

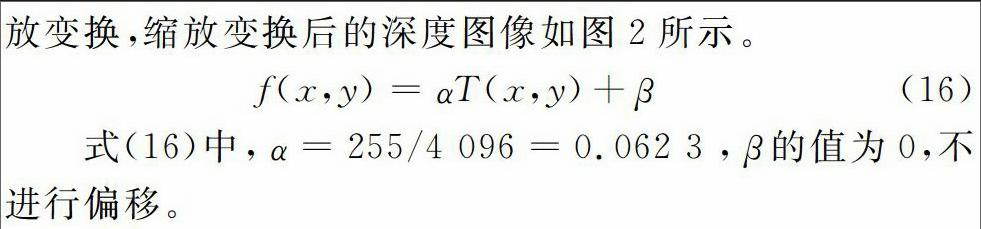
摘 要:在对Kinect采集到的图像进行预处理后,为了实现行人运动目标检测,需要对行人目标进行特征识别,然后将识别分割的区域作为行人目标的备选区域。通过改进的自适应高斯混合模型的背景建模对预处理后的深度图像进行行人目标分割,分离出有用信息,然后利用Freeman鏈码方法提取连通域轮廓,作为行人目标的人体头部区域,便于后续对行人目标的跟踪与统计研究。试验表明,最终得到的结果达到了预期目标,算法准确性与鲁棒性很好。
关键词:背景建模;深度图像;高斯混合模型;Freeman链码;轮廓提取
DOIDOI:10.11907/rjdk.171413
中图分类号:TP312
文献标识码:A 文章编号文章编号:1672-7800(2017)008-0039-04
0 引言
随着城市化的快速发展,人口髙密度化带来的各种经济、安全问题成为当今社会的热点问题。公共场合下的人流统计已应用于安防、商业、交通管理等领域。在商业领域,商场内各个区域、时段的人流统计数据对提高经营决策的科学性、资源调配的合理性、消费环境的舒适度等方面起着至关重要的作用;在博物馆、汽车站、地铁口、机场等公共场所中,实时、精准的人流统计信息,对于人员调度、资源分配和突发事件预防等同样起到决定性的指导作用。当前基于计算机视觉的人流统计是该领域主流的技术方案,但是在现实研究中如何实现准确率高、实时性好的行人统计系统仍然是一个难点。因此,行人运动目标分割与检测技术是目前研究的主要方向,具有较强的现实意义。
1 国内外研究现状
目前应用较为广泛的自动客流统计系统(AntoPassengercouni)主要有接触式和非接触式两种设计思路。接触式方法主要分为两种,一种采用入口机械栏杆装置,一种采用踏板压力传感器;非接触式方法也分为两大类,一种采用红外检测技术,另一种则是基于机器视觉的方法。机器视觉的方法是目前新兴的解决方案。国外如Terada和Yoshida[1]采用双目摄像机,通过左、右眼获得的时空图像实现人数统计;Kettnaker和Zabih采用多个不重叠的摄像机,根据所摄内容的相关性及轨迹跟踪的时间帧关系实现人数统计;Schofield和Stonham采用单目摄像机和基于随机存取存储器(RAM)神经网络的方法实现人数统计。
在国内,清华大学、上海交通大学、华中科技大学、中科院自动化研究所、微软亚洲研究院等高校与科研院所也在目标跟踪领域进行了大量研究工作,在诸如人体特征部位跟踪、视觉监控、人数统计等方向取得了许多科研成果。
2 基于深度图像的行人目标检测与轮廓提取
在对Kinect采集到的图像进行预处理后,需要对行人目标的特征进行识别,将识别分割的区域作为行人目标的备选区域[2]。因此,需要对经过中值滤波、形态学预处理后的深度图像进行行人目标分割,分离出有用信息,并对识别出的连通域进行轮廓提取,作为行人目标的人体头部区域,便于后续对行人目标的跟踪与统计研究[3]。
2.1 自适应高斯混合模型背景建模
在基于自顶向下获取图像方式的人数统计系统中,视场中的背景随时间变化较少,属于固定场景的场合。对于无行人目标的静态场景,其具有的特性可以用统计模型进行表述,因此可以用多个高斯模型的加权混合模拟背景特性[4]。
2.1.1 标准高斯混合模型建立
利用深度图像进行人体头部区域的识别,实际的深度图像为灰度图,并且每个像素点的灰度值服从高斯分布,因此可以使用高斯模型进行背景像素点的建模统计,以实现前景区域和背景的分离[5]。
对于复杂的人流统计场景,往往单个高斯模型不能有效地实现背景建模,因此需要多个高斯模型来描述背景特征,称为高斯混合模型(GMM)。高斯混合模型通常使用M个(通常M取值为3~7)高斯模型的加权和表征背景图像中每个像素的多峰状态和变化特征,常用于复杂动态背景的建模。
高斯混合模型实现的大致过程如图1所示。
对传统的高斯混合模型,在采样间隔T内,在t时刻采集到的值设为xT={x(t),…,x(t-T)}。假设图像中的各像素点之间是独立分布(高斯分布)的,则在t时刻当前像素的概率如式(1)所示:
p(xT)=∑Mm=1ωmη(x;μm,∑m)(1)式(1)中,M代表高斯模型的个数,ωm表示第m个高斯分布的权重,0≤ωm<1并且ΣMm=1ωm=1。μm表示第m个高斯分布的均值;∑m表示第m个高斯分布的协方差矩阵且Σm=σ2mI,σ2m表示第m个高斯模型的方差。概率密度函数η(x;μm,∑m)可由式(2)表示:η(x;μm,∑m)=1(2π)D2∑m12e-12(x-μm)TΣ-1m(x-μm)(2)在模型参数更新时,一般使用EM算法,但这会导致较长的消耗时间。因此,模型参数更新时,利用像素值和每一个高斯模型函数进行比较,如式(3)所示。若每一个像素的灰度值与某一个高斯模型均值的绝对值处于2.5~3倍标准方差范围之内,则认为匹配成功。当存在多个匹配时,选取其中最好的一个或者选择第一个匹配的模型;若未成功匹配,则选取一个新的高斯分布来取代模型中权值ω最小的高斯分布。新的高斯分布要符合权重较小、均值为当前像素值且方差较大的要求[6]。 x(t)-μ(t-1)m≤βσ(t-1)m,β=2.5~3(3)得到满足式(3)条件的模型,说明匹配成功,则利用式(4)对各个高斯模型参数进行更新。
ω∧(t)m=(1-α)ω∧(t-1)m+αο(t)mμ∧(t)m=(1-α)μ∧(t-1)m+ρx(t)∑∧(t)m=(1-α)∑∧(t-1)m+ρ(x(t)-μ∧(t)m)(x(t)-μ∧(t)m)Tρ=αη(x;μ∧m,∑∧m)ο(t)m=1;match0;otherwise (4)式(4)中,α为学习率,1/α决定参数更新的速率。学习率α的值越大,说明背景模型的初始化和更新速率越快,适应场景环境变化的能力越强,但也容易引入部分噪声。α值一般选择0.001~0.1之间的一个值。进行参数更新后,虽然知道像素产生的最可能的高斯函数,还需要将其进行背景与前景的分类。基于ωm/σm的值将这M个高斯分布进行降序排序,值越大,意味着权重越大或者方差越低,从而增加了判断该像素是背景的概率。取出其中前B个高斯模型作为背景模型。B的计算如式(5)所示:
B=argminb(∑bm=1ωm>T)(5)式(5)中,T代表阈值常数。需要针对不同场景进行实验统计,对于选取阈值常数T,是基于所有视频帧中背景像素的比例一直都大于T的基准。同时,实际中若一个运动目标长时间在视场的历史帧中保持静止,则歸类为背景[7]。历史帧的选择为n=logT/log(1-α),例如取T=0.9,α=0.001时,105帧内运动目标静止,则会被归为背景。
2.1.2 改进的自适应高斯混合模型
标准高斯混合模型算法的鲁棒性在于模型匹配时不同情况下高斯分布的参数更新方式。但是由于对每个像素点选择的M个高斯分布是一个定值,而实际环境的背景模态分布数目并非相等。较稳定的像素点可能为单模态特征,变化较大的区域像素点则可能需要多个高斯分量进行建模。因此,为了针对不同输入场景动态地选择高斯分量的个数,则使用自适应的高斯混合模型(Adaptive GMM,AGMM)。在较简单的场景下,可以只选取一个最为重要、权重最大的高斯分量进行描述,以节省后期更新背景的时间,提高算法运行速度[8]。因此,自适应高斯混合模型建模在GMM的更新方程上对权值引入了一个先验密度分布,并且先验函数为狄利克雷(dirichlet)函数。由前文分析可知,前景模型和背景模型的分类和权重ωm值的大小直接关联,根据权重ωm的值来决定第m个高斯模型具有的数据多少,它可以表征第m个高斯模型的样本概率。假设有t个数据样本,且它们来自其中一个GMM模型,同时有许多样本来自其中的M个部分。
nm=∑ti=1ο(i)m(6)定义似然函数为L=∏Mm=1ωnmm。由上述分析可知权重之和为1,则引入拉格朗日乘子λ,可得如式(7)所示的最大似然估计:
ω∧m(logL+λ(∑Mm=1ω∧m-1))=0(7)当消除λ时,得到:
ω∧(t)m=nmt=1t∑ti=1ο(i)m(8)将t采样时刻的估计记为ω∧(t)m,它可以递归的形式被改变:
ω∧(t)m=ω∧(t-1)m+1/t(ο(t)m-ω∧(t-1)m)(9)由于新的采样点影响固定,说明更新更加依赖新样本的影响,并且旧样本的影响以指数形式衰减。
在自适应高斯混合模型的权值更新方程中,引入狄利克雷先验函数Ρ=∏Mm=1ωcmm,系数cm代表利用最大后验概率(MAP)方法得到的属于先验分布的样本数目。使用cm=-c,负的先验分布意味着只要有足够的分布属于该模型,则认同该模型的存在。因此,加入狄利克雷先验估计后的似然方程如式(10)所示:ω∧m(logL+logP+λ(∑Mm=1ω∧m-1))=0(10)因此可以得到:
ω∧(t)m=1K(∑ti=1ο(i)m-c)(11)其中,K=∑Mm=1(∑ti=1ο(t)m-c)=t-Mc,所以:
ω∧(t)m=1/t∑ti=1ο(t)m-c/t1-Mc/t(12)c/t表示先验估计产生的偏差,在允许存在的偏差范围内,使偏差固定为c/t=cT=c/T。因此,得到权重的更新方程为:ω∧(t)m=ω∧(t-1)m+1/t(ο(t)m1-McT)-1/tcT1-McT(13)由于使用较少的高斯模型,即M的值相对较小。同时,上述讨论的偏差cT也较小,则1-McT≈1。因此,权重更新方程可简化成式(14)的形式:
ω∧(t)m=ω∧(t-1)m+α(ο(t)m-ω∧ (t-1)m)-αcT(14)综上所述,引入狄利克雷先验函数和最大似然估计后,减小了权值大小。因此,既可以消除不符合分类条件的高斯模型,又可以防止权重为负值的高斯模型,能够实现高斯模型分类个数的自适应选取。对于给定的α=1/T,在一个高斯模型中至少需要c=0.01×T个采样数据,因此cT=0.01。同时,对于α的选择,由于α越大,背景更新越快。结合本文的背景场景特点,更新率α如式(15)所示。在初始的背景建模时,更新率α较大,且随着帧数增加,α值更新减小。当帧数达到设定值N时,将更新率固定为0.001~0.1之间的一个值。
α=1t+1,t
f(x,y)=αT(x,y)+β(16)式(16)中,α=255/4 096=0.062 3,β的值为0,不进行偏移。
进行缩放变换后,对深度图像进行改进的混合高斯模型建模。其中,α取0.000 1。对当前的数据帧而言,建模得到如图3(a)所示的前景掩膜。然后根据分离的前景和背景,利用式(17)进行阈值二值化处理,得到如图3(b)所示的深度信息的二值化图。与原图相与运算得到的前景数据如图3(c)所示,由于建模过程产生噪声,因此再对前景数据进行闭运算操作,滤除噪点,得到最终的人体头部区域前景如图3(d)所示。
f(x,y)=0,g(x,y)≥T255,g(x,y)
利用自适应高斯混合模型得到的前景区域进行连通域提取。为了判别行人头部区域,需要利用人体的头部特征将前景中的轮廓提取出来用于后续的人体头部区域的条件约束,获得头部区域。本文利用Freeman链码(亦称为八方向码)方法对连通域的轮廓进行提取[9]。本文使用如图4(a)所示的1~8进行Freeman链码矢量编码,以利于后续求取轮廓周长和区域内面积。获取轮廓边缘的步骤如下:(1)在具有封闭轮廓的二值图像中,按行搜索的形式寻找白色像素点。当搜索到第一个白色像素点时,记录该点坐标,记为(x0,y0)。(2)以上述获得的白色像素点作为搜索点,首先从第4个方向(即180°方向)开始以逆时针方向判断相邻像素点是否为白色像素点。若不是白素像素点,则以逆时针方向选取下一个方向进行判断;若为白色像素点,记录该像素点坐标,记为(x1,y1),记(x0,y0)至(x1,y1)的Freeman码矢量为V0,并定义该矢量为(x1,y1)的当前矢量为(x0,y0)的次矢量。(3)由于人头区域大多是比较规则的圆形或椭圆形,因此以(x1,y1)为中心点,并从(V0-1)的方向开始继续逆时针搜索(值为0则从矢量8方向开始搜索)。若相邻像素为白色像素点,记为(x2,y2),从而得到(x2,y2)的当前矢量和(x1,y1)的次矢量。(4)重复(1)~(3)的步骤,继续搜索属于轮廓的点,直至寻找到初始点(x0,y0),形成封闭轮廓。
通过以上步骤,可获得前景中所有的封闭轮廓,而且所有轮廓是沿着逆时针方向获得的,因此得到封闭轮廓内的像素都位于轮廓左侧。
图5(b)为分离得出的连通区域作为人体头部区域的备选区域,利用Freeman链码得到右上方区域的轮廓点为:(204, 103);(204, 105);(203, 106);(198, 106);(198, 107);(197, 108);(196, 108);(195, 109);(194,109);(193, 110);(193, 111);(192, 112);(192, 113);(191, 114);(191, 115);(190, 116);(190, 125);(188, 127);……;(224, 113);(215, 104);(214, 104);(213,103),共74个轮廓点。可以看出,轮廓点按逆时针方向获取,且首尾相连,得到一个封闭区域。同样,左下角得到的区域点共有96个轮廓点。
3 结语
本文根据自适应高斯混合模型的背景建模算法和Freeman链码方式获得了连通区域的轮廓,并將其作为人体头部的备选区域。根据前景提取的特征来看,行人头部区域的特征基本上不发生变化,且遮挡较少。因此,可以选择头部区域的几何特征作为约束条件。下一步将对分割获得的区域轮廓进行分析,根据轮廓和轮廓包围区域的几何特征约束,判定其是否为行人目标,并对行人目标进行跟踪分析。
参考文献:
[1] CHEN T H. An automatic bi-directional passing-people counting method based on color image processing[C]. 2003 International Carnahan Conference on Security Technology, Proceedings,2003:200-207.
[2] ZHU L, WONG K H. Human tracking and counting using the kinect range sensor based on adaboost and kalman filter[M].Advances in Visual Computing. 2013:582-591.
[3] 周颖. 深度图像的获取及其处理[D].西安:西安电子科技大学,2008.
[4] 尹章芹, 顾国华, 陈钱,等. 三维深度图像在自动客流计数系统中的应用[J].中国激光,2014(6):192-198.
[5] BROSTOW G J, CIPOLLA R. Unsupervised Bayesian detection of independent motion in crowds[C]. IEEE Computer Society Conference on Computer Vision & Pattern Recognition,2006:594-601.
[6] WANG N, GONG X, LIU J. A new depth descriptor for pedestrian detection in RGB-D images[C].International Conference on Pattern Recognition,2012:3688-3691.
[7] 曹其春. 融合深度信息的运动物体检测算法研究[D]. 北京: 北方工业大学, 2015.
[8] 焦宾, 吕霞付, 陈勇,等. 一种改进的自适应高斯混合模型实时运动目标检测算法[J]. 计算机应用研究, 2013, 30(11):3518-3520.
[9] 牛胜石. 基于Ada Boost和SVM的人头检测[D].武汉:中南民族大学, 2010.
- 河北地区旅游开发中的文化遗失现象及对策
- 文化旅游度假理念推动下的酒店管理与形象塑造
- 旅游APP对大学生旅游购买决策的影响
- 四川旅游扶贫效应动态分析
- 生态旅游产品的设计与开发
- 张家口生态旅游资源的法律保护对策研究
- 震后民族地区女性就业问题研究
- 鸟类观察心得
- 如何培养中职市场营销专业学生的营销意识
- 浅析中瑞饮食文化差异
- 拿破仑与巴黎凯旋门
- 龙猫—天生呆萌小精灵
- 美国的华裔移民和德意志移民之比较研究
- 浅析部分馆藏的价值
- 纳西音乐的类别
- 网络直播平台发展探究
- 云南人口老龄化问题的特征及成因分析
- 老人社区+医疗景观的研究
- 品中悟
- 云南省人口老龄化发展及其对经济的影响分析
- 探究不动产统一登记带来的机遇和挑战
- 浅析地质博物馆的互动性展示设计
- SMW工法在深基坑工程中的施工流程及质量控制
- 城博物馆藏汉画像泗水取鼎图解读
- 基于RS与GIS的毕节试验区LUCC及区域经济响应特征分析
- deciduously
- deciduousness
- deciduousnesses
- decimal
- decimal point
- decimal points
- decimals
- decimal²
- decimal¹
- decimate
- decimated
- decimates
- decimating
- decimation
- decimations
- decimator
- decimators
- decimeter
- decimetre
- decimetres
- decimetric
- decipher
- decipherabilities
- decipherability
- deciphered
- 过务
- 过动
- 过劳
- 过劳死
- 过化存神
- 过十分富裕的生活
- 过午
- 过半
- 过厅
- 过厅羊
- 过厚
- 过原始人的生活
- 过原始或隐居生活
- 过原始朴素的生活
- 过原始艰苦的生活
- 过去
- 过去、现在、将来
- 过去不久到现在的一段时间
- 过去写的文章
- 过去喜欢过的人和现在受到宠爱的人
- 过去多年
- 过去很久的事
- 过去担任的职务
- 过去时
- 过去有老交情