胡松 王艳
摘 要:以彭宣维的经验语法隐喻模型和德维姆的逻辑隐喻模型为基础,构建了可以应用于教学实践的概念语法隐喻框架。在此基础上,利用该框架构建了成人语篇教学法,并将教学法应用于课堂实践。此外,通过实证研究,评估了基于语法隐喻的教学法。结果显示,基于语法隐喻的教学法可以在短期内提高学生识别和生成语法隐喻的能力,但对学生理解语法隐喻的能力的影响不够明显。
关键词:概念语法隐喻;系统功能语言学;成人话语;教学法
中图分类号:G4 文献标识码:A doi:10.19311/j.cnki.1672-3198.2019.35.105
0 引言
隐喻表达式是所有成人语篇的特征。理解隐喻表达式通常需要读者付出极大的认知努力,这也是为什么学生在学习隐喻表达式时会遇到诸多困难。笔者在高级英语课堂上尝试过多种成人语篇教学法,包括结构分析法和翻译法,但都没有达到良好的效果。幸运的是韩礼德的语法隐喻理论为解决这一难题提供了可靠途径。但鲜有研究探讨基于语法隐喻理论的教学法的实际效果,因此本研究旨在探索这一问题。
1 研究方法
1.1 参与者
本研究的55名参与者都是广东海洋大学寸金学院大三英语专业学生,所有55名学生都选修了笔者的高级英语课程。但参加了前后两项测试的学生只有50名。因此,只有这部分学生的前测和后测成绩会作为本研究的数据。
1.2 前测和后测
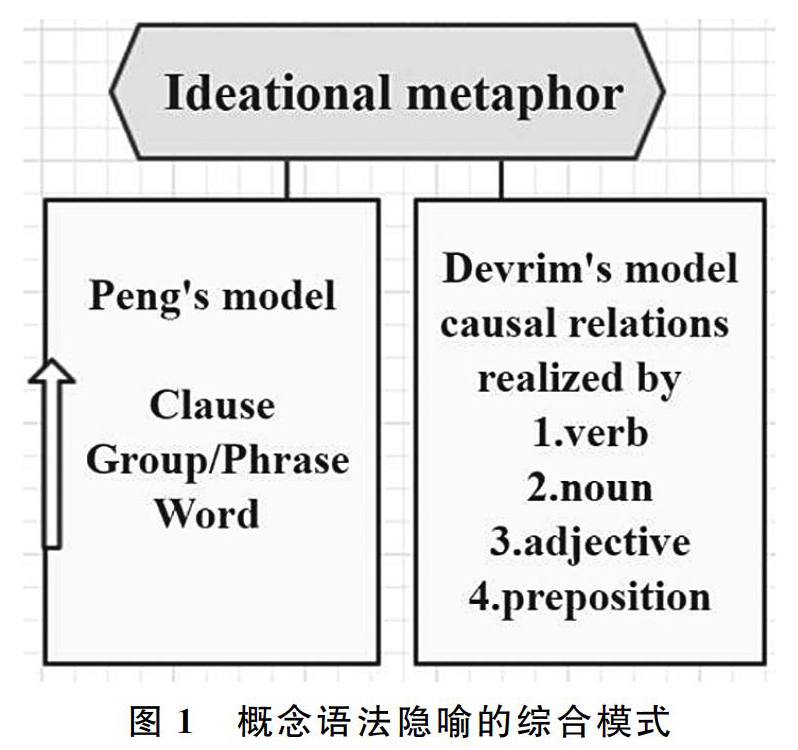
语法隐喻主要有分层模式和语义模式。尽管两种模式都可以用于构建成人语篇教学法,但它们都有各自的缺陷。因此,在对比分析多种语法隐喻模式后,筆者将尝试在彭宣维的经验语法隐喻模型和德维姆的逻辑隐喻模型的基础上,构建一种适用于教学的混合模式。
彭宣维的经验语法隐喻模型是基于他对词汇语法级阶的观察。彭的模型关注的是概念语法隐喻的经验侧面,包括语法隐喻在所有级阶上可能涵盖到的经验现象,包括词隐喻、词组/短语隐喻、小句隐喻,这些典型的语法隐喻构成了多级合取系统。 德维姆的逻辑隐喻模型构建于语法隐喻的分层模式和语义模式。该模式将逻辑隐喻分为四种主要类型:(1)原因识解为动词,如“cause”,“lead to”;(2).原因识解为名词,如 “cause”,“impact”;(3)原因识解为形容词,如 “causal”,“resultant”;(4)原因识解为介词,如“due to”或“through”。图1简要勾勒了概念语法隐喻的综合模式。
该模式在确立之后,将用于前测和后测的设计。由于本研究主要在于检测基于语法隐喻的教学法是否可以提高学生的语法隐喻能力,所以前测和后测中会包含多项选择题、英汉翻译、汉英翻译,分别用于检测学生在接触基于语法隐喻教学模式前后的语法隐喻识别、理解、生成能力。此外,为了确保前测和后测试题的难度相当,笔者控制了多项可能影响试题难度的因素,包括句长,句型,词汇复杂度,语法隐喻的数量等等。
1.3 概念语法隐喻模型的课堂应用和数据分析
概念语法隐喻模型的课堂应用分为三步:介绍概念语法隐喻理论、实际应用于课堂讲授、课后实践和练习。笔者4月13号在课堂上进行了前测,随后引入了概念语法隐喻模型,并教授了学生如何使用该模型来识别、理解和生成语法隐喻。这一过程持续到5月9号,随后笔者进行了后测。
2 数据分析和讨论
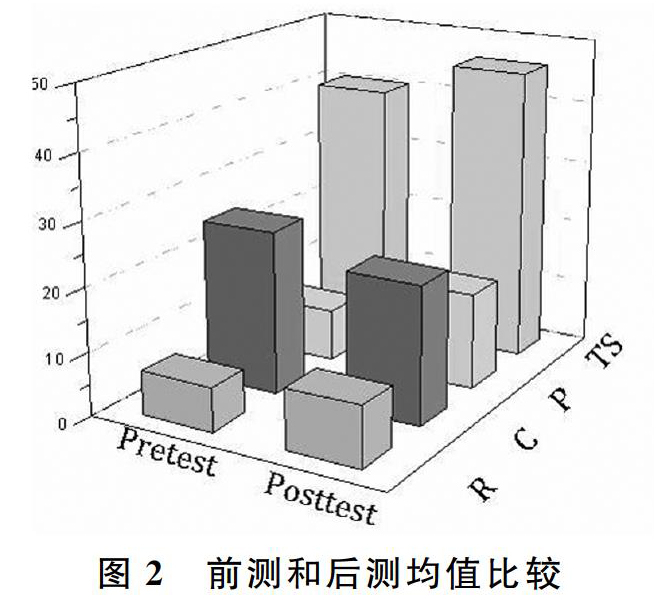
笔者首先比较了前测和后测的均值,结果如图2所示。
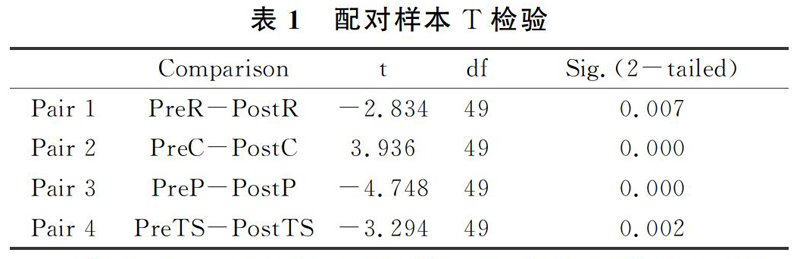
需要注意的是,Y轴上的大写字母R,C,P分别代表了语法隐喻识别、语法隐喻理解(英译汉)和语法隐喻生成(汉译英),Y轴上的TS代表总分。因此,从上图可见,学生在后测中的总分、语法隐喻识别部分的得分和汉译英的得分要高于前测,然而学生在英译汉部分的得分均值要低于前测。为了确定前测和后测的均值是否有统计学意义上的显著性,笔者进行了配对样本T检验。结果如表1所示。
从上表1可见,第二组、第三组和第四组的P值均小于0.05,第一组的P值大于0.05。这表明总分和汉译英部分的后测均分大于前测具有统计学上的显著性,而英译汉部分的后测均值小于前测也同样具有统计学意义上的显著性。此外,在识别语法隐喻方面,学生前测表现优于后测,并不具有统计学意义上的显著性。
为了进一步探索学生在前后测中表现的差异性,笔者对前后测中每道题的得分均值进行了比较。结果如图3所示。
上面的三张三维柱形图分别代表了三种题项。第一张图表明,第一题、第二题和第三题的后测得分均值均大于前测,这表明在回答关于识别语法隐喻方面的题型时,学生的后测表现要好于前测。第二张图显示,第七题的后测得分均值明显大于前测,第四题的均值稍大于前测。而第五题和第六题的后测均值明显小于前测。第二张图显现的差异性表明,学生在回答英译汉时,后测表现未必好于前测。第三张图表明,学生在回答汉译英时,后测表现明显优于前测。
为了确定上述差异是否具有统计学意义上的显著性,笔者进行了配对T测验。结果如表2所示。
上表2,第三组和第四组的P值大于0.05,分别为0.554和0.773,其他组的P值都低于0.05。这表明第三题和第四题的后测均值大于前测不具有统计学意义上的显著性,而第一、二、七、八、九、十题的后测均值大于前测具有显著意义。同时上表也表明,第六、七题的后测均值小于前测具有显著意义。
上述结果进一步佐证了前一部分的发现。具体来说,结果表明了,学生识别语法隐喻的能力在后测中有所提升,然而水平的提升并不具有统计学意义上的显著性。但这并不能否认基于语法隐喻理论的教学法对提升学生识别语法隐喻的能力所带来的积极影响,因为后测中,两道关于语法隐喻识别的题目的得分均值显著性大于前测。此外,从表中还可看到,基于语法隐喻理论的教学法并不能在短期内给学生理解语法隐喻带来积极影响,这点值得进一步探索。但是,不可否认,基于语法隐喻理论的教学法可以有效帮助学生提升语法隐喻的生成能力,因为在汉译英题型方面,学生的后测得分均值明显大于前测。
3 结论
本研究以彭宣维的经验语法隐喻模型和德维姆的逻辑隐喻模型为基础,构建了适用于语法隐喻教学的概念语法隐喻模式。在此基础上,利用该框架构建了成人语篇教学法,并将教学法应用于课堂实践。实证研究表明基于语法隐喻的教学法可以在短期内提升学生识别和生成语法隐喻的能力,但对学生理解语法隐喻的能力的影响尚不明确,因为学生识别语法隐喻的能力会受到多种因素的影响,比如学生词汇量和识别语法隐喻的能力等等。
参考文献
[1]Halldiay,MAK.Introduction to Functional Grammar,2nd edition,London:Arnold,1994.
[2]Martin,JR.English text:System and structure.Amsterdam:John Benjamins,1992.
[3]Halliday,MAK,and CMIM,Matthiessen.Construing experience through meaning:A language-based approach to cognition.London.Cassell,1999.
[4]Devrim,DY.GM what do we mean.Functional Linguistics,2015.
[5]彭宣维.词汇语法级阶下的经验语法隐喻新解[J].语言学研究,2016,(6).
- 小学数学教学中学生合作能力的培养
- 巧用微课,打造高效数学课堂
- 优化数学课堂练习设计的探索和实践
- 论“核心素养”在小学数学教学中的影响
- 在小学数学教学中培养学生模型思想的探讨
- 小学数学课堂有效课堂学习方式初探
- 浅谈小学数学教学与学生生活实际的结合
- 小学数学教学中对于学生自主学习能力的培养探微
- 口算:数学教学的基石
- 浅谈新背景下小学数学生活化教学策略
- 浅析小学数学中交互式电子白板的有效应用
- 浅析中学数学课堂有效教学策略
- “先学”在农村初中数学课堂实施的几点思考
- 初中数学自主探究学习的有效性实施策略分析
- 浅谈初中数学有效课堂提问技巧的策略
- 关于初中数学教学中构建情境教学的有效措施分析
- 让数学课外作业不再成为一种负担
- 变式教学在初中数学教学中的应用
- 中学数学教学的改革与人才培养创新研究
- 情境教学法在初中函数教学中的应用研究
- 数学教学中使用微课应处理好两个关系
- 如何在数学课堂教学中确立“过程教学”观
- 刍议数形结合方法在高中数学教学中的应用
- 新课改下高中数学教学存在的问题及对策分析
- 小组合作学习在高中数学教学中的应用探析
- antiquatedness
- antiquatednesses
- antiquatedness's
- antique
- antiqued
- antiquehood
- antiquely
- antiqueness
- antiquenesses
- antiquer
- antiquers
- antiques
- antiquing
- antiquitarian
- antiquites
- antiquities
- antiquity
- antirabies
- antirabieses
- antiracial
- antiracially
- antiracing
- anti-racing
- anti-racism
- antiracisms
- 用欠账的方式购买
- 用次等或下等衣料做的衣物
- 用欺诈手段或强力夺取财物、权利
- 用欺诈手段招致
- 用欺诈手段杀死
- 用欺诈手段牟取财利
- 用欺诈的手段骗取
- 用欺骗引诱等手段迷惑人,搞乱人的思想
- 用欺骗手段作掩护,暗地里采取行动
- 用欺骗手段取得
- 用欺骗手段取得世人赞誉的好名声
- 用欺骗手段获得供词
- 用欺骗的手段使人相信虚假的事物
- 用欺骗的手段使异性跟自己发生性行为
- 用欺骗的手段在暗地里活动
- 用欺骗的手法做违法乱纪的事
- 用歌诗的形式写景抒情
- 用正直之臣辅佐君王
- 用正直的话向皇帝进谏
- 用武
- 用武之地
- 用武力使服从
- 用武力压服与用计谋控制对方
- 用武力反抗
- 用武力取得对方的土地或领土