顾金池
摘要:本文首先通過文献研究和在线结合离线的调查,梳理出影响大学生大学期间成绩的所有可能因素,并在可操作、有意义的前提下,采集了396名大学生的相关数据,然后探讨学生成绩表现和各影响因素之间的相关关系,并利用多元线性回归和决策树模型,以及拓展的随机森林集成方法构建学生成绩的分析和预测模型,最后对几种方法的结果做横向比较,并提出不足和改进之处。
关键词:多元线性回归;学生成绩;决策树;随机森林;预测
中图分类号:O17 文献标识码:A
0 引言
随着我国经济的发展,教育受到社会越来越多的关注。与此同时,各式各样的教育机构如雨后春笋般涌现出来。本文的研究目标是通过市场调查了解大学生成绩的可能影响因素并收集相关数据,包括学习时间、父母亲职业、逃课次数等因素,并建立多元回归分析模型进行数据分析和预测,最后对几种模型的分析和预测结果进行对比,根据结果提出相关建议。
1 相关研究
Paulo Cortez[1]等人使用决策树等分类算法并使用学生成绩属性对学生的数学和葡萄牙语两门课程的表现进行预测,结果表明只要已知第一或者第二学期的成绩,就有可能实现较高的预测准确性。刘云芬[2]使用多元回归模型对大学生期末高等数学成绩影响因素进行分析,发现学生高考数学成绩和平时成绩是关键影响因素。王羽[3]通过调查问卷对大学生逃课和上课使用手机以及恋爱情况是对学习成绩和学习效果产生影响的因素。吴唐燕[4]收集女大学生的学生因素、家庭因素等42个指标,发现学生因素、学校因素和女大学生的成绩成显著关系,而家庭因素对其学业成绩影响不是很大.Yadav[5]等人使用学生的出勤率、班级考试成绩、研讨班和作业分数、实验室工作来预测学期末学生的表现。
2 研究方法和数据
2.1 数据的采集
本文主要通过文献研究和社会调查的方法确定可能的影响因素并进行数据采集,最终采集到了396名大学生的20个属性,分别为性别、年龄、父母情况等属性,其中G3属性为该大学生大学期间的成绩水平情况。
3 数据预处理和模型的建立
3.1 数据解释与预处理
本文共收集到396名大学生的20个属性值,数据来源于四川省四所高校,主要收集方式是问卷星以及现场的问卷调查。
3.2 数据的预处理
本文中对数据的预处理包括以下几个部分:
第一,数据缺失以热卡填补法填补,即在其他所有数据中找到与缺失数据最为相似的对象,然后用该对象的值进行填补。
第二,含有数据异常值的对象直接删除,本文主要是采用经验判断法判断数据的异常情况,如年龄属性为负值或者小于12等等,因为调查时各属性都给了选择范围,所以异常值极少,也很容易处理。
第三,在多元线性回归之后,对非量化属性数据进行量化处理,用于后面决策树和随机森林模型的建立。
3.3 多元线性回归模型
为了避免量化的不可解释性以及减小模型误差,本模型数据选取了原始数据中的量化数据,共计10个属性列。
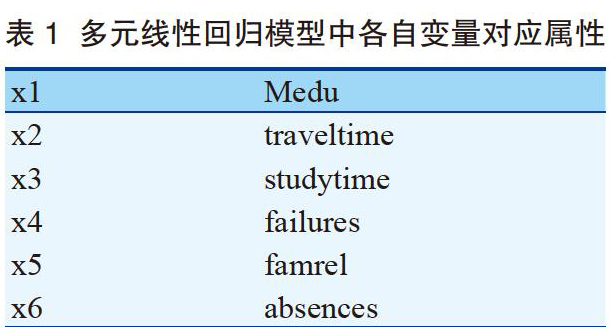
本文选择以属性Medu(母亲教育水平)、traveltime(旅行时间)、studytime(学习时间)、failures(失败次数)、famrel(家庭关系)以及absences(课堂缺席情况)作为模型中的自变量,G3属性为模型的因变量。将所有数据带入多元线性回归模型可以得出模型结果:
y=3.77+0.96x1+0.003x2+1.28x3-0.25x4+0.18x5-0.27x6(8)
该模型中各变量对应的属性,见表1。
以上述方程预测学生的成绩并与真实成绩做对比,我们发现预测精度已经相对较高,具有很好的现实意义。
该多元线性回归方程的R2=0.884,说明有88.4%的G3属性数据可以被上述方程很好地解释,其中当其他变量不变时,母亲的教育水平每增加(减少)一个单位,学生的大学成绩就增加(减少)0.96个单位,其他影响因素以此类推,当所有影响因素的值均为零时,该学生的成绩为3.77,对应等级为不及格,而且远远不及格。
3.4 决策树与随机森林模型
本文使用的决策树模型将所有统计的属性数据都加入其中,带入决策树模型之前将所有预处理之后的数据进行训练集一测试集的划分,本文将训练集数据:测试集数据=7:3的比例划分,然后对划分比例进行验证,得到的比例结果是训练集:全部数据=0.6987:1,在误差允许的范围内,可以进行模型构建。
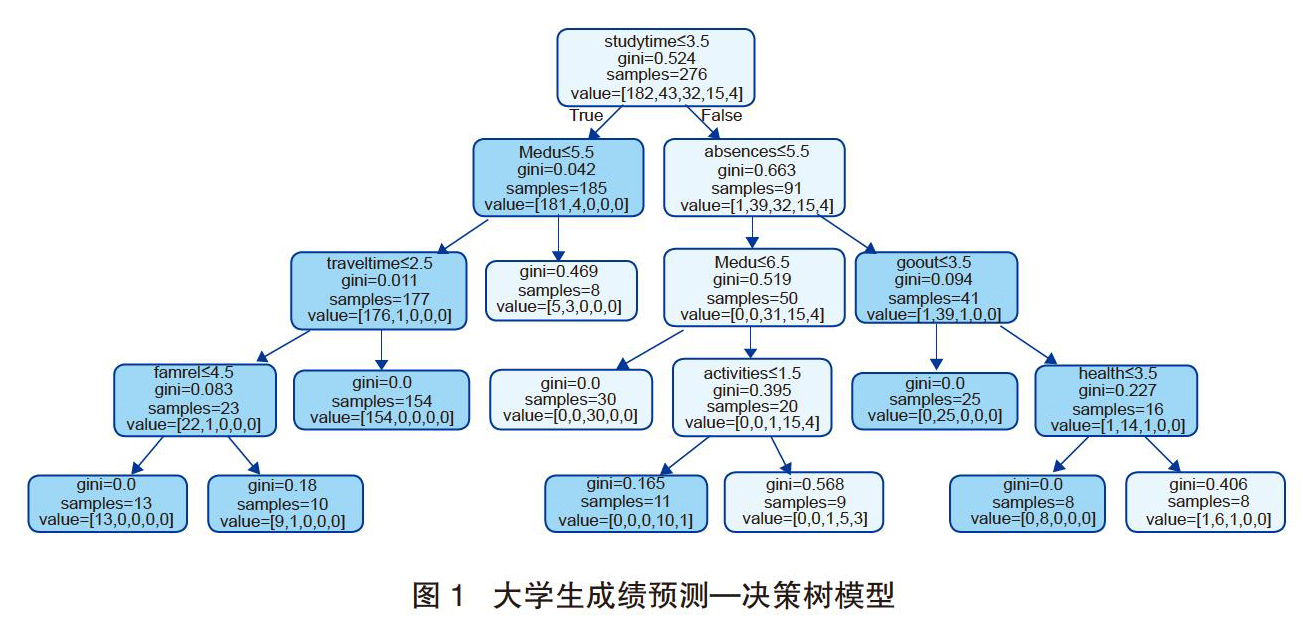
本文的决策树模型结构(见图1),可以看出,该模型中共有根节点一个,属性为studytime,包含的样本数量为276个,其中大学成绩不及格的有182个同学,及格有43个同学,成绩为中的有32个同学,成绩为良的有15个同学,成绩为优的有4个同学。叶节点共8个,内部节点有8个。
利用该决策树模型对大学生成绩预测的精度只有81%左右,效果并不是很理想,本文继续使用随机森林模型看能否实现对决策树模型的优化和补充,随机森林模型相较于单个决策树模型有着更好的泛化能力和容错能力,是决策树模型很好的对比和补充模型。
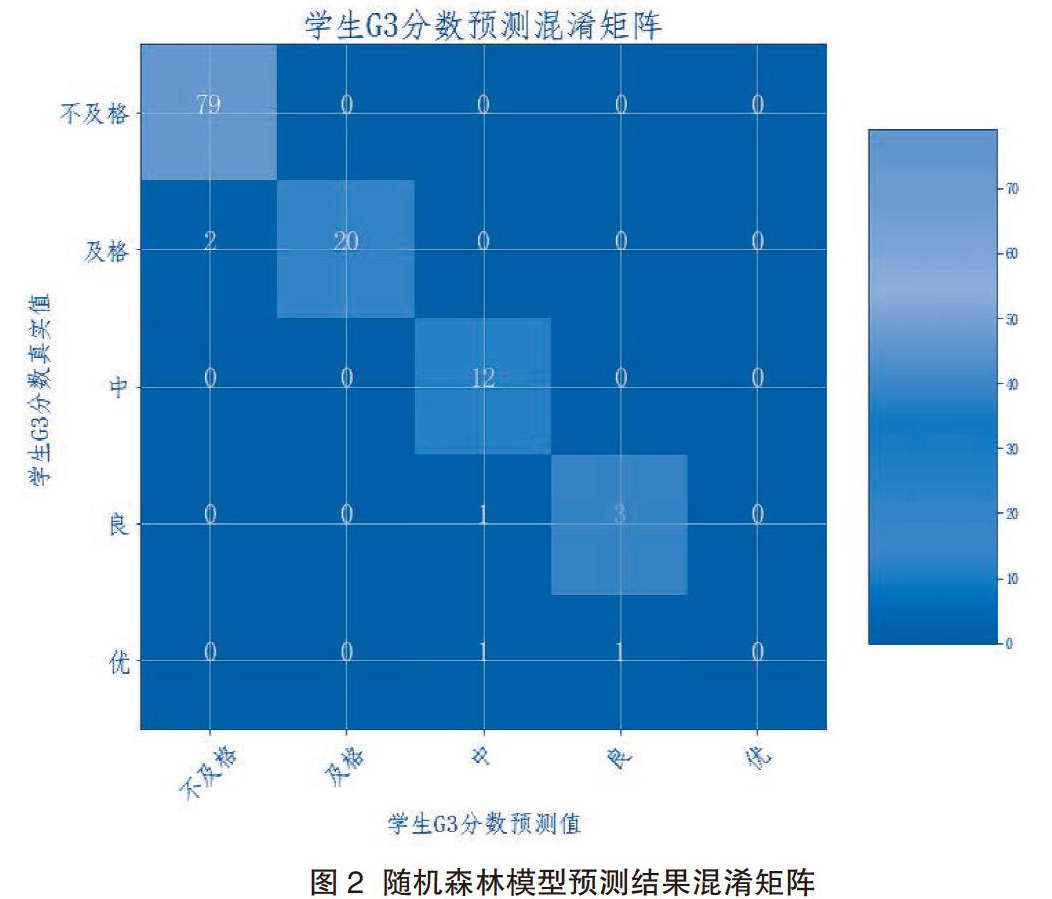
在随机森林模型建立之前,对数据的预处理和量化都和上述一样,在此不再赘述。本文使用的随机森林模型共包含决策树100颗,对单个决策树的节点和最大深度的初始化都为空矩阵,即无要求。在模型建立过程中,该模型的单个决策树的平均节点数量为57,平均深度为8,最终模型在测试集中的预测混淆矩阵,见图2。
从混淆矩阵可以看出,随机森林模型预测的准确度相较于决策树模型大大提高,在测试集的119个样本中,在大学成绩为不及格以及中的91个样本中全部正确预测,在大学成绩为及格的22个样本中预测正确20个,在大学成绩为良的4个样本中预测正确3个,在大学成绩为优的2个样本中预测正确。个。最后总的预测正确率达到了95.798%,有了很大提升。
4 结束语
本文鉴于目前对大学生成绩影响因素探究和预测较为杂乱,定性研究多的现状,从多元线性回归模型入手,结合决策树模型以及随机森林模型全面考察了大学成绩影响因素以及精准预测,得到了很有现实指导意义的建议和结果。研究结果显示:一是在大学成绩的各项影响因素中,失败次数和课堂缺席次数均为负影响,而母亲教育水平、旅行时间、学习时间和家庭关系都为正影响,且学习时间影响程度最大,母亲教育水平次之。这很好地反映了我国家庭教育中大多数以母亲为主导的现状,也建议当代大学生应该在保证学习时间的基础上适度旅行,少缺课旷课,同时父母应该为孩子创造一个和谐健康的家庭环境;二是对于大学成绩预测问题,本文验证了随机森林模型比决策树模型有着更好的预测能力,可以达到较高的预测精度。
参考文献:
[1]Cortez P,Silva A.Using data miningto predict secondary school studentperformance[C].Proceedings of 5thAnnualFuture Business TechnologyConference,Proto,2008:5-12.
[2]刘云芬.基于多元回归模型的大学生期末数学成绩影响因素分析[J].湖北师范大学学报,2018(4):103-106.
[3]王羽.大学生学习成绩影响因素及对策研究[J].当代教育实践与教学研究,2018(10):67-68.
[4]吴唐燕.学生、学校以及家庭因素对女大学生学业成绩的影响[J].前沿,2015(11):115-117.
[5]Yadav S K,Bharadwaj B,Pal S.Datamining applications:a comparative studyfor predicting students' performance[J].International Journal of InnovativeTechnology&Creative Engineering,2011,1(12):13-19.
- 工农结合提升大学生实践能力、创新能力的研究与实践
- 基于卓越工程师培养的车辆工程专业企业培养方案研究
- 国际化、大工程背景下机械类卓越工程师人才培养
- 城市轨道交通车辆维修工艺与设备课程的优化与创新
- 工科类课程的微课教学设计制作与实践
- 隧道工程教学体系改革方法探索
- “变被动为主动”机械类工程图学课程作业评价模式改革与应用实践
- 智能手机普及化时代高职院校思政课教学创新研究
- 依法治校环境下高校思政课教师队伍制度化建设研究
- 基于学生干部教育管理的高校辅导员工作案例分析
- 中国优秀传统文化融入大学生思想教育研究
- 以高校公寓文化建设推进社会主义核心价值观培育的探索
- 关于“四个全面”战略布局融入“概论”课教学的几点思考
- 基于专业人才培养方向的高职机械行业英语教学改革探索与实践
- 美国发展性教育的起源、范畴以及成果
- STEM对我国科学教育专业人才培养的启示
- 环境监测实验教学改革的研究和探索
- 公安专业学生计算思维能力培养对策初探
- 依托实验教学示范中心培育机电类创新型人才的实践
- 高校大学生创新型人才培养模式初探
- 我国高等教育创新型人才培养的影响因素及改革策略
- 大学生校外实践基地建设实践与体会
- 地方院校历史学专业考察探析
- “互联网+”背景下的教学方式改革
- 学生对翻转课堂综合评价的调查研究
- areacode
- area-codes
- area codes
- areafranchise
- area franchise
- areal
- areally
- areas
- a reformed character
- arena
- arenas
- arena's
- arenosity
- arenot
- aren't
- a return to sth
- argon
- argons
- argot
- argotic
- argots
- arguable
- arguably
- argue
- argued
- 盗匪的资财
- 盗匪盘踞的地方
- 盗匪造成的祸患
- 盗匪集团
- 盗匿
- 盗卖
- 盗印
- 盗发
- 盗取
- 盗取他人的智慧
- 盗取名誉
- 盗取地位或职位
- 盗取荣禄
- 盗取虚名
- 盗名
- 盗名暗世
- 盗名欺世
- 盗名窃誉
- 盗听
- 盗啼
- 盗国
- 盗塞
- 盗墓
- 盗声
- 盗夸