摘要:针对传统关联规则 Apriori 算法难以适应大数据的问题,为提高可信计算平台日志数据分析效率, 提出了一种基于Hadoop的可信计算平台日志分析模型。构建了日志分析模型总体框架,对非结构化原始日志数据进行垂直划分,采用分布式文件存储系统,结合MapReduce编程模式给出一种分布式Apriori并行垂直算法。通过日志挖掘建立用户行为关联规则库,并采用规则匹配实现对用户异常行为的检测。理论分析和实验数据证明,该模型在大数据环境下能够有效提高日志分析效率。
关键词:日志分析; 可信计算;Hadoop平台;数据挖掘;Apriori算法
DOIDOI:10.11907/rjdk.173291
中图分类号:TP301
文献标识码:A 文章编号:1672-7800(2018)008-0071-05
英文摘要Abstract:To solve the problem that the Aprioro algorithm can not adapt to mass data,and to improve the efficiency of analyzing log data of Trusted Computing Platform,a trusted computing log analysis model was constructed based on Hadoop platform.The framework of log analysis model was constructed.A parallel vertical algorithm of Apriori was proposed in MapReduce programming model and distributed file storage system by dividing the original non-structured log data into vertical partitioning pattern.Through log mining,the user behavior association rule base is set up.By rule matching,the user's abnormal behaviors are is detected.Mathematic analysis and simulation experiments show that the model can effectively improve the efficiency of log analysis in mass data environment.
英文关键词Key Words:log analysis; trusted computing; Hadoop platform; data mining; Apriori
0 引言
为了保障计算系统平台安全、可信赖地运行,提出了可信理念。可信计算作为一种新型信息安全技术,已经成为信息安全领域的研究热点[1]。可信平台日志是安全设备运行过程中产生的记录数据,通过对可信计算平台产生的日志进行挖掘分析,可有效判断系统是否安全運行。
数据挖掘[2]是日志分析的重要方法之一。Agrawal等[3-4]首先提出了基于频繁项集的经典关联规则Apriori算法。文献[5]采用哈希函数,提出了一种基于散列(hash) 技术产生频繁项集的算法;文献[6]针对大数据量以及数据库重复扫描问题,基于采样思想提出了一种关联规则算法;文献[7]基于DIC思想,采用全局剪枝缩小候选2-项集范围,提出了一种APM并行化算法;文献[8]将极大序列挖掘和闭序列挖掘相结合,提出了一种压缩序列模式挖掘算法,通过挖掘少量有代表性的的频繁序列组合以表示全部序列模式信息;文献[9]基于前缀等价类技术,提出了一种采用垂直数据格式的串行数据挖掘算法Eclat。采用混合搜索策略,分析效率较Apriori算法有明显提高。文献[10]基于概念格理论,在Eclat算法基础上通过划分项集子概念格,独立生成频繁项集,缩短了挖掘时间。文献[11]提出了基于垂直格式的序列模式算法SPADE,将序列数据库转换为记录项集位置的垂直格式数据库,然后动态连接挖掘频繁序列模式,算法只需扫描3次数据库,减少了 I/O开销。
在大数据环境下,分布式日志分析系统因其高可扩展性,能够有效提高日志分析效率。基于Hadoop的日志分析系统,通过增加水平扩展,有效解决了待处理数据量增加的问题。文献[12]将MapReduce编程模型应用于大数据处理;文献[13]提出了一种Barierless MapReduce并行编程模型,改善了键值对排序不足问题;文献[14]针对HDFS存储海量小文件元服务器内存开销过大问题,提出了一种基于混合索引的小文件存储策略;文献[15]将MapReduce编程模型应用于Eclat挖掘算法,但存在频繁项缺失问题;文献[16]利用MapReduce编程模型对Apriori算法进行改进,给出了在Hadoop分布式架构下实现数据挖掘的过程。
本文基于Hadoop大规模并行计算平台,在传统Apriori算法基础上对日志源数据库进行转换、垂直化划分,在MapReduce框架下提出了一种分布式垂直化Apriori算法,在此基础上构建了一种可信平台日志分布式分析模型。
1 关联规则相关定义
推论:若其中所有项目P包含元素a,使得(P)
可信平台日志分析模型通过对可信计算终端生成的不同格式日志进行预处理,统一日志格式并生成事务数据库,进而通过挖掘日志数据中的关联规则,分析判定用户行为的合法性。模型主要包括预处理模块、挖掘模块和关联分析模块。日志预处理模块主要负责对可信计算终端生成的文件访问、程序控制、网络访问和策略加载等日志记录进行格式统一,通过筛选生成事务数据库,并将数据转换为适合后续挖掘模块的数据格式;日志挖掘模块采用分布式垂直Apriori算法进行数据挖掘,形成关联规则;关联分析模块通过比对关联规则,分析用户行为的合法性。模型基于Hadoop分布式计算和存储平台,模型架构如图1所示。
2.1 日志数据预处理模块
可信计算终端生成的文件访问、程序控制、网络访问及策略加载等日志记录格式并不完全相同,为保持后续数据挖掘模块的稳定独立,不受制于原始日志数据格式,需对日志格式进行预处理,实现格式上的统一。考虑到可信计算终端操作系统依据的BLP模型是根据主客体安全级别间匹配关系决定是否授予主体访问权限,本文将特定事件审计记录作为独立实体进行观察,在5W1H数据分析模型基础上定义了一种基于键值存储的可信计算平台日志格式模型,见表1。
在日志数据预处理过程中,为提高后续数据挖掘模块工作效率,对于完全重复的日志记录只保留一条。同时,对其它字段内容相同,仅发生时间不同但又间隔极短的日志记录设置时间窗口,按时间窗划分日志记录集,每个集合中仅保留其对应时间窗内的第一条日志记录。可信计算平台日志预处理思路见图2,单个时间窗口内日志处理流程见图3。
2.2 日志数据挖掘分析模块
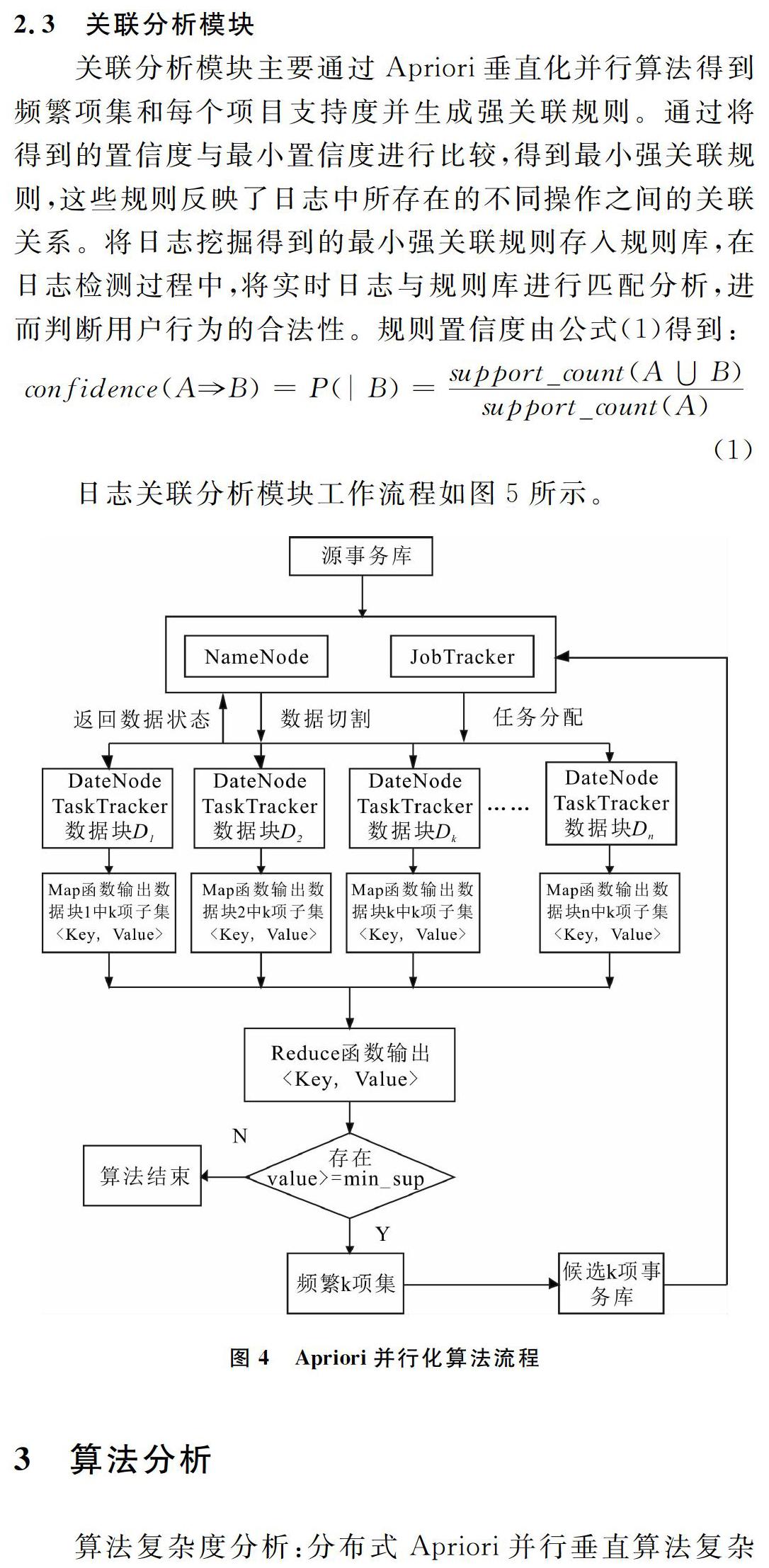
数据挖掘模块是日志分析模型的核心模块,其任务是采用关联分析技术寻找可信计算平台日志中所隐含的关联规则。在Hadoop系统中,数据被默认划分为大小约64MB的水平分块,但水平划分存在项目分布于不同水平分块中的问题,因此计算出的频繁项集会出现漏项。为提高数据挖掘效率,本文采用并行系统Hadoop中的HDFS存储系统存储原始数据,对原始数据进行垂直划分,在MapReduce计算框架下将互不相交的数据块分配至不同计算节点,进行并行计算,以增大并行粒度,提高计算效率。模块部署一个主节点和若干从节点。NameNode和JobTracker共用一台计算机作为主节点,负责日志数据的切割、数据块分配以及计算任务分配。DataNode和TaskTracker也使用同一台机器作为从节点,主要负责日志切分后数据块的存储以及负责MapReduce任务的执行,即负责执行日志分析模型挖掘模块。
Apriori算法是数据挖掘经典算法,基于水平数据格式进行挖掘,对日志数据库的处理采用水平数据结构,如表2所示。
但水平格式需要在迭代过程中多次扫描数据库,并在扫描过程中需要对候选项集与事务进行模式匹配,耗费大量时间。本文借鉴文献[18]的思想,采用垂直数据格式,如表3所示。由定理1可知,若支持项目A的事务集合为TA,支持项目B的事务集合为TB,则同时支持项目A、B的事务为TA和TB的交集,因此只需进行交集运算,无需进行候选项集与事务模式匹配即可得到候选项集支持事务库。
假设Hadoop平台能并行处理最大数据量为maxmap,数据文件大小为N,事务数为K,HDFS的数据块block的大小为J,则数据文件划分为N/J个数据块。若N/J
Hadoop平台下Apriori垂直化并行挖掘算法流程如下:
(1)扫描事务数据库,将源数据库平均分割为不相交的数据块m1,m2,…,mn,将数据块分发至各计算节点上的Map函数进行并行处理。如源数据块为Dk:k1,k2,…,kn,经Map函数转化后数据格式为k1,Dk;k2,Dk;…,kn,Dk,记录每项的支持事务代码,计算完成后输出临时文件< item:Tid>,其中item为项集,Tid为支持该项集事务代码。
(2)将各节点Map阶段的本地输出结果合并,输出
(3)用Reduce函数对各节点输出数据进行整合并转换为垂直1-项集,经过Reduce函数处理后的数据如下:k1,D1,D2,…,Dn1;k2,D1,D2,…,Dn2;kn,D1,D2,…,Dnn;将支持事务集按范围平均分割为不相交的数据块,统计支持每个项的事务数,删除支持事务数小于最小支持事务数的项,进而得出频繁1-项集L1。
(4)频繁1-项集L1中的项两两连接得出候选2-项集C2,C2的支持事务标识符集合Tidset通过计算各分块的频繁1-项集的交集得到。
(5) k←2。
(6)对频繁(k-1)-项集利用定理2和推论1进行剪枝,去掉不可能成为频繁k-项集的项集,将各(k-1)-频繁项集两两连接得出候选k-项集。通过计算支持候选k-项集中各(k-1)-频繁项集的事务交集,得出支持各项集的k-项事务集,将候选k-项集项目的TidSet分塊输出分发给map进程。各个进程并行计算候选k-项集支持度,reduce进程负责将各个map进程的输出结果汇总,得到全局频繁k-项集。利用步骤(3)中的分块思想,将全局频繁k-项集分块输出到不同文件中。
(7) k←k+1。
(8)重复执行步骤(6)-步骤(7),直到不再有频繁项集产生。
(9)输出频繁项集Lk。
Hadoop分布式平台下的Apriori垂直化并行算法计算流程如图4所示。
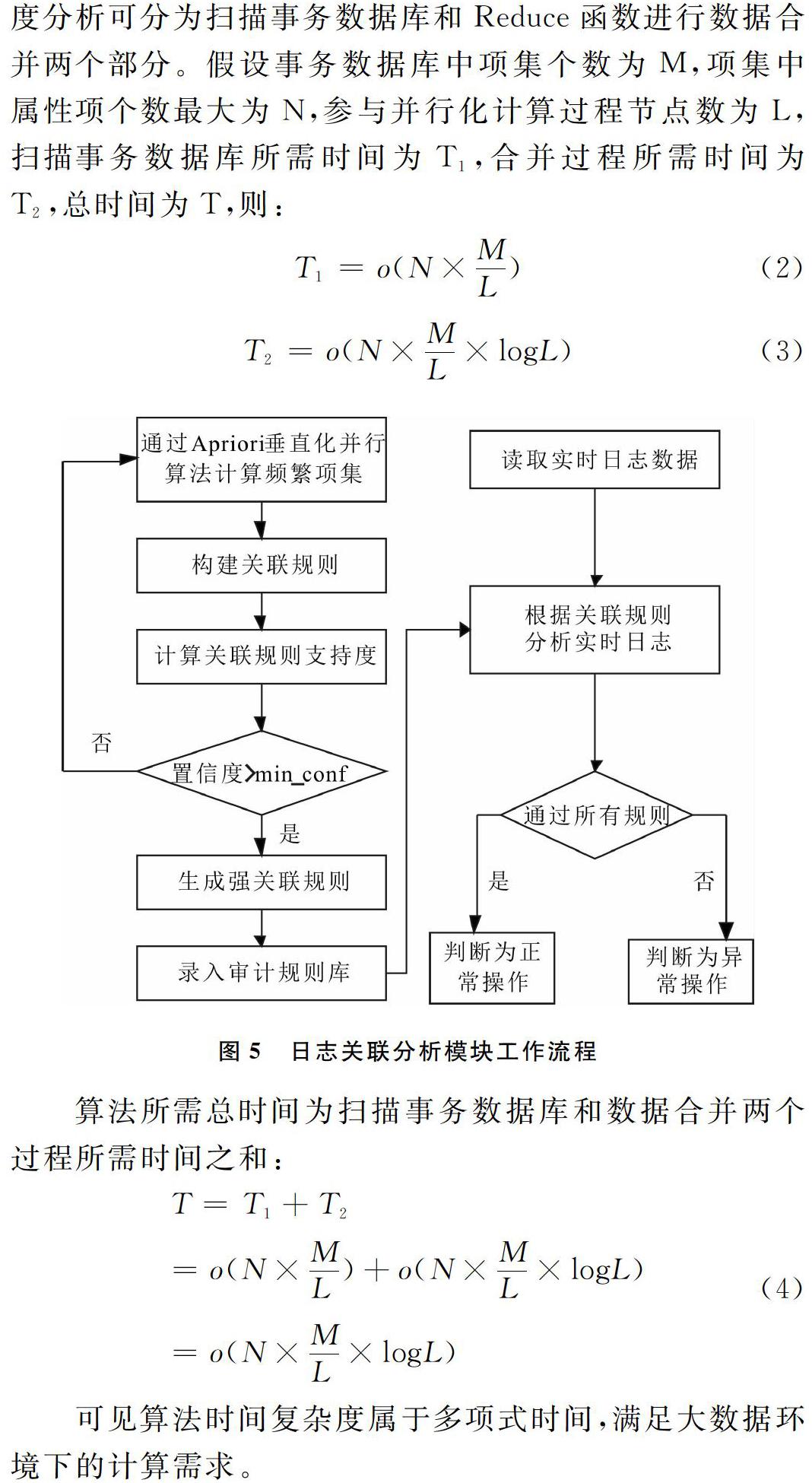
2.3 关联分析模块
关联分析模块主要通过Apriori垂直化并行算法得到频繁项集和每个项目支持度并生成强关联规则。通过将得到的置信度与最小置信度进行比较,得到最小强关联规则,这些规则反映了日志中所存在的不同操作之间的关联关系。将日志挖掘得到的最小强关联规则存入规则库,在日志检测过程中,将实时日志与规则库进行匹配分析,进而判断用户行为的合法性。规则置信度由公式(1)得到:
日志关联分析模块工作流程如图5所示。
可见算法时间复杂度属于多项式时间,满足大数据环境下的计算需求。
基于Hadoop的分布式垂直划分Apriori算法与传统Apriori算法相比,分布式垂直划分Apriori算法在处理大数据过程中,整个数据挖掘过程仅扫描一次数据库,采用垂直化的数据结构,将源结构大数据垂直划分为互不相交、相互独立的数据块,在MapReduce计算框架下将各独立数据块分配至Hadoop平台不同的计算节点进行处理,增大了并行粒度,减少了各计算节点上数据交集的运行次数,提高了可运算数据规模和挖掘效率。算法通过将并行计算过程中产生的中间数据进行合并,减少了中间结果的数据量,显著降低了并行挖掘过程中的通信成本。
4 结语
本文针对传统关联规则 Apriori 算法难以适应大数据集的问题,提出了一种基于Hadoop的可信计算平台日志分析模型。结合MapReduce编程模式给出一种分布式
架构下垂直并行挖掘算法,对源结构数据进行垂直划分,分配给不同计算节点进行处理,增大了并行粒度,提高了并行挖掘效率。通过实时日志与规则库进行匹配,实现对用户异常行为的检测,日志分析结果为主动防御提供了决策支持。
参考文献:
[1] 冯登国,秦宇,汪丹,等.可信计算技术研究[J].计算机研究与发展,2011,48(8):1332-1349.
[2] 吉根林,赵斌.面向大数据的时空数据挖掘综述[J].南京师大学报:自然科学版,2014,37(1):1-6.
[3] AGRAWAL R,SRIKANT R. Fast algorithms for mining association rules[C].Proceedings of International Conference on Very Large Databases.1994:487-499.
[4] AGRAWAL R, IMIELINSKI T SWAMI A.Mining association rules between sets of items in large databases[J].ACM SIGMOD Record,1993,22(2) :207-216.
[5] PARK J S,CHEN M S,YU P S.An effective hash-based algorithm for mining association rules[J].SIGMOD Record,1995,25(2) :175-186.
[6] TOIVONEN H.Sampling large databases for association rules[C].Proceedings of the 22nd International Conference on Very Large Databases.1996:1-12.
[7] CHEUNG D W,HAN J,NG V,et al.A fast distributed algorithm for mining association rules[C].Proceedings of International Conference on Parallel and Distributed Information Systems.1996:31-44.
[8] 童咏昕,张媛媛,袁玫,等.一种挖掘压缩序列模式的有效算法[J].计算机研究与发展,2010,47(1):72-80.
[9] ZAKI M J,PARTHASARATHY S,OGIHARA M,et al.New algorithms for fast discovery of association rules[C].Proceedings of 3rd intlconf on knowledge discovery and data mining.Palo Alto,California:AAAI Press,1997:283-286.
[10] ZAKI M J.Scalable algorithms for association mining[J].IEEE transactions on knowledge and data engineering,2000,12(3):372-390.
[11] ZAKI M J.SPADE:an efficient algorithm for mining frequent sequences[J].Machine Learning,2001,42(1):31-60.
[12] DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[J]. Communications of the ACM,2008,51(1) :107-113.
[13] VERMA A,ZEA N,CHO B,et al.Breaking the MapReduce stage barrier[C].Proceedings of 2010 IEEE International Conference Cluster Computing(CLUSTER10),2010:235-244.
[14] 熊安萍,黄容,邹样.一种基于混合索引的HDFS小文件存储策略[J].重庆邮电大学学报:自然科学版,2014,27(1):97-100.
[15] 李伟卫,赵航,张阳,等.基于MapReduce的海量数据挖掘技术研究[EB/OL].http://www.cnk.net/kcms/detail /11.2127.TP.20120601.1457.016.html.
[16] 崔妍,包志强.关联规则挖掘综述[J].计算机应用研究,2016,33(2):330-334.
[17] 崔貫勋,李梁,王柯柯,等.关联规则挖掘中Apriori算法的研究与改进[J].计算机应用,2010,30(11):2952-2955.
(责任编辑:杜能钢)
- 马克思历史观、唯物史观与历史唯物主义
- 贫困治理的场域观与社会工作增权
- 减负、整合、创新:我国最低生活保障制度的目标调整
- 政府购买公共服务的风险评价:一个实证模型
- 信托公司业务转型发展研究
- 我国大城市空间结构与功能协调性分析
- 清中叶文人曲家孙馨祖考略
- 清代戏曲家石琰生平、家世与交游考
- 稀见清代传奇剧本《灵台记》叙论
- 六位清代戏曲家生平考述
- 清代戏曲文献研究(四篇)
- 浦东派琵琶艺术在安徽的传承发展述论
- 徽州传统聚落与建筑的审美特征及现代启示
- 从五年规划透析公共政策制定及其传播效果
- 论修辞学理论建构中的美辞学叙事范式
- 新闻2.0时代硅谷如何驯化美国新闻业
- 我国未成年人刑事特别程序之演进逻辑及其启示
- 我国社会保险制度深化改革的基本思路选择
- 法理学“性”、“化”修辞所衍生的研究缺失
- 野村浩一的毛泽东研究论析
- 网络政治道德的构建与“后真相”的救治
- 逃离此刻与专注当下
- 杨朱的思想及其衰亡初探
- 道家视域下的“身国同构”与“内圣外王”
- 人的类型与境界
- copresent
- copresented
- copresenting
- copresents
- copresident
- copresidents
- coprince
- coprinces
- coprincipal
- coprincipals
- coprisoner
- coprisoners
- coprocessing
- coprocessings
- coproduced
- coproducer
- coproducers
- coproduces
- coproducing
- coproduction
- co-production
- coproductions
- co-promoter
- copromoter
- copromoters
- 广颡丰颐
- 广颡深颐
- 广马
- 庀
- 庀事
- 庀具见贫
- 庄
- 庄与谐
- 庄严
- 庄严华丽
- 庄严地说出表示决心的话或对某事提出保证
- 庄严宝相
- 庄严或美丽的色彩
- 庄严持重
- 庄严敬重的样子
- 庄严整饬
- 庄严显赫
- 庄严正大
- 庄严的寺庙
- 庄严的样子
- 庄严的盟誓
- 庄严而不可变更的法令
- 庄严肃穆的殿堂
- 庄严虔诚
- 庄严隆重的典礼