

摘 要: 随着社交网络普及,社交网络的数据获取成为首先要解决的问题。针对如何获取社交网站的数据,提出了基于API和网络爬虫的两种方法。通过采取对比试验,分别用两种方式在单位时间内抓取微博,比较抓取的微博条数。实验结果表明,基于API抓取的速度比较快,但是稳定性和数据完整性欠佳;基于网路爬虫方式抓取的速度比较慢,但是稳定性和数据完整性较好。最后提出通过采用两种方式相结合的方式,能够进一步提高抓取效率。
关键词: 新浪微博; 数据挖掘; Android SDK; 新浪API; 网络爬虫; 信息采集
中图分类号: TN911?34; TP311.5 文献标识码: A 文章编号: 1004?373X(2015)04?0025?05
根据中国互联网络信息中心(CNNIC)发布了第33次《中国互联网络发展状况统计报告》指出:社交网站的整体覆盖率为61.7%,中国互联网用户总数已经达到6.18亿,互联网的渗透率已经达到67.8%。其中微博等社交网络的使用规模为2.81亿,网中微博的使用率[1]为45.5%。
社交网络的使用率越来越高,微博等社交应用在越来越流行。微博相比传统网络的应用形式而言,微博的信息传播速度更快,覆盖人群大,更新更加频繁。因此,如何有效的采集微博应用中的各种信息,对于分析数据的隐性特征,研究用户的偏好,用户的个性化推荐以及趋势的预测具有非常重要的意义。
传统的微博类数据挖掘方法有两种:
(1) 通过网络爬虫抓取信息,比如周立柱等人提出网络爬虫方案[2],但爬虫的效率不是很高,抓取的数据量比较少,同时必须绕过新浪微博的模拟登陆,才能有效采集新浪微博的数据。
(2) 黄延炜等人研究的利用网络数据采集设备直接截取微博在网络中的传输数据[3],这种方法和网络爬虫相似,效率不高,对数据的提取过程十分复杂。
本文主要立足于如何获取新浪微博上的数据展开研究:采取两种方法来获取新浪微博上的数据。第一种方法是基于微博第三方应用接口的(API),对接口编程获取数据。第二种方式是采用网络爬虫的方式,基于NodeJS实现的网络爬虫。最后比较两种方式采取数据的优缺点,进一步优化微博的采集方法,提出两种方法相融合的方法。
1 基于新浪API 的方案
对于获取社交网站数据,可以通过第三方应用平台接口(API)来获取社交网站上的数据。在使用微博官方API之前,必须要接入微博应用,成为微博的开发者,在创建完应用之后,系统会返回给一个AppKey和AppSecret。App Key是应用的惟一识别标志,微博开放平台通过App Key鉴别应用的身份。App Secret 是给应用分配的密钥,保证应用来源的可靠性[4]。
1.1 Oauth2认证
调用新浪微博的API必须通过新浪微博的用户认证。现在新浪微博的用户认证采取的是Oauth2的认证(见图1)。Oauth2认证简化了之前的繁琐的Oauth认证,同时安全性也得到很大的提高,是用户未来的主要授权认证方式。现在国内主流的社交网站的授权方式都采用的是Oauth2。Oauth2认证过程为:
(1) Client发送Authorization Request给Resource Owner(个人),然后Resource Owner会返回一个Authorization Grant码给Client。
(2) Client 拿到Authorization Grant后向Authorization Server(认证服务器)发请求,接着Authorization Server会返还一个Access Token 给Client。
(3) Client拿着Access Token去访问Resource Server(资源服务器),Resource Server会把相应资源给Client。
1.2 接入API
常规的接入新浪微博应用主要有三种方式:
(1) 网站接入:微连接是微博针对第三方网站提供的社会化网络解决方案。为第三方网站提供用户身份系统及社交关系导入。
(2) 站内应用:站内应用能使你的Web类应用最快地融入微博,提升用户体验,应用将以http://apps.weibo.com/个性域名的地址被用户访问到,并可深度整合微博众多推广资源。
(3) 移动应用:移动应用开放平台为第三方提供了简便的合作模式,满足了手机和平板电脑用户的需求。
移动应用接入方式有以下优势:在移动设备上和PC上调用的API是相同的,但是移动设备有专门的Android SDK,更方便实验环境搭建;同时在移动设备上搜集数据对于后续的实验也提供了方便。因此实验选择了移动应用接入方式:
SDK是软件开发工具包,它是对新浪API的一层封装。首先新浪官方网站上下载Android SDK,现在最新的版本是V2.5.0。Android SDK内部已经实现了Oauth2认证,SSO认证等多种方式。SSO认证方式是指通过自己的应用唤醒手机上的客户端进行授权登陆操作,开发者并不需要知道授权的机制。在实验方案中,并没有使用SSO认证方式,因为SSO认证需要一定的依赖性,移动设备上必须安装微博客户端。
使用Android SDK 实现Oauth2 认证流程如下:
(1) 把下载的下来的Android SDK包解压,在demo?src文件夹下面的weiboSDK ,和自己的项目工程引入开发环境中。
(2) 在Android工程的AndroidManifest.xml文件中增加所需要的文件权限。
(3) 把工程中的Constants类中的APP_KEY,Redirect_URL, SCOPE域替换成自己创建应用时的所对应的参数。
(4) 创建微博授权类对象:
mWeiboAuth = new WeiboAuth (
this,
Constants.APP_KEY,
Constants.REDIRECT_URL,
Constants.SCOPE);
(5) 实现weiboAuthListener接口,在授权信息成功以后,SDK会将access_token,uid等通过Bundles返回,并且调用onComplete回调函数。
(6) 进行Oauth2.0 Web授权,调用anthorize()方法,授权成功以后就会获得TOKEN。
一般情况下,在获取到Token 后,可以使用Android 中的sharePreferences把token持久化本地文件中,供后面程序使用。
完成了用户授权之后,就解决了用户的身份认证问题,现在应用可以直接调用新浪微博的API。这里以获取当前用户发表的微博为例:
查询API,填上接口所需要的几个参数值,接着发送下面类似的HTTP请求:
https://api.sina.com.cn/2/statuses/user_timeline?count=**&page=**
其中请求参数count指的是单页中返回的结果条数,默认值为20,最大100,超过100按100计算,page是指返回结果指定的页码,通过调用这个接口,我们可以得到当前用户发布的微博的Json数据。程序结构图如图2所示。
但是新浪微博接口有一个返回结果总条数的限制,这个接口最多只能返回2 000条数据。这个接口有2个限制原则:
(1) 基于服务器IP的请求次数限制(1 000次/h)。
(2) 基于同一个用户在使用同一个应用的请求次数限制(1 000次/h)。
针对微博API的这些缺陷,在设计系统的时候需要考虑程序的调用次数。新浪API中有一个rate_limit_status的接口,这个接口返回了接口的剩余调用次数,每小时的限制数,计算器重置剩余时间,下次重置时间4个参数。参考了廉洁等人的设计方案[5],这里在系统中加入了程序控制模块和存储控制模块,程序控制模块主要的任务是监控调用API的次数,通关观察rate_limit_status接口返回的结果,返回的调用次数大于950次的时候,接着调用Java的ADSL程序,进行重新拨号,接着使程序休眠 1 min,这样可以有效地防止API的调用上限。
存储控制模块,主要是提高数据的存储效率的,由于网络等其他客观因素的存在,并不是每次都接收到完全一样的数据,在获得数据和存储数据之间加了一成存储队列层,这样,对于响应收回的数据,可以检查存储队列中是否存在,如果在队列中找到数据,则跳过存储模块直接发送下一次请求,如果发现存储队列中不存在,就把请求回来的数据放入存储队列中,并且把数据持久化到MongoDB数据库中。
Android SDK 中并没有对所有的新浪API进行封装,对于一些特殊的功能,可以自己对新浪API进行封装,扩展Android SDK。这样更加有利于数据的获取。对于国内其他社交网站也会提供相对应的SDK和API ,可以采取类似的方法采集数据。
2 基于网络爬虫页面解析
仅仅使用新浪微博提供的API获取新浪微博的数据并不是惟一的方法,还可以采用自己手写网络爬虫的方式采集微博的数据。使用网络爬虫的方式主要涉及三个过程,第一步模拟新浪微博的登陆问题,能够获取新浪微博的用户首页;第二步分析用户首页,提取想要的信息;第三步内容进行信息持久化[6?10]。
在此使用Node.js实现了这个方案。Node.js本身对绝大数操作采用的是异步处理的方案,所以对于网络爬虫这种要频繁进行I/O操作的应用来说,使用Node.js是非常合适的。另外,Node.js有强大的包管理器工具npm。比如cheerio 和 cookie?jar对于分析网页都是非常不错的库工具。
2.1 新浪网站的模拟登陆过程
大家平时登陆新浪微博,新浪微博的前端客户端的js文件会把使用者的用户名和密码进行加密并进一步进行处理交给后台服务器进行验证。验证通过以后,返回个人登陆页面的首页。因此采用chrome的fiddle插件抓取了一次登陆操作发出的所有请求:
2.1.1 模拟登陆前的预处理
当点击微博用户名输入框的时候,前端js会发出下面的url请求:
http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=&rsakt=mod&client=ssologin.js(v1.4.15)&_=1401243592676
请求的返回值中有几个字段:retcode,如果是0就代表返回成功;Nonce,一串随机数用来加密用的;Publickey,用于rsa2密码加密的公钥,rsakv也是加密用一段字符串;Servicetime,服务的时间戳;Pcid,个人的计算机信息。
当输入完用户名之后,前端页面会第二次发送/prelogin.php请求,中间会带上对用户名进行base64算法加密的参数su。同时更新了Servicetime这个时间戳。如果要带上验证码的话会返回一个参数showpin字段。
其中验证码的产生是根据/cgi/pin.php的请求得到。请求参数中有一个随机数r,以及计算机名pcid。
2.1.2 模拟提交表单操作
查看提交表单操作的URL请求:
http://login.sina.com.cn/sso/login.php?client=ssologin.js
其中关心的主要是sp字段和su字段怎么加密。后来自己阅读了最新的ssologin.js代码,其中有对sp和su的加密过程:
var RSAKey = new sinaSSO.Encoder.RSAKey();
RSAKey.setPublic(me.rsaPubkey, “10001”);
password = RSAKey.encrypt(
[me.servertime, me.nounce].join("\t")
+ ′\n′+ password);
sinaSSOEncoder类在ssologin.js中,它封装了对sina数据的编码的基本操作。最终password的产生就是由调用RSAKey的encrypt方法返回的字符串和‘\n和自己的密码做拼接而成。
2.1.3 登陆成功
如果上一步的retcode返回值为0。表示登陆成功。接下来系统会发请求个人页面的请求:
http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack&sudaref=weibo.com
返回userinfo信息和状态信息以及认证票据。接下来要做的就是访问要抓取的页面请求信息,比如想访问自己的朋友页面,只需要发送这个页面的所对应的url请求,就能够得到这个页面的HTML内容。
2.1.4 保存Cookie
保存当前的Cookie值,用于以后直接登录。
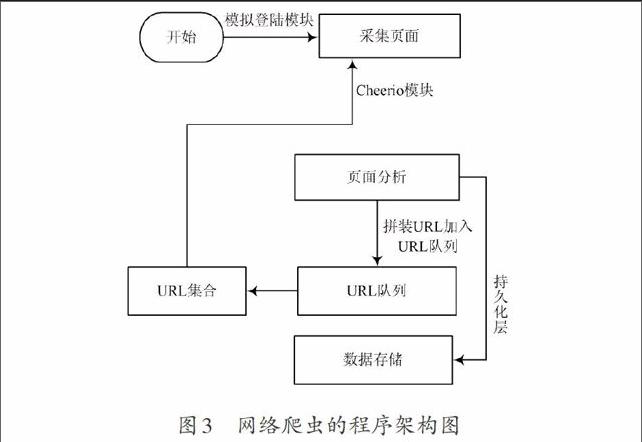
2.2 基于网络爬虫的程序架构设计
整个程序架构如图3所示,主要由下述几个功能模块组成。
(1) URL集合。URL集合是指用户模拟登陆成功以后,用户首先开始提取的URL页面,也可称为种子集合。
(2) 采集页面与页面分析。对于HTML页面,其规则是很复杂的,如果直接用正则表达式去匹配,写出的正则表达式语句将非常复杂,并且使用正则表达式的效率也不是很高。node.js提供了一款cheerio11的插件,可以用node.js管理工具npm直接进行安装。对于页面解析经常会使用JSDOM,但是JSDOM有以下几个问题,首先,JSDOM对内建的解析太过严格,JSDOM附带的HTML解析不能处理当下的大众网站。其次JSDOM太慢,有很大的延迟。最后JSDOM比较累赘,从本质上来说JSDOM是为使用者提供一个在浏览器里看到的DOM环境,便这里并不需要这样的功能。因此可以选择Cheerio,它的语法和Jquery类似,且速度非常快,大约是JSDOM的8倍。Cheerio几乎能够解析任何HTML和XML。Node.js是单线程的,这里没有死锁的存在,也没有线程上下文交换带来的开销问题。同时Node.js是基于事件驱动的,对于I/O密集型的应用非常合适。同时对于CPU密集型的一些任务,Node.js也能够胜任。因此,用Node.js来做网络爬虫非常合适。对于页面的分析处理,首先把HTML页面读进内存,然后利用Cheerio库进行页面解析操作。把有用的结构化信息提取出来,存入数据库。同时也要提取uid字段或者tid字段,进行去重操作,因为这些字段能够重组URL,比如http://weibo.com/u + UID,接着把这个URL加入URL队列中。
(3) URL队列[12?15]。URL队列主要由3个队列组成,分别是等待队列,处理队列和完成队列。处理队列中的URL是要被送到URL集合中的。URL等待队列存放已经提取出来的但是还没有做任何处理URL,等待送入处理队列中。完成队列中存放已经处理完的URL请求和发现错误的URL请求。在把拼装好的URL送入到URL队列之前,要先检查完成队列是否存在该URL,如果有的话就跳过。URL队列的好处是能够控制程序的效率,如果待处理URL为空,程序结束,这样会影响效率。如果待处理URL队列长度太大,服务器压力比较大。所以要实时控制URL队列的长度。
(4) 数据存储。持久化数据的作用,把抓取的结构化数据存入MongoDB数据库中。
3 数据分析
为了验证本文方法的有效性和这两种方法的性能区别,分别搭建了基于API和NodeJs爬虫的开发环境,实验开发机器是Lenovo Y430,CPU 酷睿I2, 内存5 GB,操作系统是Windows 7. Android SDK demo开发环境的是Eclipse IDE for JavaEE。网络爬虫开发环境是 WebStorm 5,程序由node.js实现。 数据统一采用MongoDB进行存储。实验中选取了20个微博账号,每个账号有2 000个好友,并且把这些账号加入应用的测试账号。
实验中,主要是抓取用户所发的微博信息,微博的信息结构是{微博ID(mid), 用户ID(uid), 微博内容(content),转发数(repost_count),评论数(comment_count)}的字符串,比较抓取的微博条数,并把结果持久化本地数据库中。实验中排除网络带宽的影响,本地都选择了网络为100 Mb/s的共享教育网。
(1) 稳定性能比较
稳定性是指单位时间内抓取的微博数量的变化趋势,每小时内抓取的微博数量越接近,越稳定,程序的性能也越好。通过对比连续抓取10 h的微博数据,实验结果如图4所示。
从图4可以发现,基于API的折线图波动比较大,而基于网络爬虫的比较平稳。这是由于API方式是由新浪服务器提供的数据,受网络带宽等因素影响较大,因此稳定性不高,有一定的波动。所以基于网络爬虫的方式在稳定性方面优于基于API的方式。
(2) 抓取速率比较
表1为两种方式抓取速率对比(条数省略到百位)。
数据的抓取速率主要指相同时间段里抓取微博条数多少的比较。在程序中,记录下来两种方式每小时抓取的微博条数,其实验结果如表1所示。通过表中分析,每小时API抓取的条数总是比网络爬虫抓取的条数多。这是由于基于API的方式是直接返回数据,不需要进行网页预处理等复杂操作,而网络爬虫方式需要网页解析,提取数据等操作。因此基于API的方式在抓取速率方面优于网络爬虫的方式。
(3) 数据完整性
经过查阅官网资料[16],新浪API是有一定盈利模式的,对于有些数据地返回需要申请权限并且支付一定的金额,不可能无条件的返还所有想要的数据。网络爬虫方式的基础是对当前网页进行分析处理,能提取出需要的信息。因此网络爬虫的方式在数据完整性方面优于API查询的方式。
(4) API和网络爬虫的融合策略
API和网络爬虫的融合策略主要是指API和网络爬虫这两种方法相结合,是两种方法相互配合采集数据。程序架构如图5所示。
API和网络爬虫获取微博数据各有各的优势,对于某些信息采集,可以结合API和网络爬虫这两种方式,让采集速率最优化。最大化获取微博信息内容,可以首先使用测试账号作为种子ID,调用新浪API接口获得测试用户的朋友ID,把朋友ID拼接成URL,然后使用网络爬虫的方式进行收集,把收集到的个人信息,微博信息存入到数据库中。同时把收集到好友信息经过去重操作之后加入到种子列表中,如此反复迭代,收集微博信息。
表2是连续采集3 h的微博条数,采用融合策略后,采集的微博条数有所增加。这是由于采用融合策略后,API的方式只需要返回用户的UID,相比直接返回微博内容,效率有所提升。同时网络爬虫只需要专注解析用户UID的页面,因此在采集微博的情况下,多策略融合的方法采集的效率更高。
表2 三种方式3 h采集微博条数
4 结 论
通过API和网络爬虫的方式都能获取数据。API的方式获取数据的效率高,但是受第三方服务商限制比较大。网络爬虫的方式效率相对差些,但获得数据比较完整,稳定性更好。对于新浪微博的采集可以采用两种方式相融合的策略。接下来工作是如何优化这两种抓取方式以及垃圾微博信息处理的问题。优化网络爬虫主要从查询驱动的爬取,反向链接数,PR值,前向链接数等因素去考虑。垃圾微博处理主要考虑如何构建模型,识别垃圾微博。微博的使用日益流行,它每天产生的海量的数据。如何采集并且利用这些信息,对用户行为分析、舆情监控、帮助决策有着非常大的帮助。
参考文献
[1] 中国互联网信息中心.第33次中国互联网络发展状况统计报告[EB/OL].[2014?03?05].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201403/t20140305_46240.htm.
[2] 周立柱,林玲.聚焦爬虫技术研究综述[J].计算机应用,2005,25(9):1965?1969.
[3] 黄延炜,刘嘉勇.新浪微博数据获取技术研究[J].信息安全与通信保密,2013(9):71?73.
[4] 吴勇.基于Android手机的新浪微博应用的研究与实现[D].西安:西安电子科技大学,2013.
[5] 廉洁,周欣.新浪微博数据挖掘方案[J].清华大学学报:自然科学版,2011,51(10):1300?1305.
[6] 罗一纾.微博爬虫的相关技术研究[D].哈尔滨:哈尔滨工业大学,2013.
[7] 吴黎兵,柯亚林,何炎祥.分布式网络爬虫的设计与实现[J].计算机应用与软件,2011,28(11):176?179.
[8] 宋海洋,刘晓然,钱海俊.一种新的主题网络爬虫爬行策略[J].计算机应用与软件,2011,28(11):264?267.
[9] 蒋宗礼,田晓燕,赵旭.一种基于语义分析的主题爬虫算法[J]. 计算机工程与科学,2010,32(9):145?147.
[10] 韩宇贞,朱华生.基于Base64编码的数据加密技术[J].南昌水专学报,2002(21):38?40.
[11] Cheerio. Open source connections [M/OL]. [2014?09?30]. http://www.cheeriojs.github.io Cheerio.
[12] 樊星岑.面向微博数据挖掘的网络爬虫系统设计与实现[D]. 哈尔滨:哈尔滨工业大学,2013.
[13] 朱云鹏,冯枫,陈江宁.多策略融合的中文微博数据采集方法[J].计算机工程与设计,2013,3(11):3835?3839.
[14] 卢体广,刘新,刘任任.微博数据通用抓取算法[J].计算机工程,2014,40(5):12?16.
[15] 冯典.面向微博的数据采集和分析系统的设计与实现[D].北京:北京邮电大学,2013.
- 浅析有限责任公司之股权回购问题
- 瑕疵股权出资的法律责任及解决策略
- 股东出资义务加速到期研究
- 铁路商业地产典型合作开发风险管控探析
- 公路施工企业防范经营风险的法律对策
- 从公司法的角度分析企业组织战略管理
- 海南黎族聚居区社区矫正工作现状及基本特点分析
- 浅谈冷兵器袭击的防范处置与警用实训
- 独立学院纪检监察工作探析
- 对涉检信访工作的几点思考
- 新时代如何做好疾控信访工作
- 党史党建工作中“以人为本”理念的渗透
- 新时代承德市提升市民文明素质研究
- 关心下一代工作委员会参与家庭教育初探
- 乡村振兴背景下农村网格化服务的现状与出路研究
- 社会资本视角下的“村改居”社区治理研究
- 关于保险行业调解工作的调研报告
- 居家养老服务市场中的博弈分析
- 基于纪实摄影视角下的公安形象研究
- 校园贷的现状、面临的问题及风险应对策略
- 从劳动经济学角度对新兴热点城市“人才争夺战”的分析
- 我国彩礼制度的功能分析及理性演进
- 浅谈非物质文化遗产
- 全球化进程中民族国家的困境与重构
- 团体心理辅导提升高职学生心理素质的实践探索
- skies
- ski flier
- ski-ing
- skiing
- skiings
- ski jump
- ski jumped
- ski jumper
- ski jumpers
- ski jumping
- ski jumps
- skilful
- skilfully
- skilfulness
- skilfulnesses
- ski-lift
- ski lift
- ski lifts
- skill
- skilled
- skillessness
- skil-lessnesses
- skillet
- skillets
- skillful
- 众口销金
- 众口销铄
- 众口附合
- 众口难调
- 众口难齐
- 众口,祸福之门
- 众叹声
- 众和
- 众啄同音
- 众善
- 众喙一词
- 众喙一辞
- 众喣漂山
- 众喣漂山,聚蚊成雷
- 众喣飘山众嘘漂山
- 众地莫企,众事莫议
- 众垤
- 众士
- 众声
- 众声传说
- 众声呼叫
- 众声嘈杂
- 众声相应
- 众多
- 众多事业都兴办起来