
摘 要: 为了提高云计算Web数据分类的准确性,针对当前C均值分类的模糊性较大的问题,提出一种基于概率分析的云技术Web数据的分类数学模型构建方法,首先结合数理统计理论建立云技术Web数据分类的状态特征方程,构建Web数据准确分类的边值收敛条件,采用概率随机泛函进行云技术Web数据分类的稳定特征优化解求解,然后在有限论域内实现Web数据准确分类的置信区间准确计算,实现数据有效分类。最后进行仿真分析,结果表明,采用该文方法进行云技术Web数据分类的准确性较好、置信度较高。
关键词: 概率分析; 云技术; Web数据; 数据分类
中图分类号: TN911?34; TP211.62 文献标识码: A 文章编号: 1004?373X(2017)16?0041?03
Abstract: In order to improve the accuracy of cloud computing Web data classification, in allusion to the fuzzification of C means classification, a method of constructing the probability analysis based classification mathematical model of cloud technology Web data is put forward. The state feature equation of cloud technology Web data classification is established according to the mathematical statistics theory. The boundary value convergence condition of accurate classification of Web data is built. probability random functional is used to solve stable feature optimization solution of cloud technology Web data classification, and then realize the Web data classification calculation at confidence interval in finite domain and implement the effective data classification. The simulation analysis results show that the method has high accuracy and high confidence coefficient for cloud technology Web data classification.
Keywords: probability analysis; cloud technology; Web data; data classification
0 引 言
在云計算的大数据信息时代下,大量数据通过云技术实现网格化并行计算,提高了数据的处理速度,采用云计算进行Web数据处理,首先需要进行海量数据的分类处理,数据分类是实现海量数据的分区域分属性计算的基础,数据分类是提高云计算处理速度的关键,研究数据的优化分类技术,同样在模式识别和信息检索中具有广阔的应用前景。传统的数据分类方法主要有模糊C均值聚类方法[1]、支持向量机分类算法[2]、Bagging的概率神经网络集成分类方法等[3],上述方法在进行数据分类中容易出现局部收敛和对初始值敏感性较强的问题,对此本文提出一种基于概率分析的云技术Web数据的分类数学模型构建方法,构建数据分类的数学模型并应用在Web数据分类中,取得了较好的效果。
1 数据分类状态特征方程构建
为了实现云技术Web数据分类的数学模型构建,需要首先构建数据分类状态特征方程,给定云技术Web数据信息流的一向量组[x1,x2,…,xn∈Cm](m维复数空间),采用随机概率密度泛函进行数据分类的高阶矩分布计算,取数据分类的阶数[q=4],在凸优化聚类约束条件下,数据分类的周期解系数[bk]取作[b2=b-2=1,] [b1=b-1=2,b0=0]。采用类决策树分类的特征层融合方法[4],构建数据分类的Bernoulli空间,在无穷维向量空间得到Web数据分类的平衡状态分布向量组为:
4 实验测试分析
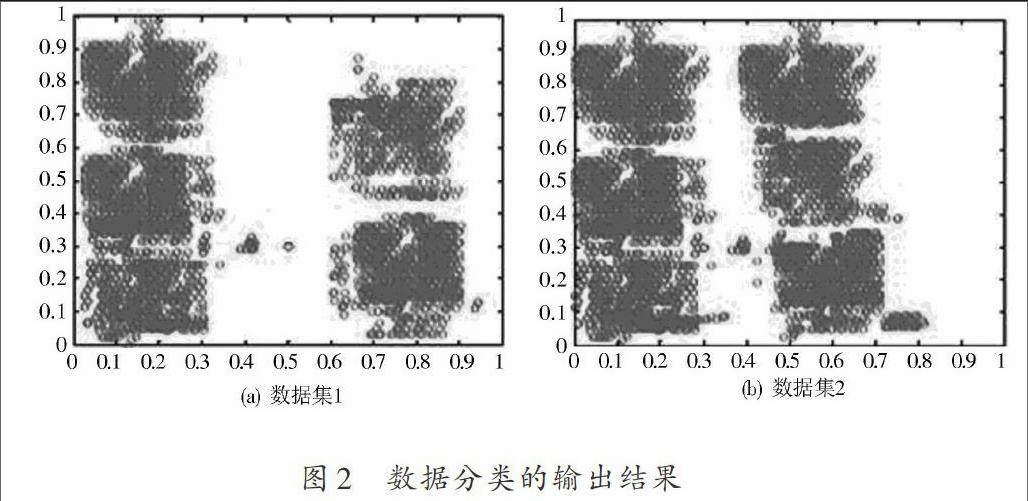
对云技术Web数据的分类仿真实验建立在Deep Web大型云计算数据库基础上,以Matlab 2012为仿真工具,采用爬虫算法爬取网络中的云计算Web数据进行样本采集,采集的采样率为[fS=10 kHz],迭代次数为500次,样本集和测试集的查询个数分别为200个和500个查询,云技术Web数据分别设定5和6个属性类别,得到数据分类的输出结果如图2所示。
图2 数据分类的输出结果
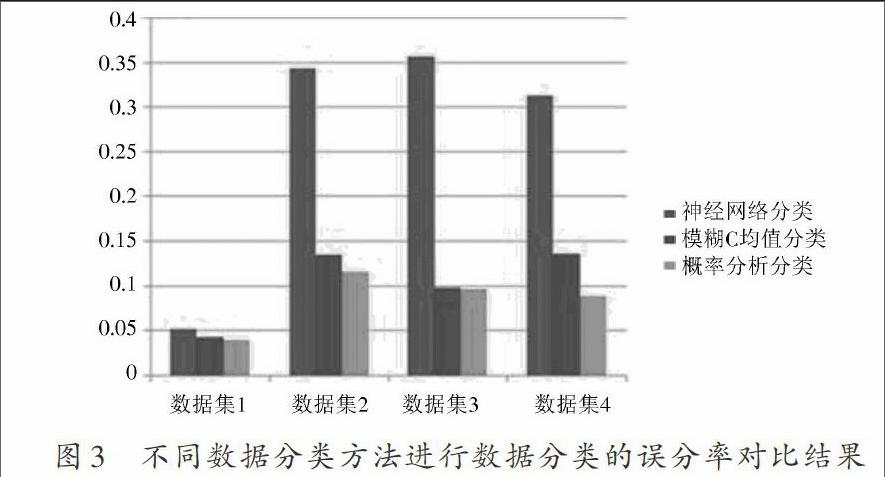
从图2得知,采用本文方法进行云技术Web数据分类的准确性较好,能有效实现对各个属性类别的数据分类,误分概率较低,图3给出了不同方法进行数据分类的误分率对比结果。
图3中给出了4个数据集采用三种方法进行数据分类的误分概率统计,分析得知,采用本文方法进行数据分类的误分率最低、置信度较高、性能最好。
5 结 语
本文提出一种基于概率分析的云技术Web数据的分类数学模型构建方法,结合数理统计理论建立云技术Web数据分类的状态特征方程,构建Web数据准确分类的边值收敛条件,采用概率随机泛函进行云技术Web数据分类的稳定特征优化解求解,然后在有限论域内实现Web数据准确分类的置信区间准确计算,实现数据有效分类。仿真结果表明,采用本文方法进行云技术Web数据分类的准确性较好、置信度较高,性能优于传统方法。
参考文献
[1] 孙力娟,陈小东,韩崇,等.一种新的数据流模糊聚类方法[J].电子与信息学报,2015,37(7):1620?1625.
[2] 朱珍.基于神经网络集成分类器预处理的支持向量机分类算法[J].科技通报,2013,29(4):26?30.
[3] 蒋芸,陈娜,明利特,等.基于Bagging的概率神经网络集成分类算法[J].计算机科学,2013,40(5):242?246.
[4] 尚朝轩,王品,韩壮志,等.基于类决策树分类的特征层融合识别算法[J].控制与决策,2016,31(6):1009?1014.
[5] 张红蕊,张永,于静雯.云计算环境下基于朴素贝叶斯的数据分类[J].计算机应用与软件,2015,32(3):27?30.
[6] 刘俊,刘瑜,何友,等.杂波环境下基于全邻模糊聚类的联合概率数据互联算法[J].电子与信息学报,2016,38(6):1438?1445.
- 高血压护理注意事项
- 一体化教学法在基础护理教学中的应用研究
- 颅脑损伤患者开颅手术的围手术期优质护理服务分析
- 重症监护护理评分系统在ICU护理资源配置中的应用效果研究
- 下肢深静脉血栓行介入及综合性治疗的疗效和护理要点分析
- 精神科病患医院感染的危险因素及综合性规范化护理的管理效果研究
- 九例青少年特发性脊柱侧弯围手术期心理护理
- 血液透析动静脉内瘘中应用保护性护理的应用效果
- 快速康复外科护理在高血压脑出血微创手术患者中的应用
- 个体化延续护理对改善高血压患者生存质量的效果观察
- 综合护理在特发性血小板减少性紫癜中的应用价值分析
- 精神科护士规范化培训的实施与效果评价
- 集束化护理预防肿瘤患者介入术后器械性压疮的研究
- 循证护理模式改善消毒供应中心中器械消毒质量的效果观察
- 静疗专科护理干预对应用PICC依从性及并发症的护理
- 应用胸腔镜治疗自发性气胸术后对并发症的有效护理路径
- 个性化护理对重症颅脑损伤患者亚低温治疗效果的影响
- 全面系统护理干预在重型对冲性颅脑损伤患者双侧去骨瓣减压开颅术围手术期中的应用
- 基于循证的快速康复外科概念在急性阑尾炎围术期护理中的应用研究
- 结肠癌术后肠道护理干预促进功能恢复的效果观察
- 小儿扁桃体腺样体摘除术后逐步开放饮食的护理干预措施探讨
- 龙血竭外敷联合氧疗及红外线在Ⅲ期压疮护理中的应用
- 前列腺增生术后患者留置导尿漏尿并发症的干预性护理分析
- 神经内科护理中脑卒中康复护理的临床方法研究
- 谈实现母乳喂养策略中的社区妇幼保健护理
- premisrepresented
- premisrepresenting
- premisrepresents
- premiss
- premisses
- premium
- premiumed
- premiumincome
- premium income
- premium pay
- premiumpay
- premiums
- premodel
- premodeled
- premodeling
- premodelled
- pre-modelling
- premodelling
- premodels
- premodifications
- premodified
- premodifies
- premodifying
- premoistened
- premonetary
- 穷身
- 穷身泼命
- 穷辁
- 穷辙
- 穷辰
- 穷辱
- 穷边
- 穷达
- 穷运
- 穷迕
- 穷远
- 穷迫
- 穷迫,迫促
- 穷迹
- 穷追
- 穷追不舍
- 穷追猛打
- 穷追苦克
- 穷追苦剋
- 穷退
- 穷适楚
- 穷途
- 穷途之哭
- 穷途俗眼
- 穷途哭