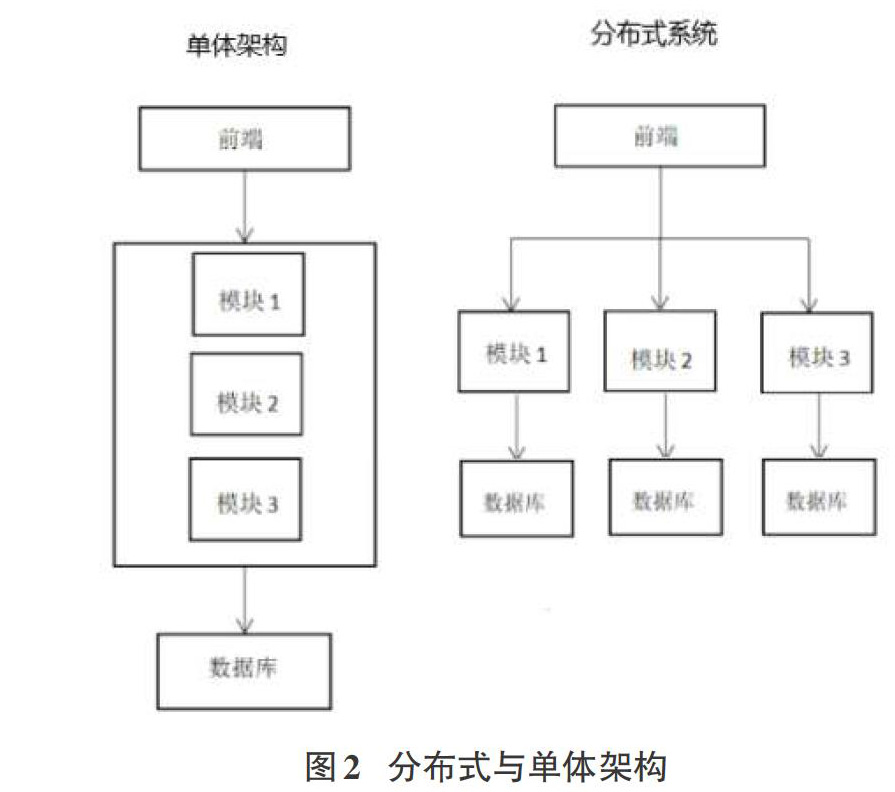
前面讲了通过服务器集群来提高性能,当访问量越来越大,单一应用增加服务器数量所带来的性能提升变得越来越小,这时候就需要用到分布式架构了,从图2中可以看出一般服务器集群中的单体架构和分布式系统间的区别。
分布式与集群相比,分布式是一种工作方式而集群则是一种物理形态。将同一个业务放到不同的机器上以提高性能与可用性就能称为集群,而分布式则是将不同的业务或者一个业务拆分成多个子业务部署到不同的服务器上通过交换信息的方式来进行协作[6]。分布式是通过缩短单个任务的执行时间来提升工作效率,集群则是通过提高相同时间并行执行的任务数量来提高效率的,所以当增加集群服务器数量提升的性能有限时可通过分布式来提升性能。
3.2.1 微服务的概念
简单地来说微服务[7]就是很小的服务,甚至功能可以单一到只做一件事,一个操作。单体应用将它的所有功能放在一个进程里执行,能够在多个服务器里复制这单体应用实现扩展。而微服务则将它的每个功能元素放在不同的服务中,通过跨服务器的分发这些服务进行扩展,对需要进行复制的功能元素进行复制也可以实现性能提升。
分布式也属于微服务,两者的概念比较相似但是也有一些差别。分布式是一种让分散的机器相互协助完成业务的手段,微服务相比一般的分布式则对服务进行更细粒度的切分,使得整个系统更加易于迭代且并行度更高。
3.2.2 分布式服务中应解决的问题
在微服务架构中随着功能模块的增多,代码和配置文件變得越来越冗杂,为解决这个问题可使用Spring Boot来快速构建微服务应用,它能帮助开发者解决开发中大部分的配置问题,大部分配置都可以用java类加上注解来代替。Spring Boot能简化Spring的开发,它为Spring整合了许多第三方技术,去繁从简约定大于配置,十分适合微服务开发[8]。它的特点有:
1)能快速创建独立运行的Spring项目以及集成了主流的框架。
2)拥有内嵌的Servlet容器,方便运行。
3)简化了Maven配置。
4)无代码生成,不需要配置XML文件。
5)有大量的自动配置,简化开发,当然也能修改默认值。
微服务虽然带来了许多好处,同时也使得运维变得更加复杂,监控更加困难,分布式的复杂性也提高了。比较明显的几个问题是:
①服务间的调用问题。各个服务间实现调用需要知道服务所在的地址,服务不会放在固定的机器上,故不能将要调用的目标服务地址写死在配置文件里。
②配置问题。微服务要将单体服务中的业务拆分成多个粒度较小的子服务,这样就会导致系统中出现大量的服务,如果仍然为每个服务都提供单独的配置文件则会出现配置信息冗余。
③系统的稳定性问题。由于微服务间的调用是链性的,如果在整个调用链中某个服务出现了问题则整个系统则会雪崩式瘫痪。
3.2.3 分布式服务设计
分布式服务中存在的问题使其构建变得复杂,可以使用Spring Cloud[9]来解决这些问题,它提供很多工具用来进行分布式系统的构建,比如:服务发现,配置管理,熔断,微代理,智能路由,控制总线,全局锁,一次性token,决策竞选,分布式session,集群状态等。
Spring Cloud Alibaba[10]是阿里巴巴推出的解决方案,使用其中的Nacos、Sentinel、Seata组件来解决前面所提到的问题。
服务间调用的地址问题可以使用Nacos中的服务注册发现来解决,在服务的配置中添加如下代码:
spring:
application:
name: provider
cloud:
nacos:
discovery:
server-addr: localhost:8848
该配置指定了Nacos的地址以及该服务的服务名。
将服务提供者注册进Nacos后,服务消费者可以用restTemplate或OpenFeign等来请求调用该服务中的功能。其原理是在服务器启动的时候会将服务器的服务地址通信地址等用别名注册进注册中心,而另一边服务的消费者则以该别名在注册中心中获取到服务的真实通信地址。
配置问题同样也可以使用Nacos来解决,使用其配置管理功能来充当配置中心。需要注意的是在使用配置中心管理配置时,springboot的配置文件需要使用bootstrap.yml,这是因为在项目初始化时需要保证配置先从配置中心拉取,拉取配置后项目才能正常启动,application.yml是用户级的资源配置项,而bootstrap.yml是系统级的,优先级更高。
bootstrap.yml中相关配置代码写法:
spring:
application:
name: config
cloud:
nacos:
discovery:
server-addr: localhost:8848
config:
server-addr: localhost:8848
file-extension: yaml
group: DEV_GROUP
namespace: 077e4037-3b40-4d4a-801e-c8d
4012a815f
使用Sentinel从流量切入,在流量控制、熔断降级等维度来维持服务的稳定性。流量控制是监控应用流量的QPS或并发线程数来避免瞬时高流量冲垮服务器。熔断就好比保险丝,当请求满足设定的异常条件就会熔断掉服务,而不是一直等待到此服务超时。降级则是对服务进行有策略的降级,可以理解为保证核心业务正常运行的兜底方法。
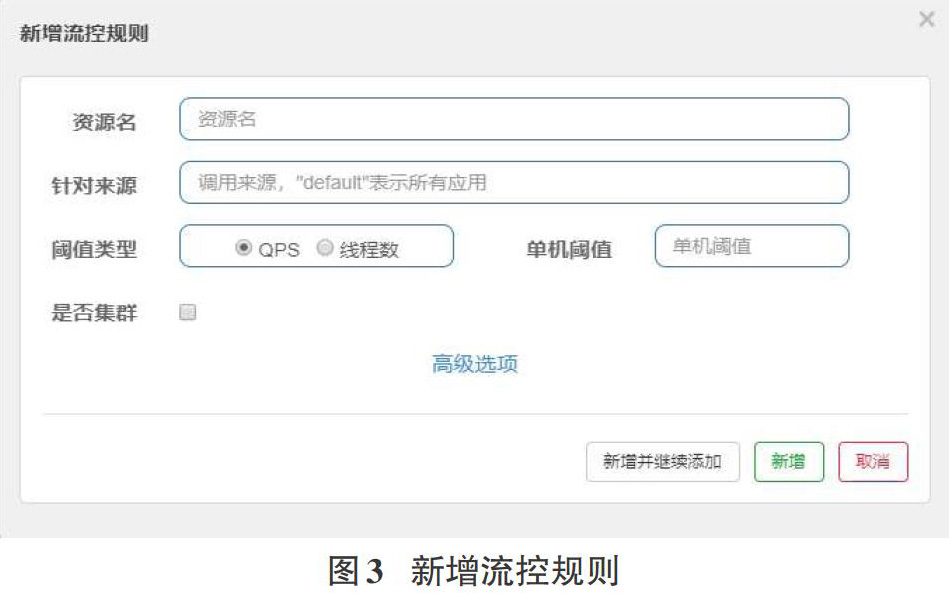
启动好Sentinel与服务并且进行过一次请求后登录Sentinel控制台就可以看到相关服务并且对其进行控制。图3为新增流控规则的面板,可以看到阈值类型有QPS和线程数两种,QPS是指当调用该api的QPS达到阈值的时候,进行限流。线程数则是当调用该api的线程数达到阈值的时候,进行限流。
新增降级规则的面板为图4,降级策略有RT、异常比例以及异常数。RT为平均响应时间,满足平均响应时间超出阈值且在时间窗口内通过的请求数大于一定值两个条件时触发降级。异常比例和异常数则分别是发生异常的比例和异常的个数超过阈值时触发降级。
3.3 数据库优化方案
在高并发的环境下,对数据库的操作频繁,如果只对单实例数据库进行简单的操作无法支撑系统的正常运行,所以需要对数据库的使用进行设计。
3.3.1 索引优化分析
数据库执行查询语句时会根据条件进行全表扫描,正确的使用索引可以提高查询的效率[11]。索引的本质是数据结构,它能够帮助数据库高效的获取数据,但其本身也会占用磁盘空间。使用索引时每次对表进行更新操作时需要更新索引,故会降低表的更新速度。当表的数据特别多时,索引能带来的性能提升会降低,这就需要合理的设计索引,以免影响性能的提升甚至带来负面效果[12]。
索引在使用中也需要注意避免索引失效,在mysql中可以使用explain关键字来看mysql如何处理sql语句,其使用方法是Explain + SQL语句:
EXPLAIN SELECT * FROM t1,t2,t3 WHERE t1.id=t2.id AND t2.id=t3.id
圖5为执行Explain的结果,可以看到内容并不是一般查询语句的格式。其中各个字段都有其含义:
1)id:查询序列号,表示查询中执行的顺序,值相同则从上往下执行,值不同则id越大的越先执行。
2)select_type:查询的类型。
3)table:此行数据与哪张表相关。
4)type:表示访问的类型,较为重要的一个指标,能显示出数据库引擎查找表的方式。
5)possible_keys:可能应用在这张表上的索引。
6)key:实际使用的索引。
7)key_len:索引中使用的字节数,检查是否充分利用上了索引。
8)ref:索引被使用的列。
9)rows:显示mysql认为执行查询时需检查的行数。
3.3.2 读写分离
一个系统对数据库的读写需求通常不同,让单一数据库处理读和写操作可能会使其承受的压力过大。可以使用主从复制来实现读写分离,让主服务器只执行写操作,从服务器执行读操作,以此分散服务器的压力[13]。
如图6所示,主从复制的原理是从数据库slave通过读取主数据库master的binlog然后执行一遍master执行过的操作从而达到主从同步的效果。可以将其中的过程分为三个部分:1)master将每个会改变数据的操作串行的记录进二进制日志binlog中,将这些记录称为二进制日志事件。2)slave从master拷贝二进制日志事件到它的中继日志中。3)slave按照顺序执行中继日志中的事件,将master的改变应用到自己的数据库中。
3.3.3 分表存储
在数据量特别大的情况下,数据库的读取性能会有较大的降低,为了解决这个问题可以将一张表的数据拆分到多张表上存储[14]。
切分有垂直切分与水平切分,根据业务对表进行分类然后分布到不同的数据库上,这属于对数据的垂直切分。切分时可按照模块进行分类,有时也可以根据数据量的大小来切分。垂直切分并不会缩表,所以依然存在着单库的瓶颈,这时就需要用到水平切分。水平切分是根据某个字段的一些规则将原本放在一个表里的数据放在不同的数据库里,就相当于对表按照数据行来进行切分。
随着数据量的增大,先对表进行水平切分,此时利用多块硬盘来提升IO性能与存储空间,成本比较低。数据库到了需要垂直切分的阶段,此时修改数据库结构的主要原因已经不是数据量而是整个业务系统不能承受压力了。若过早对数据库进行垂直切分需要重新构建业务系统,工作量大,而水平切分不需要对业务做大量修改,所以在实际应用时建议先考虑水平切分,然后再做垂直切分。
4 结束语
高并发服务器的设计需要从多方面考虑,若某个部分出现短板就会影响整体性能。本文从服务器集群、分布式、数据库几个方面入手设计服务器架构,以提升服务器的可用性与并发性能。提高服务器性能的方式并不唯一,且不同的使用情景需要不同的架构,除了文中的方案外,还可从其他部分优化,比如使用缓存、动静分离、对热点部分进行优化、对表的设计进行优化、对jvm等参数进行调优、使用CDN等等。互联网正在高速发展,这使得高并发的场景变得越来越多。虽然各自解决高并发问题使用的技术各不相同,但是遇到的各种问题有很多都是类似的,故能够对别人的解决方案进行参考,然后找到自己解决问题的思路。希望本文提供的方案能够有助于大家对高并发服务器搭建知识的学习。
参考文献:
[1] 王亚楠,吴华瑞,黄锋.高并发Web应用系统的性能优化分析与研究[J].计算机工程与设计,2014,35(8)5:2976-2981.
[2] 逄健,刘佳.摩尔定律发展述评[J].科技管理研究,2015,35(15):46-50.
[3] 吴海明.基于Linux高可用性负载均衡集群技术的研究与应用[J].科技创新与应用,2018(36):17-18.
[4] 李海军.服务器集群技术综述[J].电脑知识与技术,2013,9(22):5018-5020.
[5] 刘金秀,陈怡华,谷长乐.基于Nginx的高可用Web系统的架构研究与设计[J].现代信息科技,2019,3(11):94-97.
[6] 金磐石.分布式架构在银行核心业务系统的应用[J].计算机系统应用,2017,26(6):46-52.
[7] 赵然,朱小勇.微服务架构评述[J].网络新媒体技术,2019,8(1):58-61,65.
[8] 熊永平.基于SpringBoot框架应用开发技术的分析与研究[J].电脑知识与技术,2019,15(36):76-77.
[9] 周永圣,侯峰裕,孙雯,等.基于SpringCloud微服務架构的进销存管理系统的设计与实现[J].工业控制计算机,2018,31(11):129-130,133.
[10] 方永敢.微服务架构的研究及小区生活服务平台的实现[D].成都:电子科技大学,2020.
[11] 母凤雯.数据库索引技术概述[J].电脑知识与技术,2017,13(25):9-11,13.
[12] 王丽娟,靳继红.基于MySQL的查询优化技术研究[J].电脑知识与技术,2017,13(30):35-36.
[13] 刘建宏.MySQL数据库优化与集群[J].数字通信世界,2017(7):47.
[14] 韦美雁,段华斌,周新林.大数据环境下的MySQL优化技术探讨[J].现代计算机(专业版),2018(30):68-72.
【通联编辑:谢媛媛】
- 感染期和非感染期先天性耳前瘘管患者行手术治疗的临床效果比较
- Nd:YAG激光在单根管联合Vitapex糊剂治疗根尖周囊肿中的应用效果
- 小切口囊外摘除术治疗老年性白内障的临床效果
- 唑来膦酸联合化疗治疗非小细胞肺癌骨转移的临床效果
- 腹腔镜下腹主动脉旁淋巴结切除术在妇科恶性肿瘤患者中的应用效果
- 参苓白术散联合化疗对结直肠癌免疫功能及生活质量的影响
- 切开复位钢板内固定在桡骨远端不稳定骨折患者中的应用
- 人工关节置换术与内固定术治疗老年股骨转子间骨折的效果比较
- 超声电导局部透药在肘关节“恐怖三联征”术后康复中的应用
- 重复经颅磁刺激在精神分裂症长期住院患者中的应用
- 认知行为联合草酸艾司西酞普兰治疗抑郁症的效果
- 依达拉奉联合长春西汀注射液治疗急性脑梗死的临床效果
- 阿奇霉素联合头孢噻肟钠对慢性阻塞性肺疾病患者肺功能的影响
- 小切口甲状腺手术治疗甲状腺良性肿瘤的临床效果
- 经鼻高流量湿化氧疗在慢性阻塞性肺疾病急性加重期患者中的应用效果
- 左氧氟沙星治疗耐多药肺结核的效果与安全性
- 补肺活血胶囊治疗慢性肺心病的临床效果
- 噻托溴铵联合福莫特罗吸入治疗慢性阻塞性肺疾病的临床效果
- 血糖对永久性起搏器植入术患者首次植入起搏参数的影响
- 急性脑梗死中治疗性无症状出血转化的研究进展
- 炎症性肠病中活性氧及抗氧化的研究进展
- (1,3)-β-D-葡聚糖实验干扰因素的研究进展
- 糖尿病健康管理的研究进展
- 右美托咪啶对喉罩全麻小儿腹腔镜手术脑电双频谱指数和血流动力学的影响
- 能谱CT下痛风尿酸盐沉积定量与血尿酸水平相关性研究
- underofficers
- underofficial
- underopinion
- underopinions
- under orders/instructions
- underorganization
- underorganizations
- underoxidize
- underoxidized
- underoxidizes
- underoxidizing
- underpacking
- underpackings
- underpaid
- underpain
- underpains
- underpan
- underpant
- underpants
- underpantses
- underparted
- underparticipation
- underparticipations
- underpartner
- underpartners
- 驌騻
- 驍
- 驎
- 驎角
- 驎骥
- 驏
- 驐
- 驒
- 驒騱
- 驓
- 驔
- 驕
- 驕傲
- 驕美
- 驕驁
- 驖
- 驗
- 驘
- 驙
- 驚
- 驚女
- 驚霧
- 驛
- 驞駍
- 驟