
摘要:在微博社交网络中,微博用户每天针对热门新闻、事件等生成众多微博内容,导致用户在大量内容中找到自己真正感兴趣的信息非常困难。因此,系统向用户推荐其感兴趣的微博,是改善用户体验的重要途径。提出一种新的模型因子分解机FM,以及综合考虑用户兴趣与信任因素的预测方法ITFM,以提高个性化微博推荐质量。通过在真实的数据集上进行模拟实验,结果表明,所提出的微博推荐方法在一定程度上提高了微博推荐准确度。ITFM方法能够有效解决信息过载问题,对改善用户体验具有较好的理论和实际意义。
关键词:微博推荐;信任;ITFM
DOIDOI:10.11907/rjdk.181608
中图分类号:TP301
文献标识码:A 文章编号文章编号:1672-7800(2018)008-0049-04
英文摘要Abstract:Microblog users generate numerous microblog contents based on breaking news and latest events every day.However,it is difficult to find information of interest from these contents.Recommending interesting microblogs from the Microblog system is an important way to improve user experience.In this light,we build a model called ITFM,which combines factorization machines together with user interests and trust factors to improve the quality of personalized microblogging recommendations.Through simulations on real data sets,results show that the proposed Microblog recommendation approach improves the accuracy to some extent.ITFM can effectively deal with the information overload problem,and our work has better theoretical and practical significance for improving user experience.
英文关键词Key Words:Microblog recommendation;trust;ITFM
0 引言
第41次中国互联网发展状况统计报告显示,截至2017年12月,中国网民规模已达7.72亿,微博用户规模为3.16亿。数据表明,社交网络已成为互联网用户生活中不可缺少的一部分,微博如Twitter、新浪微博等,已成为人们获取和实时分享信息的重要途径。微博是一个基于用户关系的信息分享、传播及获取平台,以140字左右的文字记录,实现即时分享。由于微博数量众多,容易产生信息过载,用户需要花费大量时间及精力去寻找自己感兴趣的微博。从海量微博中挖掘出用户感兴趣的微博内容并进行个性化推荐,已成为当今的研究热点。
常见的微博推荐有好友推荐[1]、散列标签推荐[2]、热门话题推荐[3]、新闻推荐[4]等。推荐算法中比较成功的是协同过滤推荐算法[5],该算法侧重研究与用户偏好最相似的用戶群体对目标用户的影响,但对目标用户的个体兴趣挖掘不够充分。Kim 等[6]提出基于PLSI算法[7]的微博用户受关注者影响推荐算法;Duan等[8]利用learning to rank框架实现微博推荐;Chen等 [9]融合用户微博主题与待推荐微博内容特征,向用户提供个性化微博推荐;Shen等[10]提出一种基于用户社交关系的推荐方法,利用用户间的关系图进行计算与推荐;Lo 等[11]提出一种基于社交网络图的推荐算法。微博内容虽然简短,但包含了大量信息,反映了用户兴趣,因而可对用户发布、转发与评论的微博文本内容进行挖掘,以发现用户兴趣。此外,用户关系扩展是社交网络发展中的主要问题之一,可对微博服务中的用户节点结构进行研究与分析,充分考虑用户间的关系进行微博推荐。本文提出的模型ITFM对特征进行权重处理,使用因子分解机模型,综合考虑用户兴趣及用户信任进行推荐。不同信任度的用户在推荐过程中拥有不同的可信度,不同用户对各个主题也具有不同的兴趣度。通过在真实数据集上进行模拟实验,验证了本文算法的有效性。
1 用户信任
考虑社交网络的实际情况,人们总是对身边越熟悉的人越信任,因而考虑用户间的信任关系能提高推荐准确率。构建一个社会网络有向无权图,图中各节点代表用户,图中的边代表用户间的关注关系。
2 用户主题兴趣
用户兴趣表示是个性化推荐中的一个重要环节,直接关系到推荐质量。用户微博蕴含了用户兴趣,因而用户微博所属主题能够反映用户兴趣倾向。本文使用主题兴趣度表示用户兴趣。
为了更好地提取用户微博主题兴趣,首先去除用户微博信息中的噪声与垃圾信息。用户转发及评论的微博通常也是用户感兴趣的内容,因此将用户发布、转发及评论的微博结合为一篇文档,不仅可以扩充用户微博信息,降低文本空间维度,还有利于挖掘微博用户兴趣,本文使用AT模型[12]进行处理。
2.1 AT模型
AT模型认为文档是由词组成的,而忽略了词在文档中出现的位置和词与词间的语法关联。对于每篇文档d,已知作者列表ad,单词w。每个作者对应一个在主题上的多项分布,用θ表示,每个主题又对应一个单词上的多项分布,用表示。θ和 分别依赖于对称的狄利克雷先验α和β 。图1中 A 表示数据集中的作者总数,T为主题个数。对于一篇文档 d 中的每个单词,从 ad中抽出一个作者 x ,然后根据该作者的分布随机抽出一个主题 z ,最后根据 z 在词上的多项分布,随机抽出一个单词。反复抽样 Nd(文档 d 中单词个数)次生成文档 d 。每篇文档均重复上述过程,生成数据集 D。
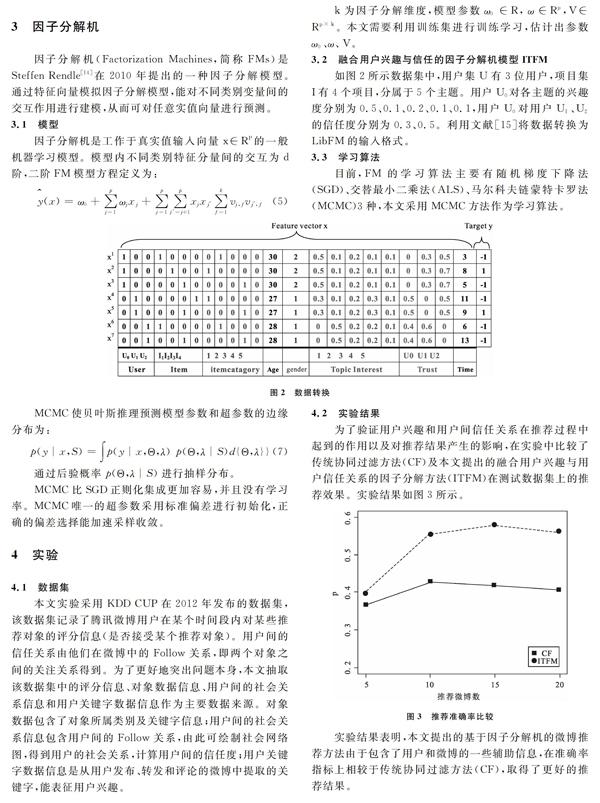
3.2 融合用户兴趣与信任的因子分解机模型ITFM
如图2所示数据集中,用户集U有3位用户,项目集I有4个项目,分属于5个主题。用户U0对各主题的兴趣度分别为0.5、0.1、0.2、0.1、0.1,用户U0对用户U1 、U2的信任度分别为0.3、0.5。利用文献[15]将数据转换为LibFM的输入格式。
3.3 学习算法
目前,FM的学习算法主要有随机梯度下降法(SGD)、交替最小二乘法(ALS)、马尔科夫链蒙特卡罗法(MCMC)3种,本文采用MCMC方法作为学习算法。
MCMC比SGD正则化集成更加容易,并且没有学习率。MCMC唯一的超参数采用标准偏差进行初始化,正确的偏差选择能加速采样收敛。
4 实验
4.1 数据集
本文实验采用KDD CUP在2012年发布的数据集,该数据集记录了腾讯微博用户在某个时间段内对某些推荐对象的评分信息(是否接受某个推荐对象)。用户间的信任关系由他们在微博中的Follow关系,即两个对象之间的关注关系得到。为了更好地突出问题本身,本文抽取该数据集中的评分信息、对象数据信息、用户间的社会关系信息和用户关键字数据信息作为主要数据来源。对象数据包含了对象所属类别及关键字信息;用户间的社会关系信息包含用户间的Follow关系,由此可绘制社会网络图,得到用户的社会关系,计算用户间的信任度;用户关键字数据信息是从用户发布、转发和评论的微博中提取的关键字,能表征用户兴趣。
4.2 实验结果
为了验证用户兴趣和用户间信任关系在推荐过程中起到的作用以及对推荐结果产生的影响,在实验中比较了传统协同过滤方法(CF)及本文提出的融合用户兴趣与用户信任关系的因子分解方法(ITFM)在测试数据集上的推荐效果。实验结果如图3所示。
实验结果表明,本文提出的基于因子分解机的微博推荐方法由于包含了用户和微博的一些辅助信息,在准确率指标上相较于传统协同过滤方法(CF),取得了更好的推荐结果。
5 结语
本文提出一种融合用户兴趣与用户信任关系的微博推荐方法,该方法在推荐过程中充分考虑了用户主题兴趣、用户间社会关系、推荐对象类别以及用户评分矩阵等信息。实验结果表明,用户兴趣与用户信任度在推荐过程中具有重要作用,是用户选择推荐结果的重要依据之一。然而,本文忽略了用户与推荐对象的其它信息对推荐结果的影响,如用户所处位置、用户行为等。在未来工作中将会把更多上下文信息加入推荐算法中,以期进一步提高推荐效果。
参考文献:
[1] 石磊,张聪,卫琳.引入活跃指数的微博用户排名机制[J].小型微型计算机系统,2012(1):110-114.
[2] ZANGERLE E,GASSLER W,SPECHT G,et al.Using tag recommendations to homogenize folksonomies in microblogging environments[M].Berlin:Springer Heidelberg,2011.
[3] PENG F,QIAN X,MENG H,et al.Research on algorithm of extracting micro-blog's hot topics[C]. International Conference onElectronics,Communications and Control ,2011:986-989.
[4] PHELAN O,MCCARTHY K,BENNET T M,et al.Terms of a feather:content-based news recommendation and discovery using twitter[C].European Conference on Advances in Information Retrieval.Springer-Verlag,2011:448-459.
[5] RICCI F,ROKACH L,SHAPIR A B.Introduction to recommender systems handbook[J].ACM Transactions on Information Systems,2004,22(1):1-4.
[6] KIM Y,SHIM K.TWIROB I:a recommendation system for twitter using probabilistic modeling[C].2013 IEEE 13th International Conference on Data Mining IEEE,2011,340-349.
[7] HOFMANN T.Probabilisticlatent semantic indexing[C].Proceedings of Annual Acm Conference on Research & Development in Information Retrieval Berkeley California ,1999,42(1):56-73.
[8] DUAN Y,JIANG L,QIN T,et al.An empirical study on learning to rank of tweets[C].Proceedings of the 23rd International Conference on Computational Linguistics,2010:295-303.
[9] CHEN K,CHEN T,ZHENG G,et al.Collaborative personalize tweet recommendation[C].Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval,2012:661-670.
[10] SHEN Q,WANG S,WANG R,et al.A friend recommendation algorithm based on the user relationship[C].Proceedings of International Conference on Materials Engineering,Manufacturing Technology and Control,2016.
[11] LO S,LIN C.WIR-A graph-based algorithm for friend recommendation[C].Proceedings of the 5th Atlantic Web Intelligence Conference ,2007:223-229.
[12] ROSEN-ZVI M,GRIFFITHS T L,STEYVERS M,et al.The author-topic model for authors and documents[C].Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence,2004.
[13] 王永貴,张旭,刘宪国.基于AT模型的微博用户兴趣挖掘研究[J].计算机工程与应用,2015(13):126-130,144.
[14] RENDLE S.Factorization machines with libFM[J].ACM Transactions on Intelligent Systems & Technology,2012,3(3):219-224.
[15] RENDLE S.Factorization machines[C].International Conference on Data Mining.IEEE,2011:995-1000.
(责任编辑:黄 健)
- 对疾控中心内部控制规范化问题的探讨
- 公立医院基于互联网新型支付方式下的内部控制研究
- 论房地产企业内部控制制度的建立与完善
- 浅谈事业单位固定资产内部控制
- 以全面预算为核心的事业单位内部控制研究
- 对现代企业内控建设的一些思考
- 浅谈企业内部控制与成本费用控制的相关性
- 浅谈企业货币资金的内部控制
- 事业单位财务内控管理的薄弱环节及改进
- 文化馆内部控制问题及其策略
- 勘探单位如何加强财务风险内控管理
- 高新区行政单位内部控制建设难点及对策
- 企业内部控制实施与问题应对策略探析
- 高速公路工程建设的成本控制与风险规避
- 国企改革中管理会计的作用探讨
- 新经济形势下国企成本控制的有效途径研究
- 管理会计在高校财务管理中的应用
- 关于企业实行会计电算化的风险和对策研究
- 推进乡镇会计基础工作精细化管理分析
- 对国有施工企业加强工程成本管理的思考
- 互联网环境下企业集团集中会计核算实践探索
- 论行政事业单位如何加强会计监督
- 新《政府会计制度》下非流动资产主要核算变动简析
- 我国化工行业上市公司环境会计信息披露问题研究
- 财务共享服务下管理会计信息化有效实施策略分析
- team sb/sth (up) (with sb/sth)
- teamster
- teamsters
- team up
- team up with
- team up (with sb)
- team (up) (with sb)
- teamwork
- teamworking
- teamworks
- team²
- team¹
- teapot
- teapotful
- teapots
- tear
- tearable
- tearableness
- tearablenesses
- tear apart
- tear down
- teardrop
- teardrops
- teared
- tearer
- 入水激一激
- 入水见长人
- 入水问渔、入泽问童
- 入汛
- 入法眼
- 入泮
- 入泮之喜
- 入洛
- 入洞房的新郎官——光头净脸
- 入派三声
- 入流
- 入海口
- 入海捞针
- 入海求
- 入海箕沙
- 入海算沙
- 入深水者得蛟龙,入浅水者得鱼虾
- 入港
- 入火
- 入火海,上刀山
- 入火赴汤
- 入火蹈汤
- 入火龙
- 入灭
- 入牢