摘 要:随着网络招聘的普及,求职者需要浏览和筛选的数据越来越多,如何从大量的、非结构化的网络信息中快速而准确地抽取需要的信息非常重要。基于VIPS视觉分割算法,利用网页所呈现出来的布局结构和视觉特征,对招聘页面进行视觉分割处理,在页面分割的基础上,抽取特定块内的文本信息,实现了关键词查找抽取感兴趣的视觉块内信息。实验结果表明,基于VIPS的职位信息抽取技术能够有效抽取出招聘页面内重要的文本信息,优化了信息抽取结果。
关键词关键词:网络招聘;信息抽取;视觉分割;VIPS;职位信息
DOIDOI:10.11907/rjdk.151404
中图分类号:TP301
文献标识码:A 文章编号文章编号:16727800(2015)009002203
0 引言
网络招聘凭借其覆盖面广、成本低廉、有针对性和时效性等优势,已经成为大学毕业生和职员求职的首选方式。然而,随着互联网信息量指数级增长,这种新兴的招聘方式显现出一些弊端,如信息真实度低、信息处理难度大、成功率较低等。解决这些问题的关键步骤就是从网页中抽取出人们感兴趣的信息。大多数招聘页面是根据客户端用户请求,动态生成具有较强格式的半结构化网页。网页中包含的信息量很多,当我们应用于信息检索、数据分类、推荐系统和观点挖掘等领域时,会发现网页中有许多冗余信息,网页信息抽取技术将提高数据的利用率。
当前的网页信息抽取技术大多数是基于HTML标签本身,对视觉特征[1] 考虑很少。事实上最终展现给用户的是浏览器渲染过的网页,通过利用网页结构和视觉特征能有效地提高网页信息抽取系统的准确率,优化抽取结果。
本文设计了一个抽取职位信息系统,该系统利用Navigate方法获取页面内容,基于HTML标签生成页面树,结合基于视觉的页面分割算法VIPS (VIsionbased Page Segmentation)[3] 分割页面,利用页面解析器抽取文本信息,通过重写迭代器方法实现关键词查找,抽取出用户感兴趣的信息。
1 职位信息抽取流程
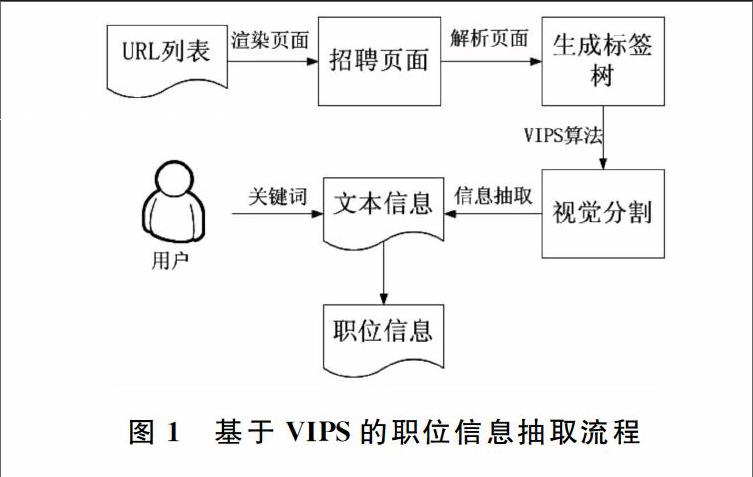
基于VIPS的职位信息抽取系统从所输入的招聘网页出发,对URL列表对应的招聘页面进行渲染并显示页面内容,根据招聘页面的HTML源码生成标签树,利用VIPS算法对页面进行视觉分割,结合页面解析器HTMLParser对树节点对应模块的文本信息进行抽取,通过重写迭代器,用户通过关键字查找,抽取特定树节点对应的文本信息,最后得到用户感兴趣的职位信息。基于VIPS的职位信息抽取过程如图1所示。
图1 基于VIPS的职位信息抽取流程
2 职位信息抽取关键组件设计
2.1 基于视觉的招聘页面结构
基于视觉特征的网页结构相比传统的标签树结构而言,更有可能分析出招聘页面内文本信息的语义结构。结构中最大根节点下的子节点可能会传达一些与招聘相关的信息,如岗位描述、岗位职责、联系方式等。基于VIPS的网页标签树中每个结点称之为“块”,这些块是HTML标签的基本元素或是基本元素的集合。
将每个招聘页面表示成一个三元组Ω = {Ο,Φ,δ},其中Ο = {Ω1,Ω2,…ΩN},代表给定招聘页面上所有块的集合,块与块之间没有重叠,每一个子块Ωi的结构又被递归定义为上述三元组Ωi={Οi,Φi,δi}。Φ = {φ1,φ2,…φT},代表招聘页面上的分割条集合。其中每个分割条都设置一个权重值,描述分割条的可见性。权重值相等的分割条划分到一个集合中。δ代表不同块之间的关系,用公式描述这种关系为:δ=Ο×Ο→ Φ∪{NULL}。例如,Ωi和Ωj是集合Ο中的两个块,δ(Ωi ,Ωj)≠NULL,代表块Ωi和块Ωj之间存在一个分割条δ(Ωi,Ωj),或者说两个对象相邻,否则就会有其它对象在两个块Ωi和Ωj之间。
VIPS算法对于每一个视觉块都定义了一个DoC(Degree of Coherence)值,用来描述当前视觉块内的文本内容联系紧密程度。DoC值具有以下两个特点:
(1)DoC值越大,说明当前视觉块内部的文本内容联系越紧密, DoC值越小,说明内部联系越松散。
(2)在一棵层次树中,子块的DoC值比父块的DoC值大。
在对招聘页面进行视觉分割前,预定义一个PDoC (Permitted Degree of Coherence) 值,控制分割后视觉块的粒度大小。PDoC值越大,分割后的视觉块就越精细,反之,视觉块越粗糙。
2.2 招聘页面标签树构建
构建招聘页面标签树是对招聘页面进行视觉分割的必要步骤,可以利用网页的HTML编码来生成。HTML标签大多是成对出现,每一对都有一个开始标签(< >)和一个结束标签(),并且标签之间可以存在嵌套结构,因此可以将一对标签视作标签树的一个节点,嵌套在其中的标签对看成是当前节点的子节点,从而构建标签树。
由于许多招聘页面的HTML源码没有完全遵循W3C标准,因此需要预先对部分HTML文档进行编码清洗。目前已经有一些用于清洗HTML源码的开源程序,如Tidy。结合该程序对招聘页面的HTML源码进行规范化,比如对于不要求有结束标签的节点,插入结束标签以保持节点平衡,订正格式错误的标签、修改嵌套层次有问题的标签等。
2.3 招聘页面的视觉分割
基于视觉因素分割招聘页面,首先需要提取当前招聘页面的视觉块。通过对招聘页面构建标签树,可以从标签树的所有节点中递归提取视觉块。但是,一些HTML标签常用来组织数据,如:
等等,对于这类标签,不能将它们作为视觉块单独提取出来,而是对它们的子节点进行提取。对于已经提取出的视觉块,根据每个块中的视觉因素差异设置Doc值。视觉块迭代提取过程代码如下:
Algorithm DivideTagtree(pNode,nLevel)
{
IF(Dividable(pNode,nLevel)==TRUE){
FOR EACH child OF pNode{
DivideTagtree(child,nLevel);
}
}
ELSE{
Put the SubTree(pNode) into the
pool as a block;
}
通过判断当前标签节点和它的子节点的背景色、大小、形状等视觉因素,决定是否对当前标签节点所代表的视觉块继续分割。对于所有提取出来的视觉块,将它们保存到视觉块池中,以便检测分割条。
对大多数招聘页面而言,包含不同内容的视觉块之间往往存在分割条,这个分割条或者是直线,或者是长条矩形等图形元素。从视觉角度看,分割条可以作为识别语义信息的指示器,因此在提取视觉块后需要检测页面的分割条。用一个二维向量(Ps,Pe)定义分割条,其中Ps是分割条的开始坐标,Pe是结束坐标。根据Ps和Pe计算当前分割条的高度和宽度。检测分割条的具体算法如下:
(1)对分割条集合进行初始化。最初的分割条集合中个数为1,它的开始和结束坐标分别为整个招聘页面的开始坐标和结束坐标。
(2)对于每一个视觉块,判断分割条的位置关系。如果视觉块被分割条包围,则将该分割条分裂为多个分割条;如果视觉块与分割条有一部分重合,则根据视觉块的边界修改分割条坐标;如果视觉块跨越分割条,则删除该分割条。
(3)移除招聘页面边界的4个分割条。对于检测出来的分割条,根据分割条相邻的两个视觉块颜色、字体大小、不同视觉块之间的距离设置分割条权重。两个视觉块之间的距离越远,颜色、字体大小差异越大,该分割条的权重越大,分割条两侧的视觉块语义信息差异就越大。
2.4 招聘页面内容结构重建
当所有分割条都设置了权重值,就重新构建招聘页面的内容结构。首先从权重值最小的分割条开始,将该分割条两侧的视觉块合并组成一个新的视觉块。整个重建过程是一个迭代过程,当遇到权重值最大的那个分割条时结束迭代,同时,重新设置那些合并后的新视觉块的DoC值。对于这些新的视觉块,将它们的DoC值与预定义的PDoC进行比较,如果新视觉块的DoC值达到PDoC值规定的视觉块粒度大小,迭代过程将停止。否则,重新进行迭代过程。
当迭代过程全部结束时,原来那些较小的具有相似视觉特征的视觉块会被合并成一个语义块,语义块内的文本内容联系十分紧密。此时整个招聘页面的内容结构主要由语义块组成,每个语义块内的信息内容相似,方便对招聘信息进行结构化抽取。
2.5 页面解析
用户输入一个URL后就会得到一个招聘页面,这个页面包含了大量的元素,而页面中往往包含了各种各样的信息,如图片、文字等等,大多数情况下重要的信息都在页面的文本中,因此需要设计一个页面解析模块,提取页面的文本信息。
解析网页文本内容的方法很多,例如可以使用正则表达式,但是正则表达式比较抽象和复杂,并且复用性差,针对每个特定的网页都需要单独写正则表达式,目前比较流行的页面解析器有HTMLParser。HTMLParser是一个开源的Java库,它是专门用来解析HTML文本内容的,具有高效性。
3 实验结果
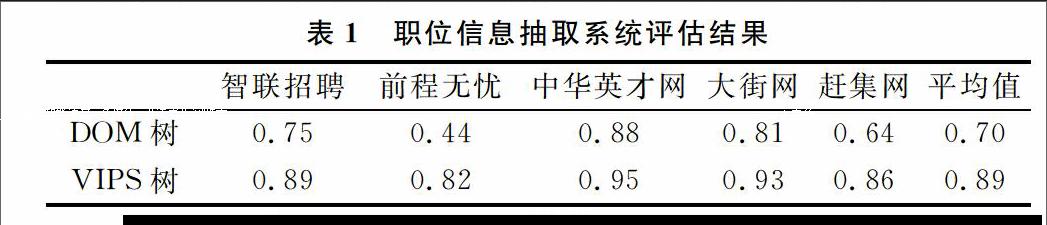
本文实验硬件配置如下:Intel(R)Pentium(R) 4 CPU 2.80GHz,内存2G,开发IDE为:Microsoft Visual Studio 2010, C#语言。为了评估职位信息抽取系统性能,分别在智联招聘、前程无忧、中华英才网、大街网、赶集网随机选取一个招聘页面,在这5个页面按照DOM树和VIPS树两种结构分割页面,分别抽取10种不同的招聘信息,计算每种树抽取信息结果的查准率,表1显示了结果。
可以看出,不同网站的招聘页面查准率各不相同,这主要是由于各个网站的设计规范程度不同,查准率高的网页往往比较干净,没有过多的广告,排版也比较合理,比如中华英才网的设计十分美观,信息也比较突出,抽取的结果自然契合度高。另一方面,可以看出基于VIPS树的职位信息抽取系统比基于DOM树的信息抽取系统具有更高的查准率,因此可以得出结论:基于视觉特征来分割页面并抽取信息,能够使信息抽取过程更加优化,结果更准确。
4 结语
本文基于网页结构中的视觉因素,设计和实现了抽取招聘页面内的职位信息。利用Navigate方法获取招聘页面内容,结合VIPS算法对页面进行视觉化分割,用页面解析器HTMLParser抽取文本信息,通过重写迭代器方法实现关键词查找功能。经实验测试,本文设计的系统能够实现页面的输入与显示、生成标签树,抽取节点文本信息和关键词查找功能。通过两种树的信息抽取结果对比,得出基于视觉分割的信息抽取方法比基于DOM树的结果更精确的结论,证明本文设计方案是可行的。下一步主要是研究职位信息的并行抽取技术,实现抽取大量的职位信息,另外对于抽取到的职位信息,还可以进行聚类分析,对一些信息进行归类、筛选。
参考文献参考文献:
[1] 朱凯.基于结构和视觉特征的网页信息抽取技术的研究与实现[D] .杭州:浙江大学,2008.
[2] 龙丽,庞弘燊.国外 Web 信息抽取研究综述[J] .图书馆学刊,2008 (5):1316.
[3] CAI D,YU S,WEN J R,et al.VIPS:a visionbased page segmentation algorithm[R] .Microsoft technical report,MSRTR200379,2003.
[4] BING LIU.Web数据挖掘[M] .第2版.北京:清华大学出版社,2013:287288.
[5] 于满泉,陈铁睿,许洪波.基于分块的网页信息解析器的研究与设计[J] .计算机应用,2005,25(4):974976.
[6] 顾涛.基于 Hadoop 的 Web 信息提取和垃圾信息过滤研究与实现[D] .成都:电子科技大学,2012.
[7] YANG Y,LUK W S.A framework for web table mining[C] .Proceedings of the 4th international workshop on Web information and data management.ACM,2002:3642.
[8] CHANG C H,KAYED M,GIRGIS M R,et al.A survey of web information extraction systems[J] .Knowledge and Data Engineering,IEEE Transactions on,2006,18(10):14111428.
[9] PASTERNACK J,ROTH D.Extracting article text from the web with maximum subsequence segmentation[C] .Proceedings of the 18th international conference on World wide web.ACM,2009:971980.
责任编辑(责任编辑:杜能钢)
- 网络安全技术及策略在新乡学院校园网中的应用探究
- 复杂网络模型比较研究
- 云计算环境下的电子商务数据管理模式研究
- 计算机在机关事业单位人事管理中的应用
- 集成物联网的企业安全生产管理系统设计与实现
- 简单个性化推荐策略研究
- 基于大数据下的计算机信息处理技术研究
- VFP查询在普通中专录取数据中的运用
- 基于Hadoop的钢铁企业节能潜力大数据分析系统设计与实现
- 高校教师教学业绩考核系统的分析与设计
- ADO.NET中数据访问方式的探讨
- 保险业呼叫中心的数据仓库设计与实现
- 数据结构中队列的应用研究
- 计算机技术与企业信息管理的整合分析
- 提高课堂教学效率之我见
- 基于能力培养的路由与交换技术课程考试研究与实现
- 融入“互联网+”时代 优化初中历史教学
- 微课在计算机基础教学中的应用探讨
- 计算机组装与维护实验教学中存在的问题与改革方案
- 转型背景下操作系统教学方法的改革与实践
- 网络教学中教学设计方法的研究与探讨
- 《程序设计基础》教学探索
- 全国计算机等级考试组织管理工作的思考
- 西部地区高校计算机科学与技术专业综合改革的实践
- 关于远程教育网络课程资源建设的探析
- goddize
- godfather
- godfathered
- godfatherhood
- godfathering
- god-fathering
- godfatherly
- godfathers
- godfathership
- god-fearing
- god fearing
- godforsaken
- godforsakenly
- godforsakenness
- god/heaven forbid!
- godkin
- god knows/heaven knows
- godless
- godlessly
- godlessness
- godlessnesses
- godlike
- godlikeness
- godlikenesses
- godmother
- 仗势胡作非为,蛮不讲理
- 仗恃
- 仗恃军队
- 仗恃有人恩宠而横行霸道
- 仗恃有功、获得宠信而骄傲自大
- 仗恃有功和有人宠爱
- 仗恃有功而希望获得恩宠
- 仗恃自己有名而妒忌有才干的人
- 仗恃自己有才能
- 仗恃自己的智慧和才能,骄傲自大
- 仗恃,凭借
- 仗托
- 仗朝之年
- 仗权势行事
- 仗格
- 仗棰
- 仗气
- 仗气使酒
- 仗着
- 仗着岁数大,摆老资格
- 仗着工夫捱
- 仗着已有才能而意气用事
- 仗着年龄小而撒娇
- 仗着是熟人、老交情而不拘小节
- 仗着死