沈炜域
摘 要:有别于RNN和CNN,动态路由与注意力机制为捕捉文本序列的长程和局部依赖关系提供了新思路。为更好地进行文本编码,尽可能多地保留文本特征、增加特征多样性,基于动态路由与注意力机制的思想,整合胶囊网络和自注意力网络的语言信息特征抽取能力,构建一种深度网络模型CapSA,并通过3种不同领域的文本分类实验验证模型效果。实验结果显示,相较于几种基于RNN或CNN的模型,基于CapSA模型的文本分类模型取得了更高的F1值,表明该模型具有更好的文本建模能力。
关键词:胶囊网络;动态路由;注意力机制;文本建模
DOI:10. 11907/rjdk. 182730
中图分类号:TP301文献标识码:A文章编号:1672-7800(2019)001-0056-05
Abstract: Compared with RNN and CNN, dynamic routing and attention mechanism provide some new ways to capture the long-term and local dependencies. Based on the ideas of dynamic routing and self-attention, this paper proposed CapSA(Capsule-Self-Attention), a deep neural network, to better model text sequences, retain features as many as possible and increase the diversity of features. This paper verified the effectiveness of the proposed model by text classification experiments in different fields. The results show that the text classification model based on CapSA gained higher F1-score than several strong models based on RNN and CNN, indicating that CapSA has better text modeling performance.
0 引言
在将文本转化为向量表示的过程中需对文章或句子建模,这是许多自然语言处理的重要步骤。好的文本建模不仅需提取足够充分且最有类别代表性的文本特征,还应能编码上下文的依赖关系。传统自然语言处理中的文本建模方式如n-gram,需占用大量内存空间。而近来神经网络模型被广泛应用于文本表示学习。这些方法基本上以词嵌入表示作为输入,利用RNN[1]或CNN[2]产生上下文有关的文本表示,最后通过一定的操作,如池化等,将变长文本转化为定长向量。从2017年开始,许多工作使用自注意力机制[3-4]学习文本表示。自注意力机制可以不考虑词之间的距离、直接计算依赖关系,与RNN、CNN等配合使用,学习一个句子的内部结构。自注意力网络甚至可脱离CNN和RNN,单独作为一个网络层,出色地解决NLP领域的任务。
为在文本建模过程中保留更多文本的局部依赖关系、特征等变性及词之间、特征与词之间的相对信息,本文借鉴动态路由[5]与注意力机制的思想,构建一种深度网络模型CapSA对文本进行建模。该网络主要包括多尺寸多层卷积的胶囊网络与自注意力网络,两部分网络同时对文本序列进行编码。为验证模型有效性,本文在文本分类任务中使用该模型进行文本建模,并在3种数据集上对比该网络模型和多种基于CNN或RNN模型的分类效果。
1 相关研究
1.1 表示学习
表示学习是人工智能和自然语言处理中十分重要的任务。主流文本表示学习方法可分为4种类型:①词袋模型。该模型不考虑文本词序,比较成功的应用有深度平均网络[6]、自编码器[7],如Mikolov等提出的fastText[8]可在10min内完成10亿级词汇量的文本分类任务;② 序列表示模型。该模型通过CNN[9-10]或RNN捕捉词序特征,但没有利用文本结构特征。LeCun等提出一种29层的极深卷积神经网络[11]以捕捉更长程的信息;③结构表示模型。该模型使用预先获得的语法树构建文本结构表示,如典型的樹结构LSTM[12-13];④注意力模型。该模型基于注意力机制计算词或句子的注意力得分[14-15],以获得文本表示。
1.2 动态路由与胶囊网络
以动态路由[5]代替池化的胶囊网络能够适应低层特征的状态参数变化,其建模思想是以向量形式将特征状态封装成“胶囊”,将其输出向量的模长作为特征存在的概率,将向量方向作为实例参数。所以,当抽取的特征在实例参数上发生变化时,存在概率仍然保持不变、达到特征等变性。在胶囊网络中,子胶囊要对父胶囊的实例参数进行预测。当多个预测相近时,对应的高层胶囊被激活。同时,作为一种耦合效应,当一些子胶囊同意存在一个高层实体时,对应于该实体的父胶囊会向低级别胶囊发送反馈,如果确实存在高层实体,同意该实体存在的子胶囊对该高层实体预测将增大。如此循环若干次后,某一个高层实体存在的概率将明显高于其它高层实体。
1.3 注意力机制
作为一种高效的可并行化序列编码方式,注意力机制与深度神经网络结合被广泛应用于自然语言处理的多个任务中,并取得了良好的性能效果。如Bengio 等[16]使用该机制提升机器翻译对齐效果和翻译准确性。李航等[17]在对话生成中利用该机制生成更有意义的回复。随着注意力机制的深入研究,各种注意力被提出。自注意力是一种特殊的注意力机制,在该机制下,序列中的每一个单元和该序列中的其它单元进行注意力计算,其特点在于无视词间距离而直接计算其依赖关系,能够学习一个句子的内部结构,且对于增加计算的并行性也有直接帮助作用。Google提出的多头注意力[18]通过多次计算捕获不同子空间的相关信息。张成奇等[19]提出同时使用两种注意力机制对句子进行建模,在自然语言推理、语义关系分析等任务中也取得了较好效果。
2 CapSA网络模型
一方面,多层多尺寸的卷积提升模型对输入样本的特征提取能力,且动态路由机制确保在特征图转换成文本表示时保持特征等变性;另一方面,自注意力机制能够在文本建模过程中引入词或短语在文本中的重要程度及词—词间、词—特征间的相互关系。因此,本文基于动态路由与自注意力机制的思想,结合深度卷积胶囊网络和双序自注意力网络,构建一种深度神经网络文本表示模型CapSA。
2.1 深度卷積胶囊网络
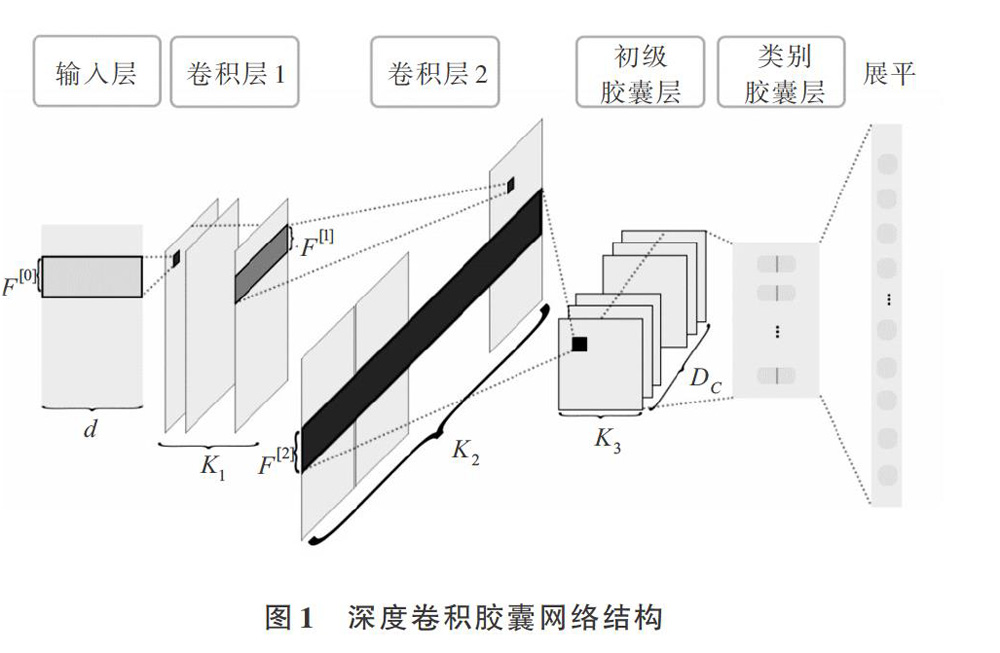
为更好地抽取特征,本文使用多个不同尺寸的卷积核提取文本的N-gram特征,如图1所示。
该模型在第一层卷积层使用K1种不同尺寸的卷积核,每种大小各N1个卷积核,每个卷积核的尺寸为 ([F[0]i,]d) ,[F[0]i]是一个卷积核一次能覆盖的词个数。第二层卷积操作与第一层卷积层基本一致,使用高度为[F[1]i]的多个卷积核对第一层卷积层的输出[A[1]]进行卷积操作,将输出各尺寸的卷积核抽取的特征拼接为一个(L2,K2)的特征映射[A[2]]。
两个卷积层之后是第一层胶囊层,用于将标量输出转换成向量输出。为得到固定维度的胶囊,使Dc个不同尺寸的卷积核配合Dc种填充方案在[A[2]]上进行卷积操作,获得相同维度的特征映射。如图1所示,[F2i]表示其中一种尺寸的卷积核高度,每种尺寸的卷积核有K3个,通过卷积后得到L3×K3个Dc维向量,每个向量表征对应特征的显著程度。紧接着对每个向量使用压缩函数进行非线性变换,压缩函数将模长限制在0~1之间。将每个向量表示为[sj],非线性变换后向量方向保持不变。
初级胶囊层之后是类别胶囊层、该层设置与类别个数相同的胶囊数C。以路由迭代的方式从初级胶囊层获得输入。模型中的路由迭代过程在初级胶囊层和类别胶囊层之间进行,使用初级胶囊激活值计算类别胶囊激活值。首先通过一个矩阵变换获得初级胶囊对类别胶囊实例参数预测。对于每一个类别胶囊j, 第一步计算由低层特征预测出高层特征实例参数[uj|i](预测向量),即[uj|i=u[L]iWij] ,其中[u[L]i]表示样本中的一个激活值(低层特征),变换矩阵[Wij]([W∈?C×Dc×Dp])是待训练的参数,两者进行矩阵乘法;第二步计算j 的输出向量[sj],其由所有初级胶囊对类别胶囊j预测向量加权求和得到,即[sj=ic(r)ijuj|i],其中标量[cij]是每个子胶囊输出到各个父胶囊的权重系数,其由路由迭代过程决定;第三步计算胶囊j的激活值[vj]。使用压缩函数对j 的输出向量进行压缩。类别胶囊的激活值将对初级胶囊进行反馈。初级胶囊i对类别胶囊j的预测向量与胶囊j的激活向量相似程度越高,预测向量[uj|i]的权重越大。本文采用点积衡量其相似程度。假设共迭代T轮路由算法,整个路由迭代算法为:
其中,为保证低层胶囊对高层实体存在的概率预测之和为1,使用Routing SoftMax作归一化,其计算公式为:
2.2 自注意力网络
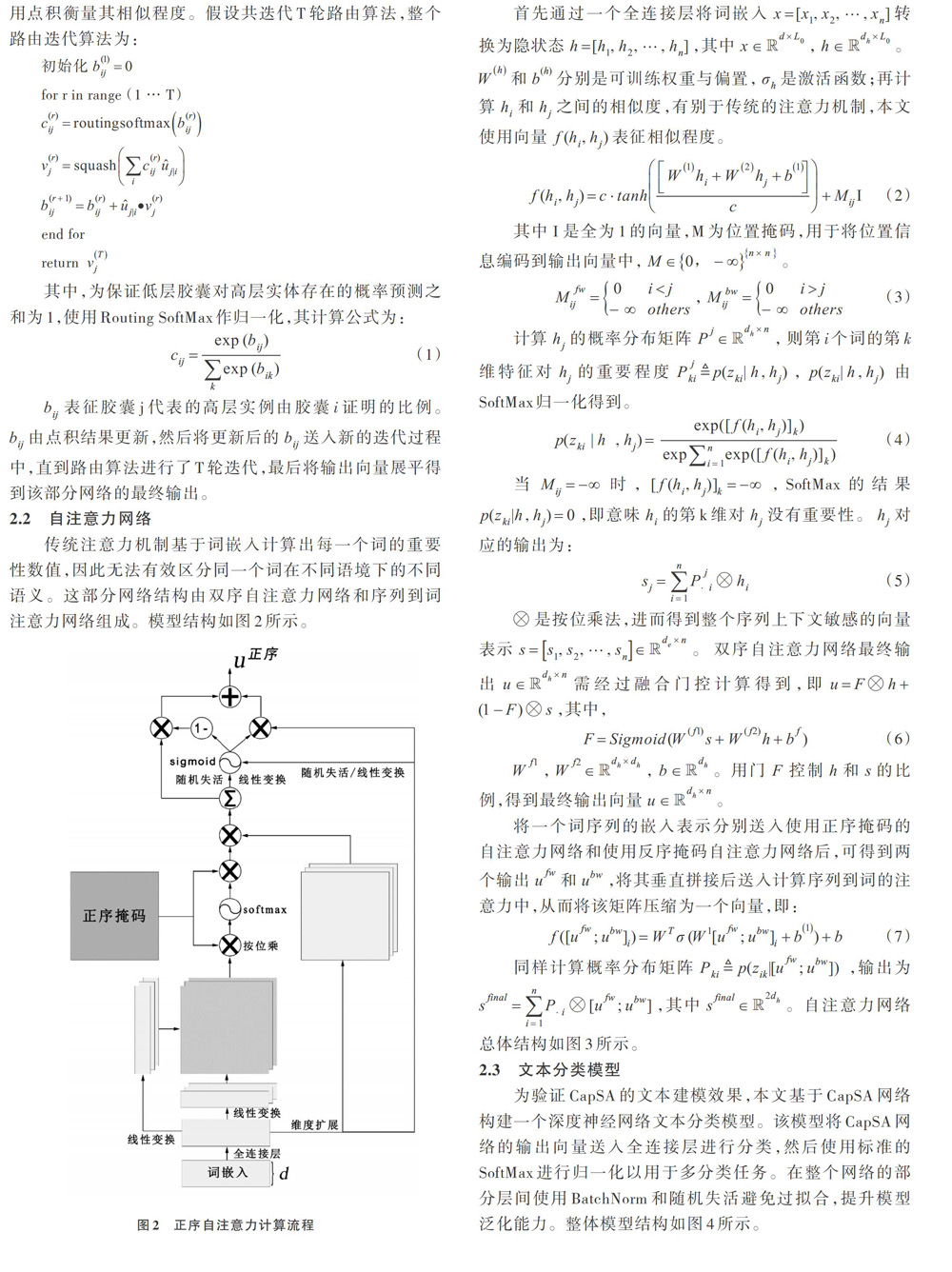
传统注意力机制基于词嵌入计算出每一个词的重要性数值,因此无法有效区分同一个词在不同语境下的不同语义。这部分网络结构由双序自注意力网络和序列到词注意力网络组成。模型结构如图2所示。
首先通过一个全连接层将词嵌入[x=[x1,x2,?,xn]]转换为隐状态[h=[h1,h2,?,hn]],其中[x∈?d×L0],[h∈?dh×L0]。[Wh]和[b(h)]分别是可训练权重与偏置,[σh]是激活函数;再计算[hi]和[hj]之间的相似度,有别于传统的注意力机制,本文使用向量[f(hi,hj)]表征相似程度。
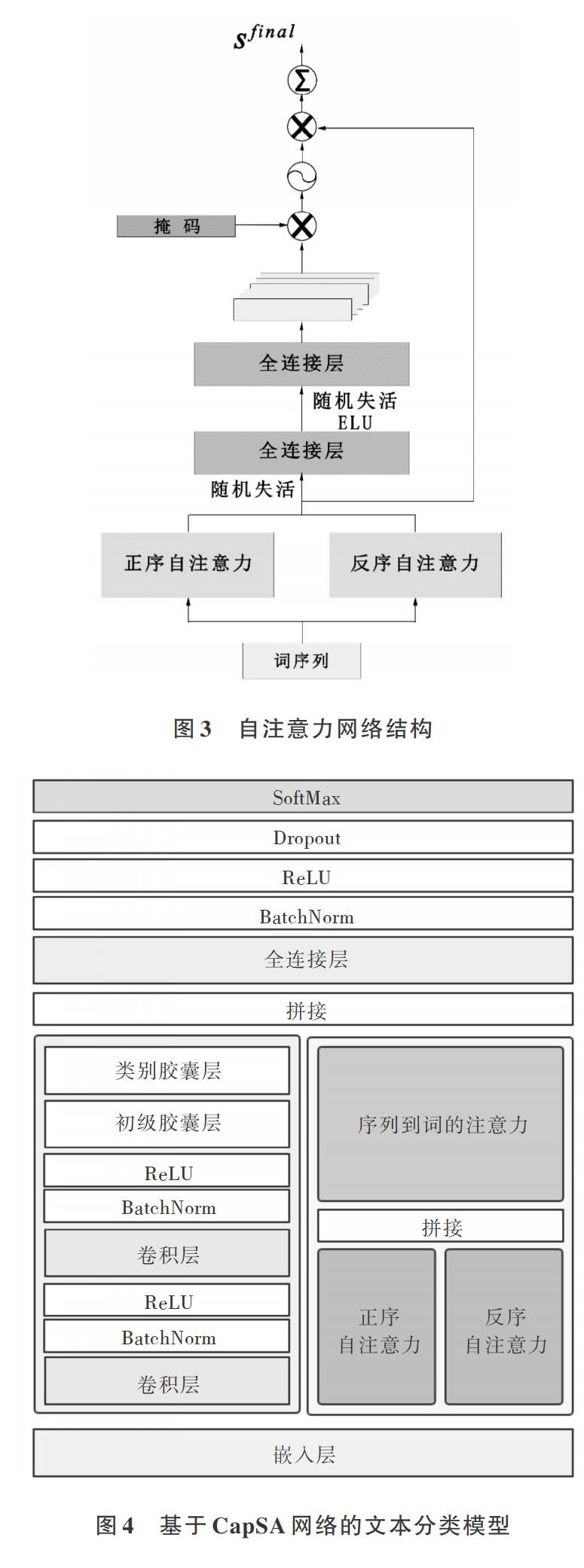
2.3 文本分类模型
为验证CapSA的文本建模效果,本文基于CapSA网络构建一个深度神经网络文本分类模型。该模型将CapSA网络的输出向量送入全连接层进行分类,然后使用标准的SoftMax进行归一化以用于多分类任务。在整个网络的部分层间使用BatchNorm和随机失活避免过拟合,提升模型泛化能力。整体模型结构如图4所示。
3 实验
3.1 实验数据
模型在3种不同领域、不同文本长度的数据集上训练与预测,其中包含情感倾向(Review Sentiment,共2个类别,文本平均长度约100个字符)[20]、作者识别(EUPT),共4个类别,文本平均长度约400个字符及标题分类(NLPCC Headlines)[21],共18个类别,文本平均长度约20个字符。
3.2 实现细节与基线模型
实验在Ubuntu16.04、Pytorch0.4上开展。实验中词嵌入由Word2vec在中文维基百科迭代30轮得到,词向量维度为300维。实验使用Adam作为优化算法更新网络权重。在深度卷积胶囊网络部分中,将Dc设为8,Dp设为16,路由迭代轮数T∈{1,2,3,4,5},针对不同数据集调整具体的迭代轮数。在自注意力网络中,将c设为5,使用ELU[22]作为激活函数,使用交叉熵作为损失函数。
3.3 实验结果
实验使用了5种基于CNN或RNN的模型和1种胶囊网络模型,在3个数据集上对测试分类结果的宏平均F1值进行对比。实验结果如表1所示。其中MultiCNN+maxpool是两层多卷积结合最大池化模型,Multilayer Bi-LSTM是一个两层双向长短期记忆的循环神经网络模型,Bi-LSTM+concate参照文献[23]中RCNN模型,可将双向LSTM隐藏状态与词向量拼接后送入一个全连接层中,CapsNet是参照文献[5]实现的单层卷积胶囊网络。
3.4 参数分析
3.4.1 路由迭代轮数
在实验中发现,由于动态路由的迭代(routing iteration)过程,胶囊网络相较于其它网络计算时间更长。为探究路由过程迭代次数对模型性能的影响,实验仅调整路由迭代轮数,在Headlines和Review Sentiment数据集上进行测试。 固定学习率10-4迭代5轮数据(epoch)后,记录录训练时间(Time)、分类结果的F1值及正确率(Acc.)。实验在单机单显卡(nVidia GTX1080Ti)上进行。F1与正确率如表2所示,花费的训练时间如表3所示。
表2與表3的统计结果表明,在限制数据迭代轮数的情况下,基于CapSA的文本分类模型在2轮路由迭代的情况下能得到较好的分类效果,而增加路由迭代轮数并没有在有限的数据迭代轮数训练后提升分类效果。因此推测更多的路由迭代轮数需更多的数据迭代轮数才可让模型收敛到理想状态,但这带来了更大的计算代价。
3.4.2 压缩函数
本文在深度卷积胶囊网络模型上试验了4种压缩方案。4种压缩方案在Headlines和Review Sentiment数据集上的训练损失变化情况如图5所示。
4 结语
本文探索了动态路由与自注意力机制在文本建模中的应用,提出CapSA深度网络模型。该模型一方面利用动态路由保证样本特征的等变性,另一方面通过自注意力网络缩短远距离依赖特征之间的距离,增加特征多样性和模型鲁棒性。CapSA深度网络模型也可以应用于文本蕴涵、语义匹配等其它类型的自然语言处理任务中。本文通过多次实验对比了动态路由迭代轮数及向量压缩方案对模型效果的影响,发现模型收敛对动态路由迭代轮数十分敏感,使用合适的向量压缩方案也会影响效果。下一步工作是增加模型中不同网络间的耦合程度,尝试该模型在阅读理解、机器翻译等序列到序列任务中的应用。
参考文献:
[1] CHUNG J,GULCEHRE C,BENGIO Y,et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[J/OL]. ArXiv Preprint ArXiv:1412.3555. https://arxiv.org/abs/1412.3555.
[2] KIM, Y. Convolutional neural networks for sentence classification[C]. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 2014: 1746-1751.
[3] LIN Z, FENG M, BENGIO Y, et al. A structured self-attentive sentence embedding[J/OL]. ArXiv Preprint ArXiv:1703.03130. https://arxiv.org/abs/1703.03130.
[4] YANG Z, YANG D, DYER C, et al. Hierarchical attention networks for document classification[C]. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2016.
[5] SABOUR S, FROSST N, HINTON G E. Dynamic routing between capsules[C]. Advances in Neural Information Processing Systems, 2017:1-11.
[6] IYYER M, MANJUNATHA V, BOYD-GRABER J, et al. Deep unordered composition rivals syntactic methods for text classification[C]. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, 2015:1681-1691.
[7] LIU B, HUANG M, SUN J, et al. Incorporating domain and sentiment supervision in representation learning for domain adaptation[C]. Proceedings of the 24th International Conference on Artificial Intelligence, 2015:1277-1284.
[8] JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of tricks for efficient text classification[C]. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, 2017:1-5.
[9] BLUNSOM P, GREFENSTETTE E, KALCHBRENNER N. A convolutional neural network for modelling sentences[C]. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 2014:1-11.
[10] LEI T, BARZILAY R, JAAKKOLA T. Molding CNNs for text: non-linear, non-consecutive convolutions[J]. Indiana University Mathematics Journal, 2015, 58(3): 1151-1186.
[11] CONNEAU A, SCHWENK H, BARRAULT L, et al. Very deep convolutional networks for text classification[C]. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, 2017:1-10.
[12] ZHU X, SOBIHANI P, GUO H. Long short-term memory over recursive structures[C]. ICML'15 Proceedings of the 32nd International Conference on International Conference on Machine Learning, 2015:1604-1612.
[13] TAI K S, SOCHER R, MANNING C D. Improved semantic representations from tree-structured long short-term memory networks[C]. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics, 2015:1577-1586.
[14] YANG Z, YANG D, DYER C, et al. Hierarchical attention networks for document classification[C]. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2016:1-11.
[15] ZHOU X, WAN X, XIAO J. Attention-based LSTM network for cross-lingual sentiment classification[C]. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2016:1-23.
[16] BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[J/OL]. ArXiv Preprint ArXiv: 1409.0473. https://arxiv.org/abs/1409.0473.
[17] SHANG L, LU Z, LI H. Neural responding machine for short-text conversation[C]. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, 2015.
[18] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. Advances in Neural Information Processing Systems, 2017:1-15.
[19] SHEN T, ZHOU T, LONG G, et al. DiSAN: Directional self-attention network for RNN/CNN-free language understanding[C]. The 32nd AAAI Conference on Artificial Intelligence, 2018:1-10.
[20] JUN L I, SUN M. Experimental study on sentiment classification of chinese review using machine learning techniques[C]. 2007 IEEE international conference on natural language processing and knowledge engineering, 2007:393-400.
[21] QIU X, GONG J, HUANG X. Overview of the NLPCC 2017 shared task: Chinese news headline categorization [J/OL]. Computer Science:2018,10619. https://link.springer.com/chapter/10.1007/978- 3-319-73618-1_85.
[22] CLEVERT D A, UNTERTHINER T, HOCHREITER S. Fast and accurate deep network learning by exponential linear units(ELUs)[J]. ArXiv Preprint ArXiv:1511.07289. https://arxiv.org/abs/1511.07289.
[23] LAI, S, XU, et.al. Recurrent convolutional neural networks for text classification[C]. Proceedings of the 29th AAAI Conference on Artificial Intelligence, 2015:2267-2273.
(責任编辑:江 艳)
- 怎样搞好边远民族地区小学教育教学
- 加强中小学书法教学的意义与策略
- 初中科学教材与教学现状研究
- 用爱心浇灌后进生的心灵
- 林业营造林技术存在的问题及改进措施
- 以“激情”与“爱心”促学困生转化
- 初中数学创新能力的培养的几点做法和体会
- 班级管理需要“新鲜血液”
- 如何做一名优秀的化学教师
- 沟通,从心开始
- 浅谈如何构建有生命力的班集体
- 初中英语学困生的成因及转化策略
- 当代人才培养对教师师德要求
- 如何做好新时期的高中语文教学工作
- 浅谈学校图书馆古籍文献的保护与管理
- 小学德育管理存在的问题及对策研究
- 关于弱儿童教育方法的研究
- 克服学习障碍 突破学困瓶颈
- 音乐美育与大学生综合素质培养研究
- 浅论几种修辞手法的幽默效果
- 学生自我命题评价促进阅读教学模式探微
- 中职旅游管理专业体验式教学的应用
- 现代日语中并存自动词的形态及意义特征
- 普惠金融视角下农村信贷问题研究及策略分析
- 幼儿园健康主题教育活动探析
- more right minded
- more round the clock
- more round trip
- more run down
- more run in
- more run of the mill
- more run through
- reteaches
- reteaching
- reteam
- reteamed
- reteaming
- reteams
- retelegraph
- retelegraphed
- retelegraphing
- retelegraphs
- retelephone
- retelephoned
- retelephones
- retelephoning
- retelevise
- retelevised
- retelevises
- retelevising
- 我跑不掉,你也飞不了
- 我身
- 我辈
- 我辈中人
- 我辈情钟
- 我郎
- 我醉欲眠
- 我马虺隤
- 我黼子佩
- 戒
- 戒世
- 戒严
- 戒令
- 戒儆
- 戒刀
- 戒劝
- 戒厉
- 戒口
- 戒在
- 戒坛
- 戒备
- 戒备、警惕之心
- 戒备不虞
- 戒备严密
- 戒备和搜捕