摘 要 本文以知网数据库中管理工程和情报学共12本CSSCI期刊5年的论文作为数据,通过AT主题模型、相似度计算识别学科间交叉主题并对其相似程度进行测度。实验表明,AT主题模型可以挖掘两个学科间交叉研究主题,并提供一定的语义描述。通过对比关键词共现的方法,本文的方法可以提供交叉研究主题更多的语义特征,并便于判断高相似度的研究主题。
关键词 主题模型? 学科交叉 主题相似度
分类号 G250
DOI 10.16810/j.cnki.1672-514X.2019.12.012
Abstract A total of 12 CSSCI journals in CNKI about Management Engineering and Information Science are used as the data foundation. Using AT topic model and similarity calculation, this paper identifies the interdisciplinary cross-topics and measures their similarity. Experiments show that AT topic model can mine the cross-topics between two disciplines and provide a certain semantic description. By comparing the methods of keyword co-occurrence, the method of this paper can provide more semantic features for cross-topics and measure high similarity research topicseasily .
Keywords Topic model. Interdisciplinary. Topic similarity.
0 引 言
学科交叉反映了学科之间的内在联系,体现了不同学科之间知识的交流与融合。从信息转移的视角来看,学科交叉的产生是由于其它学科的信息转移进入到该学科并进行了整合的结果,这种信息转移产生的一个主要特征就是学科之间研究主题的交叉重叠,对其进行测度可以反映学科之间研究域的交叠和属性的相似程度。学科交叉是众多学科之间的相互作用而交叉形成的理论体系,其本质是一种科研行为[1]。具体表现形式为:两门或两门以上学科间研究内容和方法存在横向的联系,进而建立起来的有机组织体系和结构。从这个角度来看,学科交叉是多个传统学科跨越学科边界的学科间研究对象的整合,是一种跨学科研究。
宏观层面的学科交叉研究主要是通过期刊引文关系或关联规则挖掘等方法,用以识别学科间的交叉关系以及相关性的强弱;微观层面的学科交叉研究主要以关键词或主题词为基础,挖掘学科间交叉的研究热点。然而,现有的研究鲜有从学科研究主题入手研究学科交叉问题,也缺少对学科间研究主题相似程度进行量化分析。
Sydney J .Pierce在总结学科交叉现象时指出,学科间的“借用”是最有影响的学科间信息转移方式。所谓“借用”,即研究者借用其他学科的理论和方法,并把它们引入自己所研究的领域[2]。这种借用表现在学科之间研究主题的相似性,因此,从知识产出上来看,对学科间研究主题融合现象的度量相比从引文分析、团队合作、关键词等角度更能表征知识间的相互渗透。
为此,本文将结合Author TopicModel模型,以情报学、管理工程两个学科CSSCI期刊的学术论文为研究对象,研究学科交叉的问题,并就学科间主题相似程度进行量化分析。
1 研究现状
国外最早关于跨学科的研究出现在1926年[3]。20世纪70~80年代,学科交叉进入了理论研究阶段,并展开了促进学科间交流合作的探讨。2004年,Rhoten等人在Science上发文,阐述了学科交叉对开展大学科研项目的意义和前景[4]。
学科交叉研究大多依据共类分析(Co-classification Analysis)的思想[5]。共类分析是指将学术论文按照期刊归属到特定的主题类别中,然后再将主题类别归属到更大的学科中。由于论文或期刊会被归属到不同的主题类别,因此从期刊分类视角分析论文所属学科能够体现学科的交叉性。侯海燕等[6]以Web of Science数据库收录的生物医学工程领域论文所属期刊的学科分类为数据基础,利用学科共现分析方法,结合Bibexcel、Ucinet社会网络分析软件建立学科关联网络图谱,识别生物医学工程领域学科交叉的结构演化特征。
在学科交叉研究中,比较常用的方法是借助于研究领域间的引文关系,对跨学科的学科间相互渗透进行研究。基于引文分析的学科交叉研究主要是从某一学科的引文入手,分析其引文的主题归属,实现两个学科间交叉程度的测度。例如:Porter曾提出类别外引文法(Citations Outside Category),即通过测度引文中属于学科类别以外的引用比例来分析学科之间的交叉程度[7]。Small则通过对期刊论文之间的共引数据,通过聚类,分析学科间的交叉性和相似性[8]。在学科交叉变化趋势方面,Hammarfel等人利用Web of Science的引文数据,测度了34种期刊在不同时期内的引文专题变化趋势,来衡量某一学科的跨学科情况[9]。在多学科之间的交叉测度方面,采用引文分析,由于公式复杂,测度过程繁琐,因此相关的实证研究还不多[10]。
期刊论文的关键词是学科交叉微观研究中常用的方法。由于关键词是表达期刊论文主题的自然语言词汇,通过关键词的共现、聚类等操作可以从微观层面上识别学科之间的内在联系。关键词的共现可以表征学科间的交叉性,共现分析的研究思路是:分析关键词在不同学科领域期刊论文中共同出现的情况,通过统计共现频次反映学科之间的交叉程度。例如:某关键词在两个学科领域高频次地出现,则可以认为该关键词(或知识单元)可以作为两个学科交叉的研究内容。闵超等[11]通过构造了两门学科核心期刊论文规范化的关键词交集,从中获取两门学科的高频交叉关键词及其共词矩阵,借助社会网络分析方法,探讨两门学科交叉研究热点领域的整体特征。李长玲等[12]则利用社会网络分析(Social Network Analysis, SNA)方法,以情报学与计算机科学为例,对两个学科在2006—2010年间文献的关键词集合进行共现分析,形成了两门学科交叉文献的关键词共词矩阵,进而挖掘主要交叉研究领域与潜在研究主题。虽然期刊论文的关键词可以从微观层面识别学科间的交叉情況,但由于关键词语义范围不一致,对学科交叉研究的主题描述上存在一定的缺陷。
综上所述,目前该领域的研究主要是以期刊作为学科分类,从论文引文关系或关键词共现的思路入手,对学科交叉程度及变化趋势进行研究。而从学科研究主题入手,分析学科交叉的研究还不多。本文将着眼于学科研究主题,以主题为视角探讨学科交叉问题。
2 方法设计
2.1 Author-Topic Model
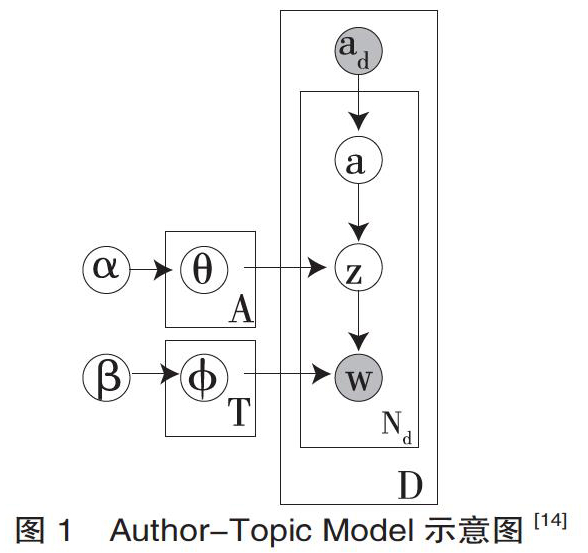
主题模型是一种层次贝叶斯模型,可以识别大规模文档集合中隐藏的语义信息。为解决作者对论文主题分布的影响,Mccallum[13]提出了单一主题的作者模型,该模型假设任何一个作者都对应一个特定的主题或语言模型。该模型忽略了作者之间主题共享问题,在实际应用时存在一定的不足。为解决这一问题,Author-Topic Model(简称AT模型)实现了主题模型和单一主题的作者模型的折中,对每个作者不再限定在一个主题内,可以有效识别研究人员在学术专长与研究方向上的关联。图1为AT模型的示意图。
AT主题模型将作者的兴趣偏好及文档的内容信息融合在一起。模型中,θ为“作者-主题”概率分布,φ表示“主题-词项”的概率分布; α和β为Dirichlet分布的先验参数,其中α表示为“文档-主题”概率分布先验,β则表示为“主题-词项”的概率分布先验,参数A表示作者的数量,T为主题数量;ad表示文档d由一个或多个作者完成,a为作者,z表示主题,w为词项,D为所有文档组成的集合,Nd则表示采样的次数[14]。
AT模型是LDA主题模型解决特殊任务的一种演化模型,如果每篇文档只有一个作者,AT模型就变成了LDA模型。模型假设一个作者对应在一个主题上分布,并用“作者-主题”分布取代“文档-主题”分布。模型不仅实现了多个作者在同一主题上的分布,也允许多个作者共享一个主题集合。AT模型能够从大量文档中挖掘出作者存在相同研究主题之间的关系,能更好地获取作者与论文对应的主题分布,进而揭示出不同作者之间具有相同的兴趣和偏好。
2.2 研究假设
目前,学科分类组织的形式是按照知识组织方式進行划分的,属于典型的知识树层级分类体系。树层次结构中,知识体系处于树的顶端,知识体系的分支代表不同的学科,每个学科又由子学科或专业组成。这种树状结构体现了学科分类的精细化和专业化。
学术期刊是领域科学知识的重要载体,反映某一细分子学科的研究热点及动态,期刊论文则形成了学科学术成果集合。借助主题模型算法,可以挖掘学科学术成果集合的总体内容特征,揭示集合所隐含的主题信息[15]。如果两个成果集合存在相同(或高相似)的主题,则可以认为两个集合之间存在知识的融合和交流。
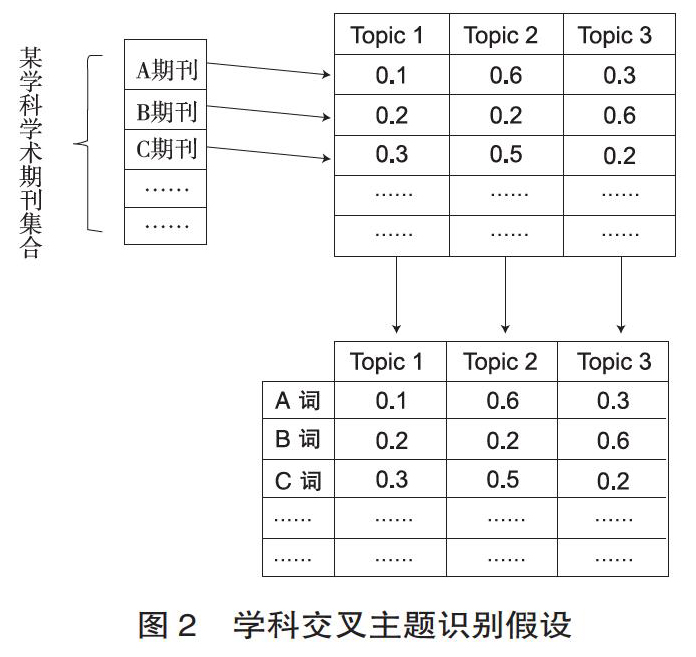
基于这个假设,本文采用AT模型进行学科交叉的研究。首先,如果把每本期刊的所有论文看作是由多个“作者”共同完成的知识集合,那么这些“作者”在期刊论文“撰写”过程中会形成若干个研究主题,而这些研究主题将可以代表学科的领域特征。在该假设下,AT模型中的“作者-主题”的分布将随之消失,被“期刊-主题”(或“学科-主题”)的分布取而代之。如2图所示,某学科的期刊文献集合,通过AT主题模型进行主题求解,可以发现,主题Topic2在A期刊和C期刊都具有较高出现概率,依据上文假设,Topic2所对应的主题词是A和C两本期刊存在交叉研究的主题。
为此,通过AT模型获取的主题将能更加抽象地表达学术期刊研究兴趣和偏好,能更好地浓缩期刊的研究主题。如果再将学术期刊的主题归属到更大的学科中,将形成以学科为分类标准的主题集合。对比不同学科所形成主题集合,将有助于识别和测度学科(或专业) 间研究主题的差异及融合情况。
基于这一假设,本文将AT模型引入学科交叉研究,通过识别学术成果集合中的主题信息,探索学科间研究主题的相关性,并尝试挖掘知识间融合的内容及特征。
2.3 研究思路
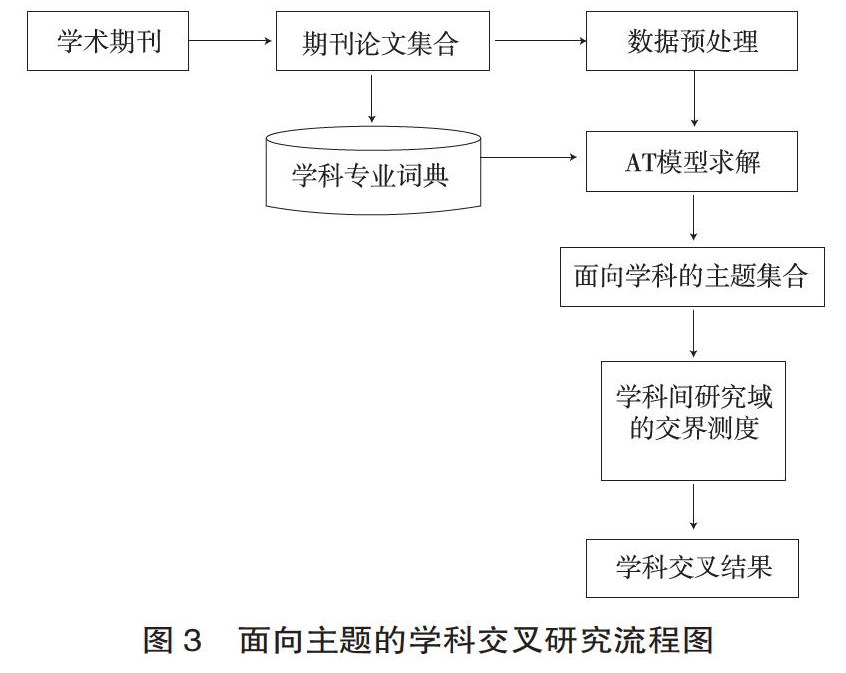
本文的研究思路如图3所示,主要分三个步骤。
(1) 获取基础数据及数据预处理。学术论文是本文学科交叉研究的基础,本文以CSSCI期刊学科分类为依据,获取不同学科的期刊论文,将论文摘要作为分析的基础数据,通过知识描述的规范化处理以及分词操作,实现文摘的降维,并生成主题求解所需的语料库。
(2) 主题求解。这一步是学科交叉主题识别的核心,依据2.2的研究假设,本文首先生成“期刊-摘要”的数据集,随后采用AT模型对数据集进行主题求解,并抽取每本期刊的高概率研究主题,最后将期刊主题归属到学科中,形成以学科为单位的主题集合。
(3) 学科间研究域的交叠测度。为了描述学科间研究主题的交叠情况,本文对主题相似度进行计算,并形成学科间研究主题的相似度矩阵,通过热力图实现可视化的展示。
3 实验与结论
3.1 实验数据
本文在知网数据库中,选取情报学、管理工程两个学科的12本CSSCI期刊,并下载2012年1月至2017年3月的学术论文,共获得17 870篇论文,其中管理工程4 862篇,情报学13 008篇。期刊的选取情况如表1所示。
对于获取的源数据,需要进行预处理操作。为便于AT主题模型进行主题求解及对摘要文本进行降噪,对下载的论文摘要需要进行分词和去停用词处理。由于学者在摘要撰写时对知识的描述存在不同的形式,如:k-means聚类和k均值表示的是一个知识内容。为此,本文借助《汉语主题词表》 形成规范的知识描述,结合领域专家的知识,形成学科专业词典,对获取的摘要文本进行规范化处理。随后,本文针对论文摘要的撰写特点,构建用户自定义停用词表,将“结论”“论述”“目的”“意义”“文中”等高频、无意义的词汇进行剔除。本文采用Python2.7和jieba分词组件进行分词操作。预处理完成后,本文获得了原始的语料库,如图4所示。
图4中,语料库按照期刊进行分类,文本的第一个字段为期刊名,后面则为该期刊论文摘要分词后的结果,期刊名与词项之间用制表符(Tab键)分隔,词项之间用“:”进行分割。
3.2 AT模型主题求解
主题模型求解过程中,主题数量T的确定将直接影响主题计算的效果。对于T值,一般来讲语料库越大,主题的数量越多,反之亦然。
主题模型主题数的确定,目前比较常用的方法是采用统计语言模型进行指标评价[16],依据该思想,本文采用python编写主题模型的困惑度程序。困惑度为文档集中包含的各句子相似性几何均值的倒数,随句子相似性的增加而逐步递减,取值越小表示性能越好。实验中,曲线在100的位置出现了一个明显的最低点,为此本文在实验中选取的T值是100。最终,AT模型的参数设置为:T=100,alpha=0.01,β=0.1,每个主题由6个主题词进行描述。
实验中,本文按照图2所示的方法,对每本期刊选取概率最高的20个主题,然后再将这些主题归属到对应的学科中,通过去重,最后获得两个以学科为单位的主题集合。这两个主题集合分别存储了两个学科中概率较高的主题。两个主题集合的具体数量为:管理工程39个主题,情报学49个主题。通过对主题号的识别,本文发现管理工程和情報学之间有3个交叉研究的主题,具体如表2所示。
3.3 主题交叉分布特征及讨论
为进一步识别学科间研究主题的交叠程度,本文计算了两个主题集合中每个主题之间的相似度。
文本相似度计算的基本思路是:将文本的内容转换为多维空间中的点,实现文本内容的向量运算。实验中,本文首先采用TF-IDF对每个主题中的主题词进行权重衡量,随后结合余弦相似度的方法来计算主题间的相似性,步骤如下:
(1) 使用TF-IDF分别对两个主题集合中的每个主题词进行权重计算,然后按照学科形成两个主题词向量词集Z1和Z2;
(2) 从两个主题词向量词集中各选一个主题,Z1'和Z2';
(3) 计算向量集合Z1'和Z2'的余弦相似度,即:sim(Z1',Z2')=cos(Z1',Z2');
(4) 重复(2)和(3),完成Z1和Z2中所有主题的相似度计算。
根据以上思路,本文采用Python开发了相关程序,计算两个学科主题集合中每个主题的相似度,并形成了主题相似度矩阵。然后利用R语言绘制了主题相似度的热力分布图,具体结果如图5所示。
在图5中,横轴为管理工程研究主题,从左到右,主题在学科中出现概率不断降低;纵轴为情报学研究主题,从下往上,主题在学科中出现概率不断降低。左下角是两个学科高概率研究主题的区域,右上角为两个学科低概率研究主题的区域。从图中可以发现,代表两个学科高概率主题区的左下角,基本没有交叉,说明两个学科均有各自“核心”研究领域及研究范式和方法。图中深颜色的区域主要出现在热力图的右半部分,从分布上来看,较深颜色的区域均处在两个学科研究概率相对不高的位置。除了3个交叉研究主题外,两个学科间还存在相似度较高的主题。这表明,在两个学科间存在着同时关注的主题词,形成了共同关注的研究领域。为此,本文通过技术处理,获得了两个学科间相似度较高的共同关注主题,如:舆情、技术竞争情报、信息质量、意见领袖等。
除此以外,本文还挖掘了两个学科之间基本没有相交的主题,即相似度为0的主题。具体如表3所示,这在一定程度上体现了不同学科研究的各自学科特有性。
3.4 对比试验
为了验证本研究获取主题的效果,本文采用学科交叉研究中,常用的关键词共现方法进行实验对比。对比实验采用本文预处理后获得的两个学科关键词作为共词分析,采用BibExcel构建共词矩阵,获取了两个学科之间关键词共现词对,具体如表4所示。
对比表2和表4,可以发现,共词分析的结果虽然也可获得具有语义关系的词对,但在语义表现方面AT主题模型效果更好。同时,虽然共现频次可以反映这种交叉出现的次数,但无法从频次上分析研究主题在两个学科中的概率特征,也无法挖掘更多的共同关注的主题词。
4 结 语
期刊论文反映了学科研究的成果,通过主题模型可以发现多学科之间研究主题的交叠和关联。本文提出了一种通过AT模型进行学科交叉研究的思路,实现了期刊论文研究主题的识别,并进而实现了学科交叉的应用研究,为学科交叉的实践提供了一种新的思路。通过数据处理、主题建模、结果统计分析等过程,本文获得相关的实验结论。
为了进一步提高该方法的应用性,本文认为该方法还需要从以下两个方面进行完善。
(1) 知识的流动和传播方向。本文使用的AT模型,可以有效识别期刊的研究兴趣和偏好,进而将期刊的研究主题归属到学科中,实现学科交叉的研究。但该方法无法挖掘知识的流动和传播方向,而知识的流向在学科交叉研究中有助于分析学科的多样性和影响力。为此,进一步的工作需要增加这方面的研究。
(2) 方法应用方面。本文通过实证研究已经初步发现利用主题模型可以更好地识别学科之间研究域的交叠。下一步将在主题识别的基础上,结合主题共词分析等方法进行更多的应用研究。
参考文献:
路甬祥.学科交叉与交叉科学的意义[J].中国科学院院刊,2005,20(1):58-60.
PIERCE S J. Boundary crossing in research literatures as a means of interdisciplinary information transfer[J].Journal of the American Society for Information Science, 1999,50(3):271-279.
刘仲林.交叉科学时代的交叉研究[J].科学学研究,1993(2):11-18.
RHOTEN D. Education: risks and rewards of an interdisplinary research path[J].Science, 2004, 306(5704): 2046.
TIJSSEN R J W. A quantitative assessment of interdisciplinary structures in science and technology: co-classification analysis of energy research[J]. Research Policy, 2004,21(1):27-44.
侯海燕,王亚杰,梁国强,等.基于期刊学科分类的学科交叉特征识别方法:以生物医学工程领域为例[J].中国科技期刊研究. 2017,28(4):350-357.
PORTER A L, CHUBIN D E. An indicator of cross-disciplinary research[J]. Scientometrics,1985,8(3-4):161-176.
SMALL H. Maps of science as interdisciplinary discourse: co-citation contexts and the role analogy[J].Scientometrics, 2010(83):835-849.
HAMMARFELT B. Interdisciplinarity and the intellectual base of literature studies: citation analysis of highly cited monographs [J]. Scientometrics,2011,86(3):705-725.
李长玲,纪雪梅,支岭.基于E-I 指数的学科交叉程度分析:以情报学等5个学科为例[J].图书情报工作,2011(6):33-36.
闵超,孙建军.基于关键词交集的学科交叉研究热点分析:以图书情报学和新闻传播学为例[J].情报杂志, 2014,33(5):76-82.
李长玲,郭凤娇,支岭.基于SNA的学科交叉研究主题分析:以情报学与计算机科学为例[J].情报科学, 2014,32(12):61-66.
MCCALLUM A. Multi-label text classification with a mixture model trained by EM[C].AAAI workshop on Text Learning. 1999:1-7.
ROSEN-ZVI M, GRIFFITHS T, STEYVERS M, et al. The author-topic model for authors and documents[C].Proceedings of the 20th conference on Uncertainty in artificial intelligence. AUAI Press,2004:487-494.
阮光冊,夏磊.基于主题模型的检索结果聚类应用研究[J].情报杂志,2017,36(3):179-184.
GRIFFITHS T L, STEYVERS M. Finding scientific topics[C].Process of the National Academy of Sciences, 2004,101:5228-5235.
夏 磊 上海图书馆会展中心副主任、副研究馆员。? 上海,200031。
(收稿日期:2019-01-24 编校:谢艳秋,刘 明)
- 关于做好学会工作的几点思考
- 中专学校科协开展科技社团活动研究
- 提升学会评估等级 有效承接政府转移职能
- 县级学会建设与发展
- 推进城乡公共文化服务均等化建设的对策研究
- 新时代党建工作在社会组织中的重要性
- 社会组织人力资源管理的困境与消解
- 创新驱动助力工程实施评估体系的构建
- 新形势下高校科协开展科普工作模式创新
- 政府购买社会组织公共服务的英国经验及启示
- 社会工作行业组织建设中的问题及对策研究
- 社会治理创新与社会组织女性创业者发展研究
- 塑造5A级社团组织服务“五个泉州”现代化建设
- 法国科技评估制度简析及对我国的启示
- 深化学会治理改革建设创新国家
- 劳动力外出务工对养殖技术效率的影响
- 中国旅游业碳排放效率及其时空跃迁
- 战略柔性研究述评与展望
- 论《庄子》中存在性之“道”的三重意蕴
- 协同创新:发展中国特色人文社会科学的理想选择
- 乡村治理主体:对民国时期黄河流域乡村内生性精英的微观考察
- 理顺党政关系:地方治理体系的优化
- 改革开放40年以来中国应急管理变迁
- 小额贷款公司风险承担与社会绩效
- 品牌微博如何吸引用户参与
- contingent worker
- contingent²
- contingent¹
- continuable
- continual
- continual/constant
- continualities
- continuality,continualness
- continually
- continualnesses
- continuation
- continuations
- continuations'
- continue
- continue/carry on
- continued
- continuedly
- continuedness
- continuednesses
- continuedness's
- continuer
- continuers
- continues
- continue to be
- continuing
- 短后齐俗
- 短吨
- 短命
- 短命与长寿
- 短命由死
- 短命的货
- 短命花
- 短命鞋
- 短命鬼
- 短命鬼儿
- 短命,早死
- 短嘴狗
- 短墙
- 短处
- 短夜
- 短嫩颠儿
- 短学
- 短学期
- 短寿促命
- 短封
- 短小
- 短小丑陋
- 短小的兵器
- 短小的文章特别需要写得简洁和优美
- 短小的样子