周家宁

摘 要: 随着电子信息技术的飞速发展,计算机同声传译技术已经拥有了可行性。但是由于目前理论研究水平的不足,以及语音识别情形的多变性和复杂性,例如小语种识别和方言的识别还有待完善,因此同声传译的准确性和实时性还有很大的提升空间。结合实践,研究了同声传译的发展历史和目的意义,以及探索了语音识别和机器翻译的理论基础,并着重研究了语音识别和机器翻译的实现方法,并设计了一个基于c#语言的同声传译系统。由于同声传译系统非常贴近我们的生活,因此研究结论就具有很大的研究意义和实用价值。
关键词: 语音识别;机器翻译;c#语言;同声传译
中图分类号: G4????? 文献标识码: A????? doi:10.19311/j.cnki.1672-3198.2019.12.089
0 前言
随着信息技术的飞速发展,语音技术已经悄悄走入人们的生活中。它包括语音识别、语音合成、关键词检出、说话人识别与确认、口语对话系统等,是现代人机交互的重要方式之一,具有广泛的应用前景。其中语音识别技术,尤其是连续语音识别技术,是最基础、最重要的部分,而且已经逐步走向成熟与实用。
到目前为止,语音识别已经广泛运用到车载设备、智能手机等产品当中,为生活带来了极大的便利。从目前的成果来看,技术已经可以相当准确地识别出朗读式发音的信号,但这对说话者的发音要求较高,一旦出现非标准发音、儿化音或是连读等现象,识别出的纸面信息就会出现较大偏差。因此,本文将围绕以基于c#语言设计有正常识别、断句等基本功能的同声传译研究产品为中心展开,并尝试探究提高识别生活化语言的准确率的方法。
1 同声传译的发展概述
对自动的语音识别的研究,可以追溯到上世纪50年代,美国最先出现了识别英文数字的系统,中国也随后设计出了识别元音字母的“识别器”。从此,这项新型技术开始进入科学家们的视野。
上世纪70年代左右,语音技术有了较大突破,尤其是小词汇量、特定人、孤立词的识别方面,取得了许多实质性的进展,产生了象线性预测分析技术、动态时间规整算法、矢量量化技术等手段。
上世纪80年代中期,随着隐马尔可夫模型(HMM)的广泛应用和研究,语音识别的任务得以由连接词向连续语音扩展,并陆续出现了许多基于 HMM 模型的语音识别系统,比如DRAGON公司的dragon dictate系统。
语音技术的市场化是从上世纪90年代开始的,例如IBM的 ViaVoice 系统以及 L&H 、Philips、Dragon等公司的听写机等产品。这标志着实用领域对语音技术的需求,也不断推动着它向生活化、口语化信息识别的方向进步。
另外,关于机器翻译的研究,同样也是起源于上世纪五十年代初。1954年,IBM与美国乔治敦大学合作公布了世界上第一台翻译机IBM-701,它可以将俄文翻译成英文。然而在巨大的身躯之下,这台翻译机仅仅存储了6条文法规则和250余个单词,效率相当低下。
在之后的很长一段时间里,翻译系统发展停滞,并且只局限于单词对译,无法矫正语法。直到上世纪末,日本京都大学教授提出来基于实例的翻译这一跨时代的思路,刺激了领域的发展,机器翻译进入了新的纪元。
一直到近十年,机器翻译系统都沿用了基于实例这一思路,并不断完善着、补充着,创新出了基于统计的翻译体系。也就是这十年,机器翻译系统开始与语音识别系统合作,完成较为复杂的工作——同声传译。
可以说,同声传译是一门刚开始发展的新兴技术,还有着以语音识别准确率为主的问题等待不断改善,具有很大的提升空间。而隨着世界各地间交流的频率不断上升,无论是上到国家会议,还是下到平常的生活当中,同声传译都具有极高的利用价值和现实意义,它的快速发展是社会所必需的。
2 同声传译的目的及意义
同声传译系统的根本目的在于即时地解决面对面(或实时)跨语言交流的问题,为人们的沟通、交流、合作提供便利。如今,同声传译系统已经广泛应用于电子词典、旅游app、电话会议、电视转播等不同地方。
本文所设计的同声传译产品,旨在面向大型会议,为跨语言会议交流提供便捷。理想状态是,在中文发言者讲话的同时,系统自动收录识别语言信息,在大屏幕上提前设计好的界面上打出相应的汉语文字,并在下一个栏目中实时将其翻译成英文句子,供台下英语语种的听者观看、参考。
这样,可以大大减少会议用于翻译的时间,使英语听者可以实时跟上汉语发言者的节奏,提高会议的效率和互动性。除此之外,本系统的使用,也可降低会议对翻译官的需求,减少该方面的支出,从而为公司或是项目组等减少财力负担。
3 同声传译的研究方法
3.1 语音识别的研究方法
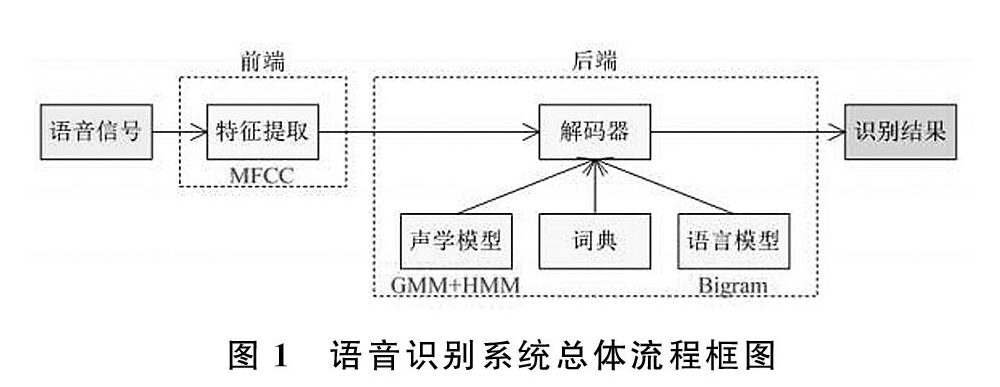
总的来说,语音识别系统的总体框架如图1所示,一般语音信号会先经过VAD操作,切除语音信号的静音段的无效信息,然后对语音信号进行特征提取,提取MFCC特征,然后MFCC特征经过解码器的解码,得到最终的识别结果。其中解码器需要综合考虑声学模型和语言模型两部分的评估信息,以及词典信息,生成解码图,通过搜索解码图找到最优路径,得到可能性最大的次序列。
语音识别的研究方法有很多,大致可以分成传统语音识别方法和基于深度学习的语音识别方法。传统语音识别方法包括模板匹配法、模式识别法、HMM-GMM方法、基于极大似然估计的方法等;基于深度学习的语音识别方法包括DNN-HMM模型,端到端模型(End to End),RNN+LSTM+HMM模型等。
3.2 机器翻译方法
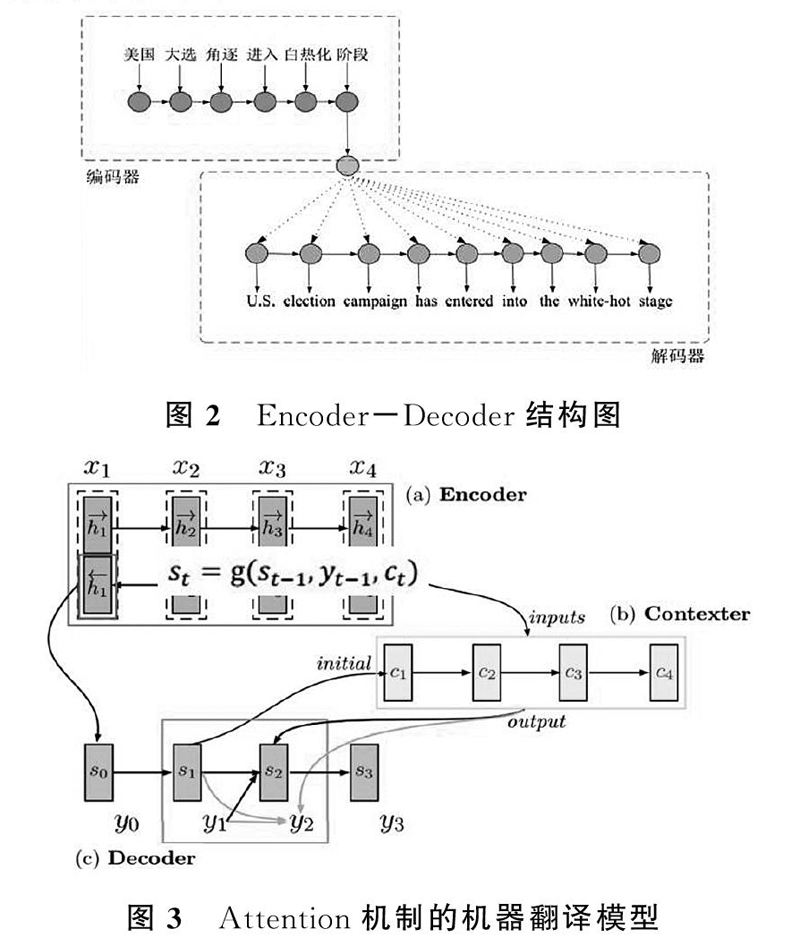
机器翻译方法分为传统的和运用神经网络的两种。传统的机器翻译方法按照其基本工作原理,可以分为基于规则的机器翻译,基于实例的机器翻译和统计型的机器翻译这三种基本类型。神经机器翻译指直接采用神经网络以端到端方式进行翻译建模的机器翻译方法。这里着重介绍一下采用注意力机制的神经翻译系统。
神经机器翻译采用一种简单直观的方法完成翻译工作:首先使用一个称为编码器(Encoder)的神经网络将源语言句子编码为一个稠密向量,然后使用一个称为解码器(Decoder)的神经网络从该向量中解码出目标语言句子。上述神经网络模型一般称之为“编码器-解码器”(Encoder-Decoder)结构,其结构如图2所示。
采用注意力机制的神经机器翻译的工作流程下图3所示。Attention 机制核心思想是建立输出序列和encoder 历史状态之间的直接连接,在翻译时将“注意力”集中在与当前输出相关性强的输入上。在解码时刻t,解码器分别产生该时刻的目标语言隐式状态和目标语言单词。t时刻目标语言隐式状态 s(t)由t-1时刻目标语言隐式状态s(t-1) ,t-1时刻解码器所生成的目标语言单词y(t-1) 和t时刻上下文向量c(t) 所决定:
st=f(st-1,yt-1,ct)。
其中,f是一个非线性方程。根据源语言隐式状态和注意力系统模型所产生的权重加权,可以得到目标状态s(t)之 后,模型通過softmax函数估计t时刻目标语言单词的概率分布:
P(yt|y 从而,将概率最大的结果作为注意力机制下的翻译结果如图2、3。 4 同声传译系统实现 4.1 同声传译系统界面设计 如图4所示,本项目设计的同声传译界面如图4所示,识别和翻译结果显示都使用richText控件进行显示,录音按钮开关使用micControl控件,中英文图标显示使用pictureBox控件,从而完成了同声传译系统的界面设计。 4.2 同声传译系统功能实现 该系统设计的初期版本,是实现中英文之间的同步翻译,功能模块主要有两部分组成:录音功能、语音识别显示功能和机器翻译显示功能。语音识别结果显示在控件richText_input框中,机器翻译结果显示在控件richText_output框中。 录音功能界面,采用自定义控件;音量反馈条亦采用自定义控件;左键点击可返回主界面,并终止录音与视频通信;右键点击可以弹出右键菜单,包含退出选项,点击退出选项可退出程序。 语音识别显示功能,采用标准winform窗体richText控件,将录制的音频进行vad静音消除之后传送至语音识别服务器159.226.21.71进行处理,然后将识别结果发送回来,发送回来的信息包含两部分内容,确定信息和不确定信息,中间使用“ /”进行隔开,然后将该部分的反馈信息实时显示在richText_input框中,确定部分用黑色字体显示,不确定部分使用红色字体显示,这样既可实时显示语音识别结果的显示。 机器翻译显示功能,采用标准winform窗体richText控件,此部分是利用语音识别的识别结果信息作为输入,然后传送至翻译服务器159.226.21.71进行翻译,并将翻译结果实时显示在richText_output框中,这样实现了实时翻译显示的功能。 5 结语 本论文主要介绍了同声传译的发展概述,目的意义,研究方法和具体实现,实现了一个基于C#开发的同声传译系统,能够实现同声传译的功能。从实现效果上看,语音识别部分准确率以及实时性效果很好,但是实时翻译部分效果还有待完善。 参考文献 [1] 李虎生,刘加,刘润生.语音识别说话人自适应研究现状及发展趋势[J].电子学报,2003,31(1):33-36. [2]何湘智.语音识别的研究与发展[J].计算机与现代化,2002,(3):3-6. [3]陈方,高升.语音识别技术及发展[J].电信科学,1996,(10):54-57. [4]熊德意,王星,张民.一种调序模型建立方法、装置及翻译方法,CN 104572636 A[P].2015. [5]刘洋.神经机器翻译前沿进展[J].计算机研究与发展,2017,54(6):1144-1149.
- 刍议小学一年级的德育教育
- 例谈初中道德与法治课堂实践化教学策略
- 时事政治在高中政治教学中的应用研究
- 培育高尚师德,提升教师人文素养
- 试论现代教育技术与小学品德与社会教学的融合实践
- 小学数学课堂中的德育思考
- 新形势下中等职业学校德育工作特点及对策
- 初中学生道德与法治互动教学模式分析
- 初中德与法教学培养法治意识研究
- 浅析中学美术课堂学习方法
- 初中英语课堂效率提升的方法研究
- 浅谈初中生物趣味性课堂的构建
- 提高初中历史课堂效率的尝试
- 小学信息技术翻转课堂教学模式设计
- 抓住课堂生成 点燃精彩瞬间
- 浅谈小学数学课堂教学质疑能力的培养
- 在智慧课堂环境下开展实验教学的初步探讨
- 谈中学语文课堂提问技巧在课堂中的运用
- 浅谈英语课堂教学艺术
- 构建小学数学有效课堂的点滴思考
- 多媒体技术让聋校数学课堂更精彩
- 初中九年级语文微课教学的设计与实现探索
- 有效运用微课,构建精彩小学音乐课堂
- 浅谈小学数学情智课堂实践探究的重要性
- 优化课堂教学 培养创新意识
- rearose
- rearousal
- rearousals
- re-arouse
- rearouse
- rearoused
- rearouses
- rearousing
- rearrange
- rearrangeable
- rearranged
- rearrangement
- rearrangements
- rearrangement's
- rearranges
- rearranging
- re-arrest
- rearrested
- rearresting
- rearrests
- rears
- rears'
- rearticulate
- rearticulated
- rearticulates
- 美疢
- 美白
- 美白霜
- 美益求美
- 美益求美已精求精
- 美盛
- 美盛的业绩
- 美盛的功业
- 美盛的功勋
- 美盛的化育
- 美盛的样子
- 美盛的筵席
- 美盛的食品
- 美目
- 美目流波
- 美目流盼
- 美目清兮
- 美目顾盼
- 美盲
- 美眉
- 美眷
- 美睡
- 美睫
- 美石
- 美石,次等的玉