林凌+杨程程+林夏玉
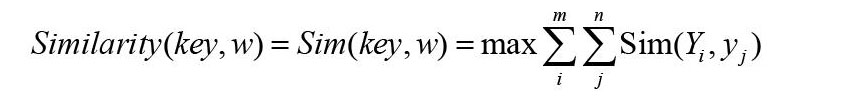
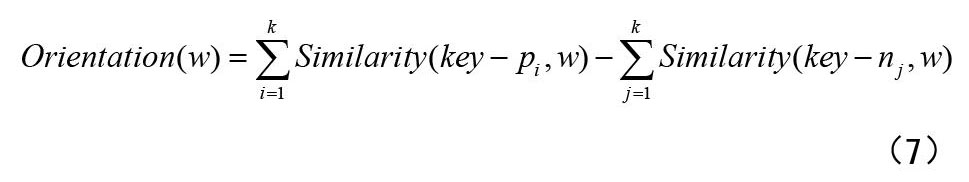
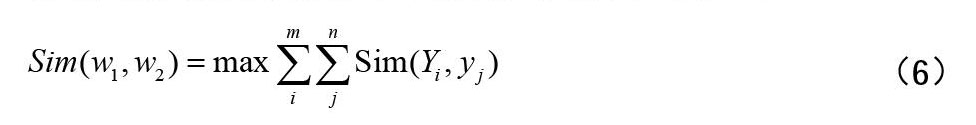
[摘 要]面对民众观点日益沸腾的互联网时代,如何理解网络舆情的倾向性,并且对舆情加以合理的引导是一个日益重要的课题。本文利用PLSA模型对不同时间段上的网络舆情话题进行子话题提取,采用基于HowNet的语义相似度模型对相应的子话题进行情感分析,通过与阈值的比较得出该话题的褒贬程度。
[关键词]话题特征词;PLSA模型;语义相似度;情感倾向性
doi:10.3969/j.issn.1673 - 0194.2016.22.098
[中图分类号]TP393.09 [文献标识码]A [文章编号]1673-0194(2016)22-0-02
0 引 言
随着互联网的快速发展,网络逐渐成为民众取得和发布信息的主要平台。但是,正是由于网络的便利性和虚拟性,网络信息的真实性鱼龙混杂,而面对稂莠不齐的信息源,广大民众不仅能够随时随地接收,还能够任意转发。对网络舆论进行适当的引导是非常必要的,否则可能引发不良后果,以致形成一定程度的恐慌,更进一步影响到其他民众的正常社会生活。
因此,准确了解公众的看法,对普通民众情绪进行及时有效的引导是人们一直以来不断努力的方向。本文试图通过PLSA模型和基于HowNet的语义相似度模型,探究网络舆情的情感倾向性,从而提出对策,以满足政府和企业舆情监控以及控制的要求,为政府机构舆论引导的方向和内容提供依据明确的参考。
1 网络舆情情感倾向性分析模型
网络舆情话题情感倾向性分析模型共分为2个部分:话题提取和情感分析。其中话题提取主要采取的是PLSA模型,情感分析主要采取的是基于HowNet的语义相似度模型。
1.1 话题提取
1.1.1 文本采集
本文研究的是网络热点事件的情感倾向性,因此在数据采集过程中,首先要确定一个网络热点事件,然后利用网络爬虫到知乎、豆瓣、微博、新闻等平台上获取该网络热点事件的信息。
1.1.2 文本分词
本文主要采用ICTCLAS汉语分词系统。具体ICTCLAS文本分词处理过程如图1所示。
采用Java编程实现初步文本分词,再利用停用词表和Java程序,进行停用词处理,从而得到相应的文档-词共现矩阵。
1.1.3 子话题抽取
采用PLSA模型对子话题进行抽取,生成k个子话题,并得到特征词在k个子话题上的概率分布。具体PLSA模型的应用如下:
PLSA模型,全称为概率潜在语义分析模型,将概率统计模型与EM算法相结合,实现对子话题的抽取。PLSA的概率模型图,如图2所示。
其中D表示文档,Z表示主题,W表示观察到的单词。
在该PLSA概率模型中,已知(di,wj),Zk是隐含变量。则(di,wj)的联合分布见公式(1)。
其中,P(zk|di)和P(wj|zk)都对应多项式分布,笔者通过最大期望(Expectation Maximization,EM)算法来估计多项式分布中的参数。该算法主要分为E步骤和M步骤,然后进行迭代求解。
针对PLSA模型中的参数估计,在E步骤中,使用贝叶斯公式直接计算Zk的后验概率,见公式(2)。
在M步驟中,是利用E步骤中的后验概率求得P(zk|di)和P(wj|zk),然后进行迭代求解,得到参数值见公式(3)、(4)。
1.2 情感分析
本文对网络舆情情感倾向性的分析主要是通过对话题特征词倾向值的度量,判断该网络热点事件的褒贬程度。其中,默认0为阈值,即倾向值大于0时判断为褒义,小于0时则判断为贬义。
对于话题特征词倾向值的度量,本文是基于知网HowNet,进行语义相似度的计算,从而计算得到相应的情感倾向值。在知网中,词语是通过义原来描述的,所以将词语的情感相似度转化为义原的情感相似度。义原相似度的计算公式为式(5)。
其中,α为权值,w为词语。
将最大的义原相似度作为词语相似度,公式为(6)。
其中,y词语的义原。
假设共有k对基准词,则单词w的语义倾向值计算公式(7)。
其中,key-pi、key-ni分别为褒义基准词、贬义基准词,Orientation(w)为单词w的语义倾向值:
通过加权求和可以得到特征词的情感倾向性值。
2 基于话题特征词的情感倾向性实证分析
笔者通过实例进行分析,从而验证本文所提网络舆情情感分析方法的可行性。本文以2016年5月份的热点舆论“江苏高考减招”作为本文情感倾向性分析的对象。利用网络爬虫来爬取新浪微博2016年5月9日到5月11日关于“江苏高考减招”话题的所有微博,设置的时间间隔为1天,划分实验预料,在5月9日到5月11日这个时间段,新浪微博中关于这个话题的讨论热度从热烈到逐渐平缓,因此,选择这个时间段对舆情情感的变化和分布进行探究。
2.1 PLSA舆情子话题抽取
笔者将半结构化信息处理后,得到纯文本语料。随后,进行分词统计并且构建“文档-词语”的共现矩阵。接着,采用PLSA模型进行子话题抽取,得到每时段子话题及其概率矩阵。表1列出了抽取的4个时间点的子话题,以及出现概率在前5位的话题词及其概率。
在表1中,整个时间段都被一个子话题贯穿,计算后,两个子话题之间语义上的关联度均大于本文设定的阈值0.5,因此,子话题“北京本科率”存在语义上的延续性。
2.2 基于特征词的情感词提取
本文以5月9日江苏高考减招消息出现当天所产生的一个子话题为例,首先将与本话题有关的文本进行资料筛选;随后,重新进行分类整理;接着,依据特征词的不同,将句子保存到不同的特征词文档中,整理与之相对应的情感词。
笔者通过BIYING搜索引擎对上述得出的情感词进行搜索,选择出现频率最高的词汇作为基准词,选取依据为按照返回的Hits数进行排序的词组,再以特征词“减招”的情感关键词为例,通过基于How-Net的词汇倾向性计算方法得到部分词汇的倾向值,如下表所示:
通过计算,最后可得到5月9日“江苏高考减招”子话题中的特征词“减招”的情感倾向值。计算的结果表明,对于江苏高考减招,多数民众认为这一项新政策十分不公平,并且对此怀有强烈的愤怒和不满情绪,但值得注意的是,尽管不满情绪高涨,超过半数的群众还是会接受这项政策。
3 结 语
网络舆情情感倾向性分析主要包括子话题抽取和情感分析两大部分。而本文在这两大部分上都进行了一定的创新,主要创新在子话题的抽取上采用Thomas Hofmann的PLSA模型,在情感分析上采用了基于HowNet的语义相似度分析。但是,这些模型仍然需要进一步改进。第一,将不同的句子结构都统一看成是陈述句进行分析,并没有考虑其对情感表达的影响,就像反问句就与陈述句有完全不一样的句意表达效果。第二,该模型需要花费大量的时间进行文本资料的人工整理,在大数据时代下,此种模型的实用性略差。所以未来的工作主要就是将现有的模型实现完全智能化,降低人工成本;考虑语法、句子结构等因素,得到更准确的情感倾向性。
主要参考文献
[1]黄卫东,陈凌云,吴美蓉.网络舆情话题情感演化研究[J].情报杂志,2014(1).
[2]黄卫东,林萍,董怡,李宏伟.基于话题特征词的网络舆情参与情感演化分析[J].情报杂志,2015(11).
[3]Thomas Hofmann. Unsupervised Learning by Probabilistic Latent Semantic Analysis[J].Machine Learning,2001(1/2).
- 立足电子书包 铸造合作学习的数学课堂
- 基于信息技术的小学语文微习作教学探究
- 小学数学课堂中学生学习兴趣的激发策略
- 小学美术教学中对学生的审美能力培养
- 发挥游戏功能 促进英语学习
- 让初中生能说会道
- 论小学歌唱教学中,真假声的巧妙结合
- 匠心汇聚
- 核心素养下小学美术高效课堂的构建策略
- 浅谈小学体育课堂教学中的预设与生成
- 借助三大策略,激活音乐通感
- 小学美术课堂中“自助餐”式作业设计的实施
- 译林版英语四上Unit4 I can play basketball(Fun time,Sound time,Song time)磨课
- “冻”与“动”
- 妙用微信开启小学英语教学新天地
- 享受阅读绘出精彩
- 依托教材 联系生活 促进表达
- 过程写作法在初中英语写作教学中的运用
- 关于初中英语阅读教学中学生思维能力的培养
- 合作学习在高中英语教学中的实践探索
- 把课堂还给“主人”
- 优化小学语文课堂教学的策略与思考
- 支架式教学在小学语文课堂中的应用研究
- 语文课堂培养小学生的写字兴趣
- 关于培育核心素养时代小学语文教学改革创新追求的思考与探索
- be had
- be hailed as
- behalf
- behalves
- be handed down
- be handicapped
- be/hang in the balance
- be happening
- be hard at work
- be hardened to
- be hard hit (by sth)
- be hard of hearing
- be hard on
- be-hard-on
- be hard put to do sth/be hard pressed to do sth
- be hard to stomach
- be hard up for sth
- be haunted by
- behave
- behave badly
- behaved
- be/have nothing to do with
- behaver
- behavers
- behaves
- 平静明净的水
- 平静清澄
- 平静温和
- 平静的心情
- 平静的样子
- 平静的水波
- 平静的水流
- 平静的水面
- 平静,宁静
- 平面
- 平面人
- 平面几何
- 平面图
- 平面媒体
- 平面对称
- 平面广告的创作
- 平面或物体表面的大小
- 平面波
- 平面设计
- 平面镜
- 平韵
- 平顶
- 平顶子
- 平顶屋
- 平顶帽