李维

摘要:在智慧旅游的大目标以及旅游网站功能落后的背景下,解决信息过载问题的推荐系统引起学者的关注。文章以浙江省750个景点为例,基于案例推理法,通过多线程爬取、预处理旅游网站的数据来构建旅游案例库。系统基于Flask框架敏捷开发,设计了基于Word2Vec词嵌入向量技术计算文本相似度的案例匹配算法,调用MongoDB数据库索引以及Find引擎,实现了耦合层次的搜索,根据用户的旅游偏好给用户提供个性化旅游景点、游记等服务。
关键词:案例推理;旅游推荐系统;文本相似度
一、引言
随着旅游信息化的发展和智慧城市的建设,智慧旅游成为我国各旅游目的地信息化建设的重点。而国内的旅游网站基本停留在旅游产品的简单搜索上,服务项目比较单一,且旅游产品种类繁多,无法满足人们对个性化旅游信息服务的需求。在智慧旅游的大目标以及旅游网站的功能落后的背景下,可以解决信息过载问题的推荐系统被广大学者重视。传统的推荐系统虽然已经取得了不小的发展,但仍存在数据稀疏性、冷启动、行业特殊性等问题。本文将案例推理法应用到旅游推荐系统的研究中,通过与用户交互,根据用户的旅游偏好快速推荐出旅游目的地信息和游记信息,一定程度上改进了现有旅游推荐系统存在的数据稀疏性和冷启动等问题。
二、旅游智能推荐系统的原理及技术
(一)工作原理
本旅游智能推荐系统的设计目标有以下几点。
1. 根据用户的旅游偏好,提供个性化旅游目的地信息和游记信息列表推荐服务。
2. 实现用户管理及后台管理员职能。
3. 系统功能模块化,交互界面友好,快速响应,可拓展性强。
根据案例推理的基本流程,先确定案例的表示方法,接着多线程爬取在线旅游网站的景点和游记数据并预处理,构建旅游案例库。然后基于Flask框架敏捷开发,在系统后端,设计了基于Word2Vec词嵌入向量技术计算文本相似度的案例匹配算法,调用下层MongoDB数据库索引以及Find引擎,实现了耦合层次的搜索。具体的工作原理有以下几点。
1. 对旅游目的地文献进行研究,构造旅游偏好模型和旅游目的地模型,进一步确定旅游案例的表示方法。
2. 设计并实现基于Python语言的数据收集模块,多线程爬取在线旅游网站的相关景点和游记信息。
3. 根据系统的设计目标,设计并实现基于Python语言的数据预处理模块,包括对数据进行分类、清洗等进一步处理,并构建索引表即旅游案例库。
4. 基于Python Flask框架开发系统,采用前后端分离的MVC框架。在系统后端,构建基于Word2Vec词嵌入向量技术计算文本相似度的案例匹配算法,调用下层MongoDB数据库索引以及Find引擎,实现了耦合层次的搜索,提供根据相似度排列的推荐结果。
5. 实现用户管理及后台案例库管理的管理员职能,根据用户的浏览行为,修正旅游数据库中的解决方案,完成案例库的更新。
(二)案例推理
案例推理法(Case-based reasoning,简称CBR)借鉴人类处理问题的方式,运用过往的经验和知识解决问题,成为了人工智能领域的一个研究热点。案例推理法来源于认知科学:人类能把感知的信息传达至大脑,大脑会将这些信息存储起来。而今后遇到类似的问题时,这种被存储的信息就为问题的求解带来可借鉴的参考经验。CBR系统一般包括4个循环过程:检索(Retrieve)、重用(Reuse)、修正(Revise)、保留(Retain)。CBR系统首先会对比问题案例和先前案例的相似性,去先前案例库里检索出相似的案例来解决问题案例,并修正先前的解法,而新的解决问题的方法和问题案例都会被系统记录并存储,先前案例库就得到了更新。这种增量式学习方法使得CBR系统的学习能力不断提高。
(三)自然语言处理之计算文本相似度
互联网迅猛发展,每时每刻都在产生大量的文本、图片、音频等数据,自然语言处理(Natural Language Processing, NLP)技术可对数据进行处理并挖掘其中的价值,广泛应用于语音合成、文本分类、词性标注等领域。文章中主要应用了Word2Vec词嵌入向量技术来计算文本相似度。Google在2013年提出Word2Vec词向量训练算法,将词转换为实数向量。Word2Vec采用的词向量是Hinton于1986年提出的Distributed Representation,其基本思想是通过训练,将某种语言中的每一个词映射成一个固定长度的向量。Word2Vec工具采用了CBOW(Continuous Bag-Of-Words)模型和Skip-gram模型。CBOW模型是根据上下文的词计算中心词的概率分布,在模型的训练中,耗时较短,句法分析的准确率较高,但训练结果受限于上下文,难以正确反映在此范围外的语义关系。而Skip-gram模型是通过中心词来计算上下文的词的概率,在模型的训练中由于计算量较大,耗时较长,但语义分析的准确性较高。将文本表示成词向量,文本的相似度就可以转化为词与词的相似度。词与词的语义相似度可以通过向量余弦表示,相似度越高,余弦值越大。
三、旅游案例库的构建
(一)案例表示
在案例推理中,案例的有效表示是案例推理运行的基础。常见的案例表示方法为<问题描述,解决方案>的二元组形式,其中问题描述是问题发生的背景和原因,通过对比待解决案例和已有案例的问题描述,实现案例的推理;解决方案是提供相似的已有案例的解决过程。本文首先构建了旅游偏好模型。旅游偏好模型体现了游客对下一次旅游的兴趣偏好,了解用户的偏好是后续进行推荐的基础。本文在已有旅游目的地文獻研究基础上,构建了旅游偏好模型如下:<目的地类型,出发月份,出行天数,出行人物,人均费用,交通方式,住宿设施,餐饮方式>,其中目的地类型分为10类:自然景观、历史文化、红色旅游、主题游乐、度假休闲、乡村旅游、工业旅游、博物馆、科技教育、其他;出发月份分为1~2、3~4等;出行天数分为3天以下、4~7天、8~14天、15天以上;出行人物分为一个人,和朋友,情侣/夫妻,带孩子,其他;人均费用分为1~999元、1000~5999元、6000~19999元、20000元及以上。
接着构建了旅游目的地模型。旅游目的地指的是能够满足游客游憩目的的地点。本文根据研究需要,构建了旅游目的地模型如下:<景点名称、景点简介、景点开放时间、景点门票价格、交通线路、景点游记>,其中景点游记是过往游客记录该旅游目的地的游览经历。
在已经构建的旅游偏好模型和旅游目的地模型的基础上,本文将旅游案例表示为<{目的地类型,出发月份,出行天数,出行人物,人均费用,交通方式,住宿设施,餐饮方式}, {景点名称、景点简介、景点开放时间、景点门票价格、交通线路、景点游记}>,其中旅游偏好模型是案例的问题描述,即待推荐用户的偏好,旅游目的地模型是案例的解决方案,即根据待推荐用户的偏好从案例库中匹配出相似偏好的案例进行推荐。
(二)案例收集
国内热门的旅游领域的垂直搜索引擎主要有马蜂窝、携程、去哪儿等,存有海量旅游目的地信息和游记信息。本文以知名旅游胜地浙江省为研究对象,目的是构建基于CBR的浙江旅游智能推荐系统。由于马蜂窝运营时间较早,旅游目的地攻略专业,群众基础较大,游记信息量丰富,因此设计基于Python语言的网络数据收集模块,爬取马蜂窝网站上浙江省景点及游记的文本信息。
由于在线旅游网站反爬虫,设置了IP访问量限制,如果单个IP在短时间内大量访问网站将会被封禁。在网络数据挖掘时,本文将多线程(multithread)代理、随机浏览器、代理IP地址三种反反爬虫技术进行结合。首先多线程,代理IP地址,随机User-Agent,随机休眠,得到景点下所有游记链接,再多线程爬取每一篇游记的文本信息,最终得到浙江省景点共750个,游记共6410篇,返回3个文档:“马蜂窝浙江景点.csv“文档中收集了景点名称、景点介绍url、景点简介、景点下游记list的url;“merged_links.csv”文档中收集了景点下游记list的url、具体游记url、游记标题;”res“文件夹中以json格式返回了景点信息”interest.json”和游记信息”youji.json”,其中景点信息包括景点介绍url、交通线路、景点门票价格、景点简介信息、景点营业时间,游记信息包括出行人物、出发时间、人均费用、游记作者、出行天数、具体游记url。
(三)案例分类和清洗
先进行案例分类。文章参照浙江省文化和旅游厅官网的景区及对应景区类型信息,将“马蜂窝浙江景点.csv“文档中的750个景点根据上节10类旅游目的地类型进行归类。对于浙江文旅官网有的景点名称,直接引用景区类型,剩下没有的,将结合景点介绍人为进行分类,例如 “杭州萧山国际机场”、“杭州东站”等归为“其他”一类。最终整理得到“浙江景点及类型匹配表.xlsx”,并与“马蜂窝浙江景点.csv“文档进行合并,新增景点类型信息。
接着进行案例清洗。本小节做的是数据的初步清洗,主要是删除爬取的文本信息中的网络符号、无效字符以及重复的数据等。由于基于Python的爬虫爬取的是HTML格式的网页数据,保存时会带有例如
,
等HTML符号,这些符号属于噪声数据,在写入文档前需要被过滤掉。本文在爬虫程序new_scrawler.py中引入BeautifulSoup库解析网页,将HTML数据解析成对象来处理,将全部页面转变为字典或数组,从而实现将网络符号全部过滤。
(四)案例库的构建
1. 建立索引表
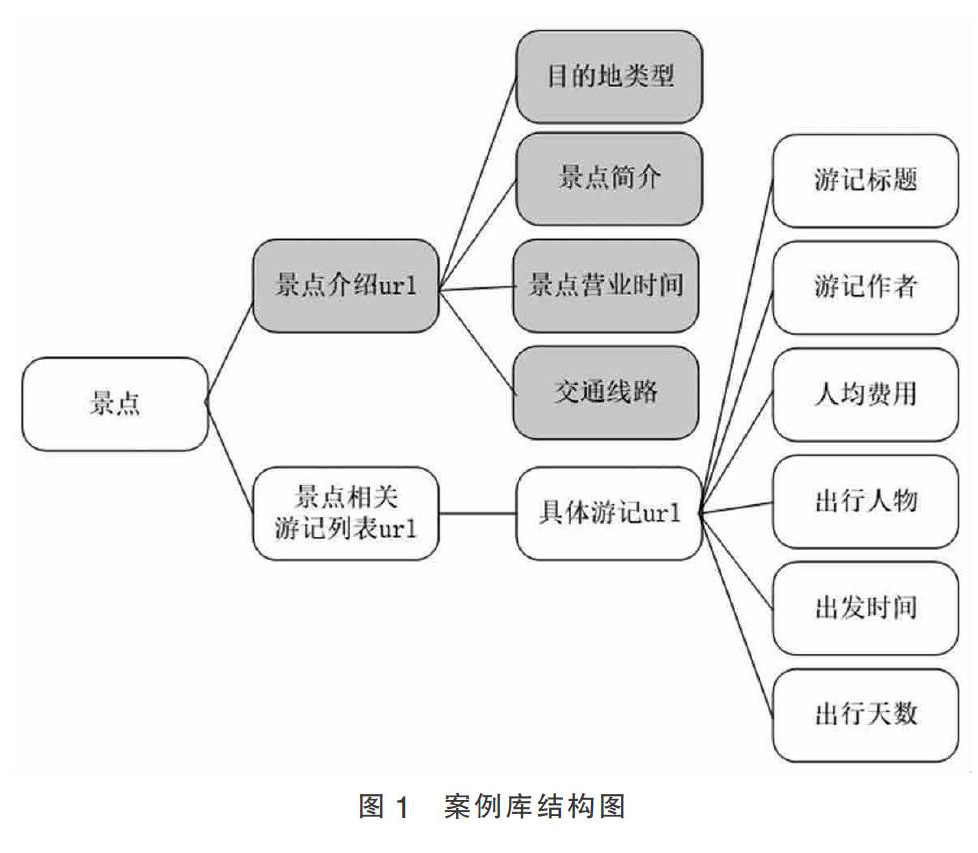
一个景点链接对应多个游记链接,即存在映射关系。将原始数据进行匹配整合,新增一个空字典mapping{},根据映射关系向字典中增加景点和游记信息的键值对。在“马蜂窝浙江景点.csv”文档和“merged_links”文档中,以景点下游记list的url作为主键进行匹配;在”res“文件夹和“merged_links”文档中,以具体游记url为主键进行匹配,最终将3张表中的信息进行合并导入CSV文档,得到索引表_V5,如结构图1所示。
鉴于后续开发的旅游智能推荐系统具备根据用户输入的旅游偏好:目的地类型、出发月份、出行天数、出行人物、人均费用等检索出符合条件的景点和游记信息,需要对索引表进行以下处理。对于表中数值类型数据如出发时间、出行天数等要抽取出数值列,对于文本类型数据如目的地类型等无需处理,后续可直接调用find()函数查找。对于索引表中以字典形式{简介、交通线路、景点营业时间、景点门票价格}存储的景点信息,需拆开独立成列,以字符串格式呈现。
为实现以上处理,设计了基于Python语言的数据预处理模块。定义了split_csv()函数:把索引表的interest_info中的类目拆开单独写入表格;将所有游记中出发时间、出行天数、人均费用缺失为空的列记为-1000;把\n替换成‘
、亂码 替换成空格;把数据进一步清洗,提取出int类型的出发月份,int类型的人均费用,int类型的youji_day,最终得到索引表V_7。
2. 构建案例库
将索引表_V7写入进MongoDB。MongoDB是一个基于分布式文件存储的数据库。在MongoDB中新建Travel数据库来存储游记信息,将原本存在硬盘的索引表_V7读进内存。
四、旅游智能推荐系统的实现
(一)开发环境
实验采用的操作系统为Win10,开发语言为Python 3.5,开发环境IDE为Pycharm,网站主要是基于 Flask框架开发,采用前后端分离的MVC框架。使用的数据库为MongoDB。
(二)案例匹配
为实现旅游智能推荐系统,本文定义了两个搜索引擎。第一个搜索引擎是根据用户筛选旅游偏好:目的地类型、出发月份、出行天数、出行人物、人均费用,调用下层MongoDB数据库索引以及Find引擎,由于大量游记存在出发月份、出行天数、人均费用中一个或多个缺失的情况,返回的检索结果将包括所有符合筛选的偏好以及缺失该偏好的游记。第二个搜索引擎是基于Word2Vec词嵌入向量技术的搜索引擎,根据用户输入的自定义旅游需求,计算其与第一个搜索引擎的搜索结果的文本相似度,将搜索结果按相似度由高到低推荐给用户。该搜索引擎的基本原理是用Jieba模型将句子切割成词组,用Word2Vec工具将词组变成64维的向量,返回用户输入的旅游需求和第一次搜索结果的相似度打分并排序,按照顺序返回前端页面显示,实现耦合层次的搜索。
文章中计算文本相似度采用的是余弦相似性算法,词组x和词组y分别对应m维词向量和词向量,二者的相似度为两向量的余弦值,如公式(1),其中,表示向量的点积,||||表示向量的模。
sim(x,y)=con(,)=(1)
具体代码函数实现如图2所示。
(三)案例庫更新
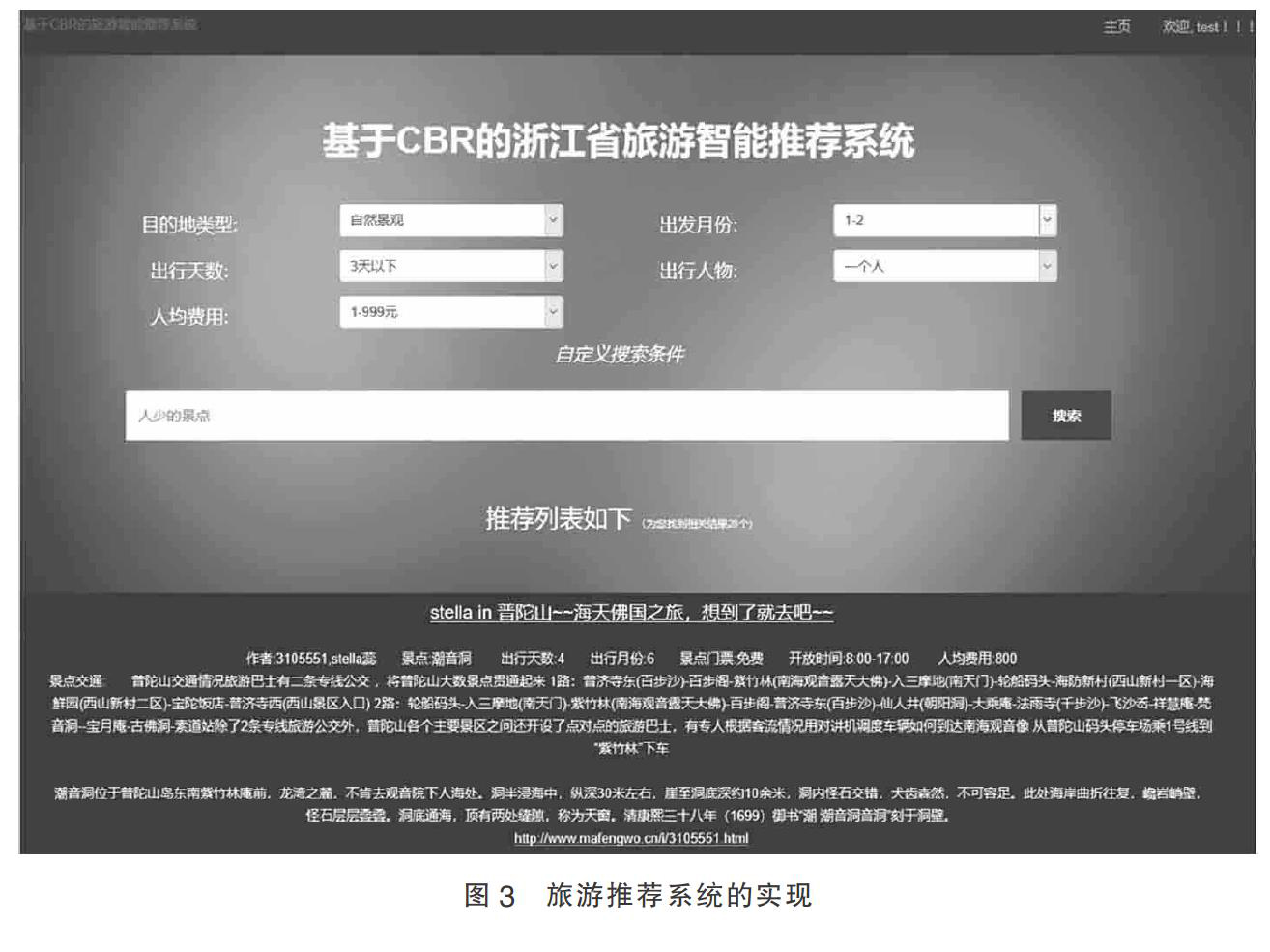
用户在输入旅游偏好后,系统会推荐出符合偏好的旅游目的地和游记列表,如图3所示。用户对推荐结果的浏览点击情况一定程度上可以反映对推荐结果的采纳程度,对后续旅游案例库的更新有一定的依据价值。在MongoDB数据库新增一个User数据库存储用户信息,将用户注册信息、用户搜索记录、用户浏览历史等信息写入。在网页后端注册管理员帐号,实现管理员管理用户和管理后台案例库的职能,可以根据用户的浏览行为修正Travel数据库中的解决方案,也可以往Travel数据库中新增案例,从而实现案例库的更新,完成CBR的增量式学习。
五、结论
通过对用户的旅游偏好和旅游目的地建模,基于案例的推理方法,结合网络爬虫技术构建浙江省景点和游记案例库,结合深度学习构建案例匹配算法,基于Flask框架设计并实现了基于案例推理的浙江旅游智能推荐系统。该系统根据用户的偏好输入,匹配旅游案例库中的解决方案,提供旅游目的地信息和游记信息列表,给用户提供个性化定制旅游景点、游记等服务。该系统具有良好的稳定性和较强的可拓展性,对其他旅游目的地的研究也有一定的借鉴意义。
参考文献:
[1]Watson I. Case-based reasoning is a methodology not a technology[J].Knowledge-Based Systems,1999,12(5-6).
[2]Rumelhart D E, Hinton G E, Williams R J.Learning representations by back-propagating errors[J].Nature,1986,323(6088).
[3]Zahran M A, Magooda A, Mahgoub A Y, et al. Word Representations in Vector Space and their Applications for Arabic[M].Computational Linguistics and Intelligent Text Processing,Springer International Publishing,2015.
[4]侯玉梅,许成媛.基于案例推理法研究综述[J].燕山大学学报(哲学社会科学版),2011(04).
[5]Shardanand U. Social Information Filtering:Algorithms for automating“word of mouth”[C].Proc. Conference on Human Factors in Computing Systems,Denver,CO.ACM Press,1995.
(作者单位:同济大学经济与管理学院)
- 引导问题生成 构建动态课堂
- 推进基础教育课程改革 全面实施素质教育
- 吉林省推进义务教育 均衡发展的实践与思考
- 村小与教学点教师队伍建设的现实困境及政策建议
- 彰显学生生命成长 在成事中成人
- 基于农村学生生活化的有效德育实践
- 解读心灵密码 培养良好心理
- 摭谈儿童言语学习的基础和优势
- 运用心理教育做好班级管理
- 践行减负增效 让学生快乐成长
- 三个“还给”助推减负增效
- 教研部门如何在区域减负中寻找支点
- 快乐、高效的儿童情境学习
- 推进课堂教学改革 全面实施减负增效
- 创新德育管理 成就生命精彩
- 从科技教育到科技特色学校
- 农村小学特色建设的思考与实践
- 小学践行社会主义核心价值观的十个结合
- 委托管理办学模式下促进教师专业发展的途径思考
- 县域教师进修学校职能创新促进教师专业发展的探索
- 英大学新生忘记六成高中所学知识
- 日本大学考试招生体制及启示
- 评价高效课堂的“五要素”
- 高中英语课堂教学中学习理论运用的策略探究
- 教育部下发《关于做好中小学生升级毕业升学学籍信息管理工作的通知》
- have time/have the time
- have to
- have to contend with
- have to do with sth / be to do with sth
- have total/complete control
- have trouble/difficulty
- have turned 20/30 etc
- have ulterior motives
- have very little time/not have much time
- have (very) little time/not have much time
- have you got a light?
- have your finger on the pulse
- have your fingers in the till
- have your hands full
- have your head screwed on
- have your say
- have your suspicions
- have your work cut out for you
- have youth/experience etc on your side
- have²
- have³
- have¹
- having
- having responsibility
- having to
- 按类别或系统编辑供参考的书
- 按类区分
- 按类聚集
- 按类集聚
- 按纳
- 按线索去寻找需要的东西
- 按组织部位分开
- 按绳切墨
- 按罪
- 按罪恶或错误的性质,理应得到这样的惩罚
- 按置
- 按翻
- 按老办法做
- 按老方子吃药——还是老一套
- 按老样子做
- 按老规矩、旧传统办事
- 按老规矩办事
- 按老黄历办事
- 按耐
- 按能承包
- 按脉
- 按自己的意图独断独行
- 按自己的方便行事
- 按舞
- 按营不动