Chukwa在日志数据监控方面的运用
常广炎
摘要:Chukwa是Hadoop软件家族成员的一员,是_个分布式系统,应用于大规模集群的数据收集上,构建在Hadoop的HDFS和MapReduce框架之上。文章通过对数据日志的采集、存储、分析和展示,为用户提供全面、灵活、可视化的服务,弥补了MapReduce对大量日志文件处理能力不足的弱点。
关键词:分布式系统;Hadoop;Chukwa;MapReduce
1.Chukwa的简介
Hadoop的MapReduce最初用于日志处理,随着集群日志不断地增加,生成大量的小文件,而MapReduce具有处理少量大文件的优势。Chukwa弥补了这一缺陷,同时具有高可靠性。
Chukwa由Yahoo开发,是基于Hadoop的大集群分布式监控系统,是Hadoop软件家族成员之一,依赖于Hadoop的其他子项目,以HDFS为存储层,MapReduce为计算模型,Pig作为其高层处理语言,是采用流水式處理方式和模块化结构的收集系统。Chukwa的系统开销非常小,不到整个集群资源的5%。
2.Chukwa的架构
Chukwa有3个主要组成部分:客户端,运行在每个监控机上,传送源数据到收集器;收集器和分离解析器,收集器接收客户端数据,将其写到HDFS中,分离解析器进行数据分析,转换成有用记录;HICC是一个Web页面,用于Chukwa内容的展示。
2.1客户端(Agent)
集群上的每一个结点,Chukwa使用一个Agent来采集它感兴趣的数据,每一类数据通过一个Adaptor来实现,数据类型在相应配置中指定。启动Adaptor可以通过UNIx命令完成,Adaptor能够扫描目录,追踪创建文件,接收UDP消息,不断追踪日志,将日志更新到文件中。Agent的主要工作是负责Adaptor的开始和停止,并通过网络传输数据。为了防止数据采集端Agent出现故障,Chukwa的Agent采用了watchdog机制,会自动重启和终止数据采集进程,防止原始数据的丢失。
2.2收集器(Collector)和分离解析器(Demux)
Agent收集到的数据是存储到Had00p集群上的HDFS上,Hadoop集群处理少量大文件具有明显优势,而对大量小文件是其弱点,针对这一点Chukwa设计了Collector这个角色,用于把数据先进行合并成大文件,再写入集群。Demux负责抽取数据记录并解析,使之成为可以利用的记录,以减少文件数目和降低分析难度。一般采用把非结构化的数据进行结构化处理,抽取其中的数据属性,Demux是MapReduce的一个作业,可以根据需求定制Demux作业,进行各种复杂的逻辑分析。
2.3HICC
HICC是Demux数据展示端的名字,其功能是可视化系统性能指标。HICC能够显示传统的度量数据,以及应用层的统计数据,其可视化功能可以清楚看到群集中的作业是否在被均匀传播,同时支持集群性能的调试和Hadoop作业执行的可视化。
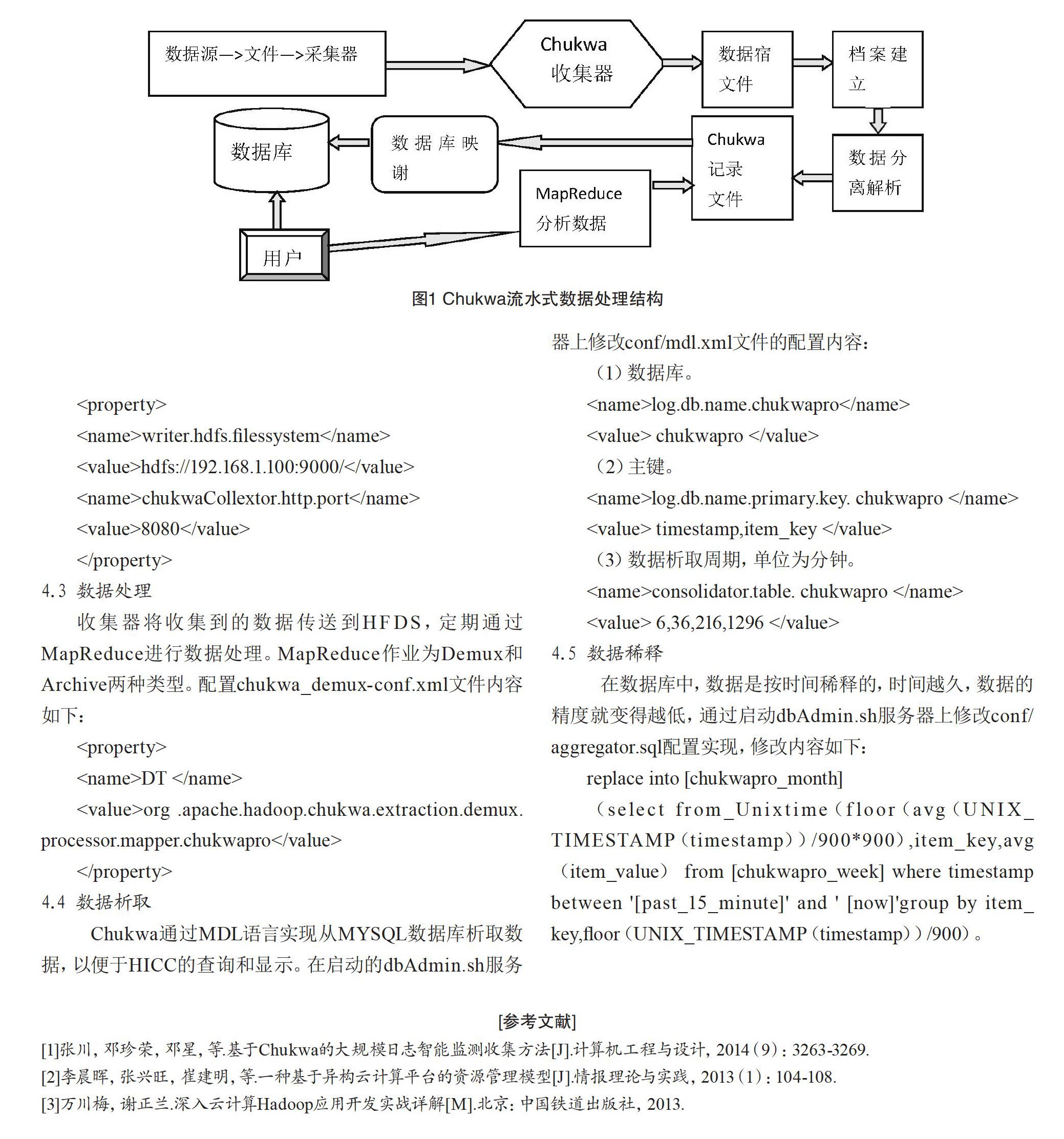
3.Chukwa流水式数据处理结构
流水式模式就是利用分布在各个结点客户端的采集器收集监控信息,然后以块的形式通过HTTP POST汇集到收集器,处理后转存到HDFS中。后由分离器利用MapReduce将这些数据转化为结构化记录,存入数据库,HICC调用数据库数据,展示给用户。其数据处理流程如图1所示。
4.Chukwa在数据收集处理方面的运用
4.1数据生成
Chukwa提供了日志文件、Socket、命令行等数据生成结口,方便脚本的执行,直接读取脚本执行结果的操作如下:
Chukwa首先加载Initial Adaptors的配置文件,它指定了不同适配器对应的收集日志的内容。以execAdaptoe脚本为例,配置文件内容如下:
add org.apache.hadoop.chukwa.datacollection.adaptor.ExecAdaptor DT 3600
$CHUUKWA-HOME/bin/hdfs-new.sh 0
其中:3 600脚本执行间隔,单位为秒。
4.2数据收集
收集器部署时,将所有适配器机器端口存放在代理的conf/collectors中,配置收集器的chukwa-collector-conf.xml文件内容如下:
