摘 要 文章就基于用户行为的产品相似性推荐模型及用户、产品标签化推荐模型进行研究,通过用户在观影中的点播行为,从聚类模型、熵值法打分模型两个角度解构这一行为,对用户行为和产品的业务标签进行抽取,从而形成预测模型,为用户提供更加个性化的点播体验。
关键词 用户行为;产品相似性;推荐模型
中图分类号 G2 文献标识码 A 文章编号 1674-6708(2018)216-0164-02
1 基于用戶行为的产品相似性推荐模型
1.1 推荐模型的定义
由于互联网电视以网络为平台,因此各类影视资源非常集中而丰富,但是受到互联网电视界面的限制,影视资源不可能一一罗列,因此用户在实际使用中并不能根据自主意识达到完全准确搜索的程度,为避免用户的观影体验受到影响,影视产品的推荐必须符合用户的个性化喜好,从而帮助用户精准搜索,提高观影的质量。
1.2 推荐模型的目标
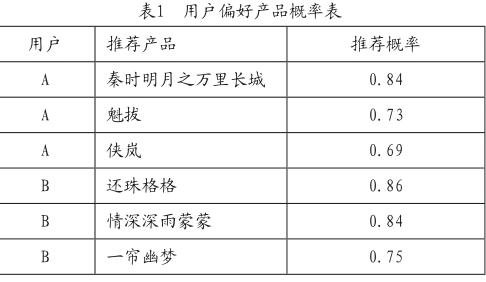
推荐模型着重对用户的影视点播行为进行深层次的分析,然后对窗口期的观影喜好进行预测,着重以用户的点击行为为预测的依据,然后计算出产品的推荐概率,将排序靠前的产品作为用户偏好的推荐产品(如表1所示)[1]。
1.3 推荐模型的思路
一般采用协同过滤模型为用户推荐产品,但这种模型只能为用户提供历史观看的影视产品,而对于用户而言,更高质量的推荐必须建立在新产品的基础上,因此在互联网电视中不能应用协同过滤这种推荐模型,而应该着重对用户的点播行为进行分析,从而全面掌握用户的观影喜好,从而提供相似的产品,使用户获得更优质的观影体验。
1.4 推荐模型的方法
1)模型架构。为了使产品相似性模型的数据更加可靠,可以通过以下方法对模型数据进行划分:首先将用户的观影时间划分为不同的模块。例如确定模型构建的数据长度为用户6~9月的观影时间,因此将6~7月作为用户点播行为的观察期,将8月作为用户点播行为的预测期,将9月作为用户点播行为的预测结果评估期;然后利用RLM模型,对用户的观影喜好进行反映[2]。
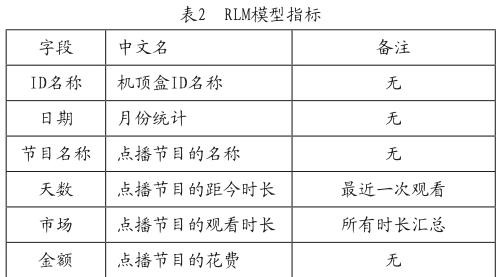
2)数据处理。数据处理主要包括两个方面,分别是RLM模型和产品相似性模型。就RLM模型来看,主要通过以下指标对数据进行处理(如表2所示)。
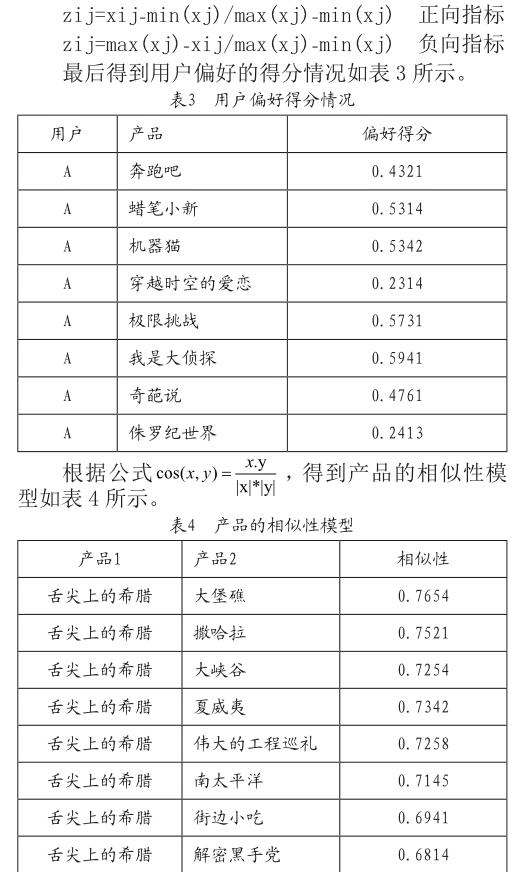
为实现标准化分析,利用以下公式对数据进行处理:
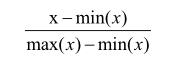
就产品相似性模型来看,主要将影视产品的演员、导演、出品时期、分类名称、语种类型、清晰参数、时长等方面作为产品相似性特征,并且用下列公式对数据进行标准化处理:
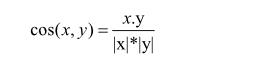
3)模型计算。本次模型计算主要采用熵值法打分模型,这种模型的主要依据使信息的无序度,而信息的实用价值与无序度之间呈反比关系,即无序度越高,信息的价值越低,而无序度越低,则信息的价值就越高。例如在N个样本中选择M个数据指标,然后归一化处理所有的指标,以异质同化、绝对变相对作为处理的原则,然后得到一批正向指标和负向指标,其中正向指标越高,模型计算的准确度越高,而负向指标越低,则模型计算的准确度越高。在对正向指标和负向指标进行标准化处理时,需要应用以下公式:
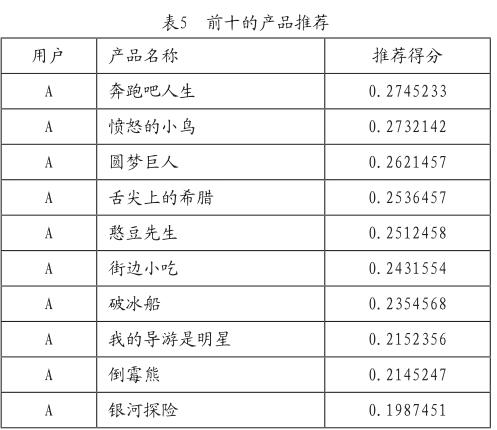
4)实际应用。通过对用户偏好的分析和产品相似性分析,结合用户点播行为的特征,可以得到以下排名前10的推荐产品(如表5所示)。
2 基于用户、产品标签化的推荐模型
2.1 推荐模型的定义
对用户和产品的标签化处理能够使用户点播行为的特征得到更加直观的反映,从而加深对用户的了解,为用户提供更加贴切的观影体验。例如对用户或者产品的图像进行分析,然后针对标签对用户进行针对性的营销。在对用户、产品标签化的推荐模型进行构建时,要着重对用户行为进行分析,并对行为特征进行标签化处理。
2.2 推荐模型的方法
1)模型架构。在对用户、产品便签化的推荐模型进行架构时,要从不同维度对用户的行为进行分析,然后形成个性化的标签。在模型中要构建正样本和负样本两类,正样本为用户的实际点播行为,而负样本为用户的无点播行为[3]。
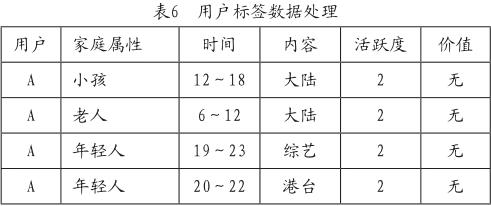
2)数据处理。就用户标签来看,主要通过聚类模型、打分模型,对标签数据进行处理(如表6所示)。
参考文献
[1]张薇.基于用户自生成内容的社会化商务价值共创研究[D].南昌:南昌大学,2016.
[2]侯磊.在线社会系统中用户行为的实证分析与机制建模研究[D].上海:上海理工大学,2014.
[3]赵凌云.面向服务的消费者行为分析及推荐模型研究[D].济南:山东师范大学,2014.
- 浅谈小学数学教学中逻辑思维能力的培养
- 在小学数学教学中渗透数学思想方法
- 教学反思在初中地理教学中的应用探讨
- 谈网络资源下培养幼儿的良好习惯
- 初中数学教学中学生思维能力的培养探讨
- 浅谈在英语教学中学生创新能力的培养
- 在小学古诗教学中培养学生的形象思维能力
- 浅析如何进行高中英语口语教学
- 生理学教学中科研创新能力的培养探索
- 试谈如何巧妙利用生活情境开展小学数学教学
- 浅谈中职计算机教学中培养学生创新能力的方法
- 做好初中与小学数学教学衔接的对策
- 高中历史教学中学生学习兴趣的培养
- 高中历史教学中人文精神的培养
- 初中数学教学中培养学生主动提问能力的有效途径
- 民间美术资源与小学美术学科教学的整合
- 巧用信息化技术优化中职语文教学
- 浅析高中信息技术课程教学问题情境的创设方法
- 大数据时代背景下语文教学与信息技术整合问题几点思考
- 多媒体在电焊工一体化教学中的运用探讨
- 浅谈在初中英语词汇教学中的兴趣利用
- 多媒体背景下小学语文教学探究
- 中职语文信息化教学实施策略探究
- 初中数学分组教学中的点滴体会
- 浅谈多元智能理论对中职语文教学的启示
- absent-minded
- absent minded
- absentminded
- absent-mindedly
- absent-mindedness
- absent-mindednesses
- absentness
- absentnesses
- absents
- abses
- absolute
- absoluteadvantage
- absolute advantage
- absoluteauction
- absolute auction
- absolutely
- absolute majorities
- absolute majority
- absoluteness
- absolutenesses
- absoluter
- absolutes
- absolutest
- absolute zero
- absolute zeroes
- 违犯法律,破坏纪律
- 违犯法纪
- 违犯法规
- 违犯礼法
- 违犯禁令
- 违犯禁令律令
- 违犯禁忌
- 违犯规则、规定
- 违犯,冒犯
- 违玩
- 违理
- 违盟
- 违矫
- 违碍
- 违礼
- 违礼,越礼
- 违禁
- 违禁夜行
- 违禁强开城门
- 违禁武器
- 违禁走私
- 违离
- 违科
- 违程
- 违章