蒋子雷


摘?要:本文使用支撑向量机(SVM)算法构建针对中国上市公司债券违约事件的预警模型。在已有数据基础上,通过构建公司-负债季度层次样本的方式使样本量合理规模扩大,将样本分为违约个体和未违约个体两类;结合相关文献选择宏观经济、企业盈利能力、企业偿债能力、企业运营能力和企业现金状况五个方面32个指标作为区分两类样本的备选特征;借助Python-sklearn模块训练模型,利用其网格搜索工具尝试多种模型超参数组合,以选取表现得分最高的分类预测模型,最终得到F1-score均值0.963的预测效果。
关键词:支撑向量机;上市公司;信用风险;债券违约
中图分类号:F23?文献标识码:Adoi:10.19311/j.cnki.1672-3198.2020.27.053
1?我国近年上市公司债券违约现象概述
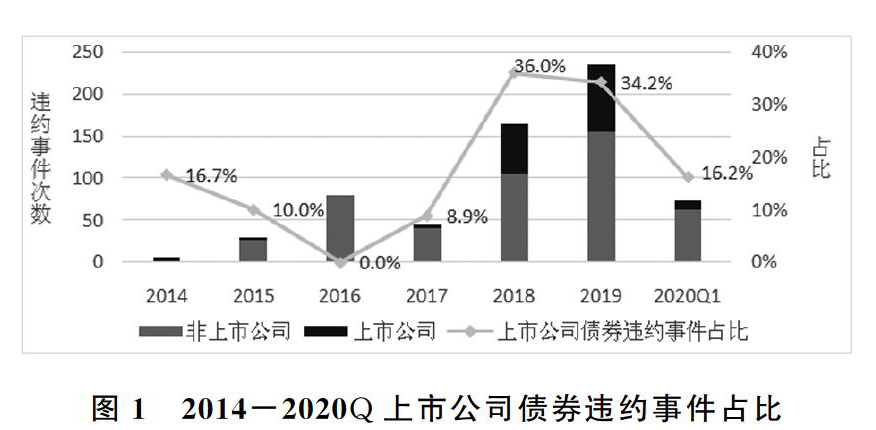
随着我国深化金融领域改革,推进金融产品市场化定价,取消政府兜底、刚性兑付模式,零违约已成为了我国债市的历史,2014年初的“11超日债”发生第一例债券实质违约,随后近几年我国债市接连出现发债主体债券违约的现象。2018年至今,因为经济下行压力加大、股市震荡、融资难度加大等原因,债券违约主体中上市公司的比例明显高于以前年份(见图1)。我国上市公司债券违约有以下特征:涉及以制造业为主的多个行业;包括AAA级在内的各评级公司债都有违约现象;违约主体中民营上市公司占比大等。因此,一般被市场认为经营水平较高,资信情况较好的上市公司群体接连出现债券违约事件是一个应该引起市场关注的现象。
预警模型的构建思路
现有相关研究大多发现上市公司发生违约事件会在之前一段时间的财务经营指标上有所反映,因此这些指标可以为预警其债券违约提供帮助。支撑向量机(Support Vector Machine)算法常用于解决小样本,非线性,高维度分类问题,因而适合度量债券违约风险。但就本文关心的上市公司信用风险问题而言,目前国内文献中还没有运用SVM算法来预测上市公司债券违约事件的标准化模型。本文将使用SVM算法,利用上市公司财务经营指标和宏观经济数据,对其是否会在下一季度发生的债券违约事件进行预测,希望通过展示SVM算法在此预测任务中的表现,补充现有的关于度量上市公司信用风险的研究。
我国债市2014年才发生第一例实质债券违约,至今上市公司债券违约事件累计161个,涉及上市公司主体45家,为了扩大样本量,本文根据上市公司发债数据,将样本个体的单位设定为上市公司负债季度,样本分为两类:一类为违约样本,即当季发生违约事件的上市公司负债季度;另一类样本为非违约样本,即当季且未来2年(8个季度)内未发生违约事件的上市公司负债季度。经过清理筛选得到281个有效样本个体,违约和未违约样本个数分别为79和202。将宏观经济、公司盈利能力、偿债能力、运营能力、现金流状况五个方面的指标加入SVM分类器模型进行训练,最终模型保留了其中19个特征,预测效果评价指标F1-score达到了均值0.963的水平。
3?文献综述
3.1?有关公司债、企业债信用风险特征的研究
一类文献是对具体上市公司违约案例的单独分析,如刘晓凤(2019)、任晴晴(2020)对某些特定上市公司违约事件(如富贵鸟、康得新、神雾环保)进行定性和定量研究,分析其违约的各方面原因。另一类文献对整个民企范畴(包括上市和非上市企业)信用风险和违约特征的定性分析(叶宇鹏、王兆琛等,2018;蔡喜洋,叶紫薇,2020),阐述了我国债市实质违约现象的变化趋势,以及违约主体违约前的特征表现,如资产负债率上升,现金收支情况恶化,净利率下降等。
3.2?有关信用风险预测模型的研究
现已有大量文献提供了用于预警信用风险的因子和模型。能够反映这类风险的指标主要分为两个层面:一是宏观经济层面;二是公司财务经营层面(俞宁子,刘斯峰等,2016;陈潇澜,2018)。这些模型大多使用GDP,通货膨胀率等宏观经济指标,以及销售毛利率,资产负债率,流动比率等企业财务指标。
国内研究者已经通过运用一些机器学习算法,结合上述相关宏观经济或公司财务指标来建立债券违约预警模型(余欣媛,2017),运用Logistic模型,从财务结构、偿债能力等六个方面选取12个指标进行预测;郭兆灵(2020)选取82家企业作为样本,使用 Lasso-logistic模型进行研究,选取11项企业集团信用风险关键预警指标;陈毓敏、林日裕(2020)使用树状分支模型,构建了四种预警方法,对比发现财务因子预警较为准确可靠;赵丹丹、丁建臣(2018)采用SVM预警模型预测2009年1月~2018年9月中国银行业系统性风险水平,对比发现与BP神经网络和Logit回归模型相比, SVM模型具有较高的预警正确率;潘永明、王雅杰等(2020)使用IG-SVM模型选取137家非上市中小企业作为样本,对其信用风险进行分类预测。
4?数据与样本
4.1?数据来源
本文训练预测模型使用的数据均来自Wind数据库,包括国内企业发债数据,如发债公司名称,起息日期,到期日期,是否为上市公司等信息;国内企业债券违约事件数据,如违约主体名称,违约日期,是否为上市公司等信息;发债上市公司的财务经营指标季度数据,如资产负债率,净利率,流动比率等指标;2014年至今国内宏观经济数据,如GDP实际增长率,CPI等指标。
4.2?样本构建
样本个体的索引设定为上市公司股票代码-负债季度,根据国内企业发债数据匹配生成。其中负债季度的定义为特定上市公司负有待偿还债务的年份季度的最后一天。例如,股票代码为0000AB的上市公司发行的一支债券的起息日期为2016年1月20日,到期日期为2018年7月20日,则它的负债季度2016年3月31日至2018年9月30日中11個季度对应的最后一天,由此构成11个样本个体。无论同一家上市公司在同一季度发行多少支债券,均视为一个样本个体;若债券在某一季度违约,此后所有的原先负债季度均不被视为样本;2014年初我国出现第一例企业债券实质违约,因而2014年之前的负债季度均不计入样本。
样本个体的分类标签(y)设定为违约个体(数值1),未违约个体(数值0),根据国内企业债券违约事件数据取值。违约个体代表当季发生实质违约事件的样本个体;未违约个体代表当季没有发生实质违约事件,且对应上市公司在往后2年(8个季度)内也没有发生实质违约事件的个体。无论同一家上市公司在同一季度发生了多少次违约事件,均视为一个违约样本个体。
样本特征向量(X)包含特定上市公司在特定负债季度以前4个季度的经营财务状况指标,以及前1季度宏观经济指标。
经过清理筛选得到281个有效样本个体,违约和未违约个体个数分别为79和202。
5?模型训练方法
5.1?特征选取和处理
本文预警模型选取宏观经济,企业盈利能力,偿债能力,运营能力和现金状况五个方面指标,由季度数据整理而来,宏观经济指标以负债季度前1个季度的当期值,同一企业内部指标分为负债季度前4个季度的指标均值(季度从近到远权重为0.4,0.3,0.2,0.1),以及前3个季度的指标变化率均值(季度从近到远权重为0.7,0.2,0.1)(具体特征见表2)。
5.2?预处理与模型参数设置
使用sklearn模块对样本集进行数值标准化和归一化的预处理,以避免变量间量纲差异导致的不希望出现的变量权重差异,并将一部分样本作为训练集(training set),另一部分作为检验集(test set),以测试最终得到的模型的预测效果。
使用sklearn模块的网格搜索(GridSearchCV)功能获得7个模型相关超参数的最佳组合,即使得模型在测试集中预测准确率最高的超参数组合。共有74520个备选超参数组合,最优模型选取了如下参数值及19个特征因子。
6?模型预测表现
6.1?评价指标
为了全面评价模型的预测表现,除了基本的准确率(accuracy)指标,本文还将考察精确率(precision rate),召回率(recall rate)和F1分数(F1-score)常用分类评价指标。精确率指在所有模型判定将会违约的公司-负债季度样本中,确实发生了违约事件的样本占比;召回率指在所有实际发生违约的公司-负债季度样本中,被模型判定将会违约的样本占比;F1分数则兼顾了精确率和召回率,是最值得关注的指标,计算方式如下:
F1-score=2*precision*recallprecision+recall
6.2?模型预测表现
在得到第四部分(3)训练出的最优模型后,重复(3)中的预处理部分,得到新的测试集,用此模型进行预测并记录评价指标。为降低单个测试集带来的偏误,重复以上步骤100次,最终得到以下结果。
总体而言,均值0.963的F1分数反映出此模型的综合预测表现非常良好(100次F1分数分布见图2),其中精确率达到0.971,意味着模型有95%以上的把握确认它所预测的某上市公司下一季度的违约事件会发生;并且更具实战意义的召回率表现同样不俗,意味着市场上大约95%的上市公司违约事件会被它预测到,这最能体现出此模型的预警作用。
7?结论与建议
根据模型预测表现指标,可以看出使用宏观经济和上市公司财务经营数据搭建SMV算法量化预警模型,用于预警负债上市公司在短期未来的债务违约风险是可行有效的。风控部门应建立,维护和实时更新关于国内上市公司历史信用风险事件和重要财务经营指标的数据库,进一步区分高风险企业和低风险企业的特征,做到动态加强对上市公司违约风险事件的预警和监控。
要想构建一个好的模型,精选有效特征,做好数据的清洗筛选,对样本集进行必要的预处理,以及仔细调节模型超参数都是必不可缺的,在这一过程中,应该积极发挥机器学习算法和计算机算力的优势:可以先根据专业知识以及经验直觉,添加备选特征,通过程序的特征选择方法优选特征;添加备选参数和参数待选值,通过程序的自动调参选择最优的预测模型。
参考文献
[1]刘晓凤.中国公司债违约问题研究——以神雾环保为例[J].农村经济与科技,2020,31(06):146-147.
[2]任晴晴.富贵鸟债券违约成因及启示[J].合作经济与科技,2020,(09):72-73.
[3]叶雨鹏,王兆琛,葛馨蔚.民营企业债券的信用风险与违约特征[J].金融市场研究,2018,(08):130-136.
[4]蔡喜洋,叶紫薇.民企债券违约成因及对策[J].国际金融,2020,(05):57-61.
[5]俞宁子,刘斯峰,欧阳炎力,等.债券违约风险预警模型探究[J].中国市场,2016,(39):18-29.
[6]陈潇澜. 基于机器学习的上市公司信用风险预警研究[D].长沙:湖南师范大学,2018.
[7]余欣媛.基于logistic模型的企业债券违约影响因素的研究[J].时代金融,2017,(18):194.
[8]郭兆灵.基于Lasso-logistic回归的企业集团信用风险研究[J].财会学习,2020,(13):193+195.
[9]陈毓敏,林日裕.不同债券违约预警信号对比与解析[J].债券,2020,(03):22-27.
[10]赵丹丹,丁建臣.中国银行业系统性风险预警研究——基于SVM模型的建模分析[J].國际商务(对外经济贸易大学学报),2019,(04):100-113.
[11]潘永明,王雅杰,来明昭.基于IG-SVM模型的供应链融资企业信用风险预测[J].南京理工大学学报,2020,44(01):117-126.
- 网络直播带货中消费者知情权的保护
- 基于虚拟仿真实训的经管类学生综合能力培养模式研究
- 参与科技创新团队对大学生科研素养提升的有效性研究
- 基于资本化价值能力的大学生综合素质培养研究
- “互联网+”背景下创新创业人才培养研究与实践
- “线场研境”模式下科研成果转化为教学成果实践探索
- 论墨子技术伦理思想对人工智能发展的启示
- 高职院校园区化培养创新创业人才的绩效研究
- 疫情期间我国宅经济发展状况及完善
- 我国海外移民回流原因、阻碍及对策
- 新时代滁州农村文化发展的困境与路径
- 论坚持和完善统筹城乡的民生保障制度
- 教育支出对城乡收入差距的影响研究
- 基于独立性视角下的审计委托制度改革路径探析
- 新形势下提升公立医院财务管理能力的思考
- 进一步深化高校政府会计制度改革问题探析
- 新准则下会计核算问题研究
- 国有企业经济运行与全面预算协同管理模式研究
- 基于舞弊三角理论的天业股份财务舞弊案例研究
- 质量视角下企业财务状况分析
- 基于国际比较的中央银行社交媒体应用路径研究
- 基于管理者行为的商誉减值剖析
- K集团慈善捐赠与财务绩效研究
- 互联网潮物价值链的平台创新研究
- 加油站销量影响因素模型及实证分析
- narrowmoney
- narrow money
- narrowness
- narrownesses
- narrow sth down
- narrow sth down (to sth)
- narrow sth ↔ down
- narrow²
- narrow¹
- nasa
- nasal
- nasalisms
- nasalisms'
- nasalities'
- nasalities
- nasality
- see-through
- see-throughs
- see through sb/sth
- see-thru
- see to
- see to/attend to
- see to it that...
- see to sb/sth
- see to sth
- 翘篸
- 翘翘
- 翘翘板
- 翘翘雄雄
- 翘胡子
- 翘舌
- 翘舌音
- 翘英
- 翘诚
- 翘起
- 翘起二郎腿(儿)
- 翘起来
- 翘起来了
- 翘起的样子
- 翘起鼻子走路
- 翘足
- 翘足企首
- 翘足可待
- 翘足引领
- 翘足引颈
- 翘足抬腿
- 翘足而待
- 翘跂
- 翘踛
- 翘蹄捻脚