殷复莲 徐荣阁 刘志心 冀美琪

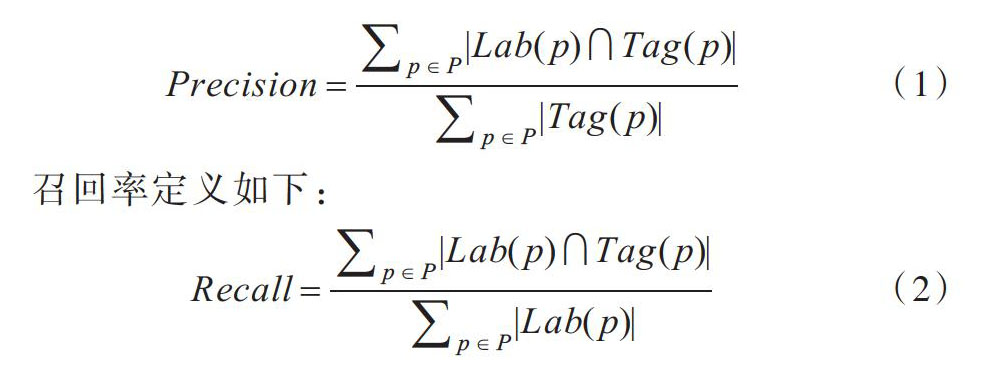
摘 要:針对影视节目标签手动采集费时费力,以及传统树状标签体系信息冗余且不全面等问题,提出一种标签自动获取技术。通过数据爬取技术采集与节目相关的互联网原始数据,然后通过文本分析、同义匹配、数据库匹配等技术进行数据分析与挖掘,最终实现对扁平化节目标签的获取。实验结果表明,在选取8~10个标签时,该算法准确率为84.3%~ 92.4%,召回率为53.4%~ 63.1%,说明该算法获取的标签能够很好地对影视节目进行描述。
关键词:扁平化标签;标签自动获取;Web自动信息采集;标签库匹配
DOI:10. 11907/rjdk. 182739 开放科学(资源服务)标识码(OSID):
中图分类号:TP319文献标识码:A 文章编号:1672-7800(2019)007-0150-04
Research on the Acquisition Technology of Film and Television Program Flat Tags
YIN Fu-lian,XU Ronge-ge,LIU Zhi-xin,JI Mei-qi
(School of Information and Communication Engineering, Communication University of China, Beijing 100024, China)
Abstract: This paper proposes an automatic tag acquisition technology for the which is time-consuming and labor-intensive manual collection of film and television program tags and the information redundancy and incompleteness of the traditional tree tag system. Our research collects the original Internet data related to the program through data crawling technology, and then analyzes and mines the data through text analysis, synonym matching, database matching and other technologies. Finally we achieve the acquisition of flat program tags. The experimental results show that the accuracy of this algorithm is 84.3%~92.4% when 8-10 labels are selected, and the recall rate is 53.4%~63.1%. This proves that the label obtained by the algorithm in this paper can describe a program well.
Key Words: flattened tag; automatic tag acquisition; Web automatic information collection; tag library matching
基金项目:国家自然科学基金项目(61801441);国家级大学生创新创业训练计划项目(JG18110205)
作者简介:殷复莲(1982-),女,博士,中国传媒大学信息与通信工程学院副教授、硕士生导师,研究方向为大数据、数据分析与挖掘技术;徐荣阁(1996-),男,中国传媒大学信息与通信工程学院学生,研究方向为数字媒体技术;刘志心(1996-),女,中国传媒大学信息与通信工程学院学生,研究方向为数字媒体技术;冀美琪(1998-),女,中国传媒大学信息与通信工程学院学生,研究方向为数字媒体技术。
0 引言
如今随着大众审美观的不断变化,涌现出大量新类型与题材的影视节目。与此同时,人们的需求也变得越来越个性化,因此很多节目类型不能再被简单归为某一类,而往往是多种形式的杂糅和变异。对节目进行全方位的信息采集与分析才能够更加准确、完整地描述一个节目,使观众可以更直观地进行选择,同时也能让节目发布方对节目有更加全面的认识,从而方便管理与运营。
近年来,互联网的迅速发展致使数据规模不断扩大,人们越来越依赖互联网获取信息,因此Web数据挖掘、信息采集和管理技术也得到了快速发展[1-2]。Web信息采集通常分为基于整个Web的信息采集、增量式Web信息采集、基于主题的Web信息采集等类别[3-5]。目前,国内相关研究主要集中在以下方面:面向主题的Web信息采集、个性化Web信息采集、分布式Web信息采集、基于元搜索的Web信息采集与多技术结合的Web信息采集[6]。国外则主要是发展基于全采集策略、基于选择性采集策略与基于联合采集策略的项目等[7]。其中,信息采集是指采集指定网站中的特定信息,通过模拟用户正常浏览行为并设置一定规则,从而获取Web页面指定信息[8]。其采集的最终结果不再是页面,而是深入到站点或页面内部,获取信息并保存到用户指定的数据库中[9-11]。信息自动采集既能节省时间,又能得到相对准确的结果,因此很多学者针对该技术在各领域的应用进行了研究[12-13]。如在新闻自动采集方面,为了保证新闻发布的时效性,张一睿[14] 、戚扬[15]提出通过综合利用动态服务器页面(Active Server Pages,ASP)、Java服务器页面(JavaServer Pages,JSP)等技术对用户指定网站区域下的Web新闻网页进行自动抓取,经解析、消重、分类处理后保存到新闻网站数据库中,即可24小时自动采集并发布新闻;马凯[16]采用模块化技术构建一种特定领域的Web信息集成系统,通过用户提供的关键词,结合人工筛选进行关键词扩展,对全网相关新闻、微博数据进行采集与抽取。针对小企业的信息采集问题,赵红艳[17]提出利用自动信息采集系统从链接地址页面中提取目标网页URL地址与相应企业名称,并从URL地址对应的详细信息页面中提取具体企业信息。在舆情采集、网络爬虫方面,国内如周剑[18]、汤露阳[19]、李晓伟[20]应用自动采集技术进行网络爬虫、数据融合与文本情感分析等,实现了面向Web舆情评价信息的采集与分析系统;王仕艳[21]、熊畅[22]采用的数据采集技术主要是从Web上获取网站网页,通过既定规则自动抓取整个网页信息,并将其保存在文档中,同时将文档中的信息提取出来。国外研究则侧重于高性能Web爬虫程序的体系结构与实现、协作Web爬虫、深层Web爬虫、多媒体内容爬虫以及Web爬虫研究未来方向5个主题[23]。
总体上看,Web信息采集技术正逐渐向高性能、专业化、智能化、个性化方向发展。但由于网络信息资源的迅猛增长,现有技术仍存在一些待改进之处,比如信息采集需要更加个性化,在多个平台采集时需要进行网页预处理,以达到网页去重的效果等。
本文在以上技术基础上进行创新,将自动采集技术应用于影视节目标签获取。与已有技术不同的是,本文在对不同平台进行信息采集时,没有使用保存整个网页信息的方法,而是采用一定规则提取所需内容,从而提高了采集效率。同时,本文采集的节目信息不是由单一平台产生的,而是源自很多不同的互联网平台。本次研究还利用中文近义词匹配技术,并采用课题组的扁平化节目标签体系得到扁平化的节目标签,从而对影视节目进行更加准确、有效的描述[24]。
1 扁平化标签体系
本文将扁平化结构应用于影视节目分类的标签体系中,通过减少原有树形标签体系带来的大量冗余,使不同维度的领域标签、形态标签以及内容标签可以同等权重赋予同一节目,不仅可以简化现有复杂的影视节目标签体系,还可以实现对多元化影视节目进行快速、高效的分类。
本文采取课题组的扁平化节目标签体系,将节目标签分为三大维度,即领域、形态、内容[24],整个体系如图1所示。然后根据三大维度将标签分为内容、类型、时间、评分4类。内容标签根据影视节目选题范围和制作信息提炼出标签,分为背景、题材、基调、元素、人物、主旨、导演、演员;类型标签主要根据影视剧的领域进行划分,分为形式和产地两种;时间标签根据影视剧上映日期进行划分,如:2018年、2017年、90年代等;评分标签根据国内评分可信度较高的豆瓣平台上该影视节目的得分制作而成。
图1 电视节目扁平化标签体系
2 扁平化标签自动获取方案及关键技术
本文所涉及的标签获取流程如图2所示,分为数据采集、数据处理与标签扁平化3部分。首先通过搜集爱奇艺等影视网站的影视数据得到基础的影视标签信息,然后对采集的标签信息进行数据清洗、格式标准化、合并等处理,并结合已建立完成的扁平化标签库,获取影视节目的扁平化标签,最后通过3部分联合运作,实现影视节目扁平化标签的一键自动获取。相比于人工贴标签方式,运用扁平化标签自动获取技术为影视节目贴标签更加准确、迅速。
图2 扁平化标签获取方案
2.1 数据采集
本文提出的扁平化标签获取技术运用对象为影视节目,网络上的相关影视信息则是本文的直接信息数据来源。数据采集过程如图3所示。
相比于其它影视节目,电视剧与电影的节目标签具有复杂性、多样性、主观性等特点,因此本文主要对电视剧和电影的相关信息数据进行采集与处理。利用Python爬虫程序对爱奇艺、搜狗影视、猫眼电影和豆瓣影视4个影视网站进行标签信息采集,信息包括节目类型、节目简介、导演、演员、评分等。
图3 数据采集过程
2.2 数据处理
由于初始采集的影视节目信息数据来源于4个不同网站,因此信息数据格式并不统一,且有大量重复,需要对这些数据作进一步处理,如图4所示。
图4 数据处理
首先,对采集的标签信息进行合并。在4个影视网站上采集的影视信息存在大量重复的情况,此处将同一影视节目在不同网站的相关信息进行合并,使一个影视节目在数据库中只出现一次,标签信息更加清晰明确。
然后,对合并后的节目信息数据进行清洗。采集到的文本中存在一些不必要的数字、标点符号、网址等内容,这些文本信息并不属于节目标签信息,将会增加后续程序运行工作量及获取标签的不确定性,因此在数据处理过程中需将其清除。
最后,对处理后的标签进行格式标准化。4个网站收集的标签信息格式各有不同,因此将同类标签信息进行格式上的统一,包括文字编码格式统一、英文大小写统一、数字格式统一以及标签分隔符统一。
2.3 标签扁平化
对采集到的标签信息进行处理后,基本得到完整的影视节目标签。为使节目标签呈现扁平化特点,利用上文提到的节目标签库以及中文近义词工具包对节目标签进行扁平化匹配处理,使处理后的节目标签全部为源于标签库的扁平化标签。处理过程如图5所示。
将处理后的节目标签与本文建立的节目标签词库进行逐一匹配,将标签库中不存在的标签筛选出来。然而筛选出的大部分标签虽然不存在于标签库中,但其意义与标签库中的标签相近,不能简单删去,因此还需进行下一步的近义词匹配操作。
本文在近义词匹配过程中采用了一款名为“synonyms”的中文近义词工具包,该工具包可以应用于自然语言理解的很多任务中。在Python程序中使用该工具包,可以针对某具体词语进行“近义词查找”及“词语相似度检测”任务。例如,Python程序中对词语“热血”进行近义词匹配的输出内容为(结果保留两位小数): [‘热血,‘青春,‘勇往直前,‘男子汉,‘FUN,‘励志,‘新时代,‘本色,‘好胜,‘
],[1.0,0.61,0.61,0.57,0.57,0.53,0.51,0.49,0.49,0.43]。
上例中的第一个向量是匹配到的相关近义词,第二个向量是每个近义词与“热血”这一原词的相似度,数值越大表示该词与原词相似度越高。本文在近义词匹配过程中,按照相似程度大小排序,将查找到的近义词与标签库中的标签再一次进行匹配。一旦在标签库中查找到该近义词,即将其加入节目标签信息中,并停止对剩余近义词的匹配查找,从而得到标签库中与节目最相近的标签。对于近义词依然无法与标签词库匹配的原节目标签词语,则将其舍弃。
在对节目标签进行扁平化匹配处理后,节目的标签扁平化操作已基本完成。由于在上述匹配过程中,存入影视节目的部分标签信息会有重复,因此还需进行最后一步去重操作,即将重复出现的影视节目扁平化标签刪除。
通过数据采集、数据处理与标签扁平化3个步骤的操作,可以准确地为影视节目贴上标签,标签类型与扁平化标签库中的标签类型相对应,分为“内容”、“类型”、“评价”、“时间”。本文为了更快捷地获取节目扁平化标签,将上述3个步骤进行整合运作,各程序在时间上无缝连接,实现了对影视节目扁平化标签的一键自动获取,大大提高了影视标签获取效率。
3 实验与结果分析
本研究通过训练集对算法进行训练,并通过测试集进行测试。实验中采用两个较为常用的指标测评实验生成的标签,即准确率和召回率。准确率和召回率用于衡量实验中的标签生成效果。P表示节目集合,Lab(p)表示节目p在豆瓣、时光网等视频网站给出节目标签中出现频率最高的标签集合,Tag(p)表示节目p由本实验算法得出的标签集合。准确率定义如下:
[Precision=p∈P|Lab(p)?Tag(p)|p∈P|Tag(p)|]? ? (1)
召回率定义如下:
[Recall=p∈P|Lab(p)?Tag(p)|p∈P|Lab(p)|]? ? ? ?(2)
上式中的[Lab(p)?Tag(p)]表示实验中得出的节目标签集与视频网站给出的节目高频标签集合交集所含有的元素数量。准确率用于表示实验给出标签与网络公认节目标签的交叠程度,召回率表示测试集中利用本实验算法计算得出网络公认节目标签的比例。
以下两个实验根据准确率与召回率对实验结果进行对比分析。每个实验根据所选标签数量的不同分为5组,为了能够更清晰、直观地看到结果变化规律,采用折线图表示结果。
实验1:准确率分析。将豆瓣、时光网等影视网站给出的高频标签作为测试数据与本文所得结果利用公式(1)进行比较计算,本文标签获取算法的准确率结果如图6所示。
图6 准确率结果
由图6可见,随着实验获取标签数量的增加,准确率逐渐降低。主要由于增加标签数量使一些由算法计算出的低权值标签逐渐加入结果中,这些标签很难与本文测试数据进行匹配。然而,这些标签本身权值很低,所以并不能说明实验得出的标签不够准确。可以看到,在使用8个标签时测试结果的准确率很高。事实上,8个标签已能足够反映出一个节目的各方面信息,如本算法得出《霸王别姬》的标签为电影、90年代、陈凯歌、中国大陆/香港、汉语普通话、人性、文艺、同性。
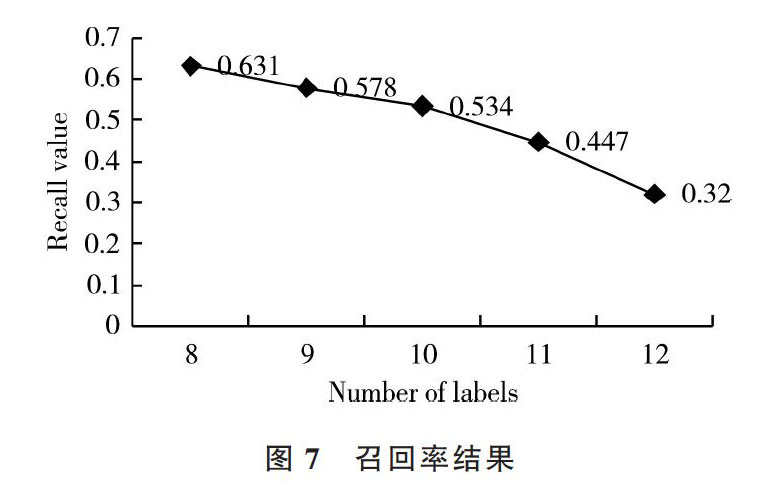
实验2:召回率分析。将豆瓣、时光网等影视网站给出的高频标签作为测试数据与本文所得结果利用公式(2)进行比较计算,本文标签获取算法的召回率结果如图7所示。
图7 召回率结果
由图7可见,随着获取标签数量的增多,召回率逐渐下降,且标签数量越多,下降越快。主要由于越来越多的低频标签加入了测试集,这些数据很难与本文标签数据库中的标签进行匹配。但这些標签通常不具有代表性,并不会影响对一个节目的描述。8~10个标签时情况较好,实际上此时标签已能很全面地展现一个节目。
综上所述,在选用8~10个标签时,本文算法能得到较为理想的结果。在标签数量增多时,准确率与召回率逐渐降低,并且下降速度不断加快。事实证明8~10个标签能够很全面地描述一个影视节目的各方面信息,包括主题、类型、年代、导演、国家、语言等。故利用本文算法能够得出准确、全面的节目标签,并且选用8~10个标签更为合适。
4 结语
本文提出的扁平化节目标签自动获取技术具有高效、准确与全面等特点。扁平化节目标签获取需要经过数据采集、数据处理与标签扁平化3个步骤,并运用了多种自然语言处理技术。实验结果表明,本文算法所得节目标签的准确率与召回率较好,具有较高的实用价值。同时,实验也得出选用8~10个标签描述一个节目较为合适。本文研究成果可用于后续影视节目推荐算法或其它用户服务技术,同时还可在匹配算法方面作进一步优化与改进。
参考文献:
[1] 黄庆. 大数据挖掘与数据处理方法[J]. 电脑迷,2018,9(11): 89.
[2] 高国连,祖成浩. 大数据定向采集技术研究[J]. 中国管理信息化, 2017,12(15):162-164.
[3] 周林云. Web信息采集系统设计与实现[D]. 四川:西南交通大学, 2013.
[4] LIN S-H,HO J-M. Discovering informative content blocks from Web documents[C]. Washing,D.C.:Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2002:588-593.
[5] FREITAG D. Machine learning for information extraction in informal domains[J]. Machine Learning, 2000, 5(39):169-202.
[6] 张婧,刘彦君,范漪萍,等.国内网络信息采集研究现状述评[J].科技管理研究,2017,37(9):260-266.
[7] EMILIO F,PASQUALE D M,GIACOMO F,et al. Web data extraction, applications and techniques: a survey[J]. Knowledge-Based Systems,2014,70:301-323.
[8] 吴爽. 基于python语言的web数据挖掘与分析研究[J]. 电脑知识与技术,2018,14(27):1-2.
[9] 韩洋. 大数据时代计算机信息处理技术探析[J]. 科技传播, 2018, 9(18): 80-81.
[10] 袁琦. 大数据时代计算机信息处理技术的研究[J]. 科技风, 2018,30(28): 72.
[11] FURCHE T,GOTTLOB G,GRASSO G, et al. OXPath: a language for scalable data extraction, automation, and crawling on the deep web[J]. VLDB Journal, 2013, 22(1):47-72.
[12] 周瑜智,刘展鸣,王博,等. 关于网络信息自动采集技术的难点及其解决办法的研究[J]. 科技传播, 2013, 4(6): 204-205.
[13] 李宝密.基于自动生成模板的Web信息抽取技术[J].网络安全技术与应用,2016(9):56,58.
[14] 张一睿. Web端新闻自动采集系统的设计与实现[D]. 北京:中国科学院大学, 2017.
[15] 戚扬. Web数据挖掘、信息采集技术研究及在网络新闻自动抓取中的应用[D]. 杭州:浙江工业大学, 2012.
[16] 马凯. 基于微博数据采集的Web信息集成系统研究[J]. 现代电子技術,2016,39(11):125-128.
[17] 赵红艳. 基于大数据技术的小微企业信息采集技术研究[J]. 科技展望, 2015 (30):1-3.
[18] 周剑. 面向Web舆情评价信息的采集与分析系统的研究与开发[D]. 苏州:苏州大学,2017.
[19] 汤露阳. 面向网络舆情分析的数据采集与管理方法研究[D]. 成都:电子科技大学,2017.
[20] 李晓伟. 云环境下的舆情监测关键技术研究[D]. 绵阳:西南科技大学,2017.
[21] 王仕艳. 云环境中Web信息抓取技术的研究及应用[J]. 通信电源技术,2018,35(9):175-176,178.
[22] 熊畅. 基于Python爬虫技术的网页数据抓取与分析研究[J]. 数字技术与应用,2017(9):35-36.
[23] DENIS S. Current challenges in Web crawling[C]. 13th International Conference Web Engineering,2013:518-521.
[24] 殷复莲,王颜颜,柴剑平,等. 中国电视节目扁平化标签分类体系研究[J]. 电视技术, 2017, 41(Z1): 174-176,181.
(责任编辑:黄 健)
- 有关数字图书馆对图书馆员具有的影响探索
- 加强医院图书资料的信息管理及开发应用
- 高校图书馆馆员未来职业发展探究
- 高校图书馆参与公共文化服务创新发展对策研究
- 人工智能图书馆管理与阅读推广应用研究
- 浅谈大数据时代公共图书馆读者服务的内涵与定位
- 试论村级农家书屋图书的借阅和管理
- 新时期公共图书馆管理思考
- 关于新时代图书管理工作升级转型问题的探究
- 初探高职院校人事档案管理信息化建设
- 大数据环境下加强档案管理的对策研究
- 互联网+时代我国档案利用特点
- 基于大数据时代的企业档案信息化建设研究
- 浅析网络环境下档案信息资源的整合和开发
- 大数据时代档案微服务的实现途径分析
- 档案信息微服务的实现路径分析
- 高职院校档案信息资源共享策略分析
- 浅析企业档案信息服务的优化策略
- 大数据条件下档案工作发展对策探析
- 事业单位档案管理信息化建设的方法及策略
- 档案信息化建设与档案管理的几点思考
- “互联网+”时代事业单位档案管理创新对策
- 谈信息技术在事业单位档案管理中的应用
- 区块链+数字档案馆建设利弊浅析
- 街道办事处档案管理信息化建设工作思路探析
- hard-and-fastness
- hard asset
- hardasset
- hardback
- hardbacks
- hardball
- hardballed
- hardballing
- hardballs
- hard-bitten
- hardboard
- hardboards
- hard-boiled
- hard boiled
- hard-boiledness
- hard-boiledness'
- hard-boilednesses'
- hard-boilednesses
- hard-boiledness's
- hard cash
- hardcash
- hard cashes
- hard-charging
- hardcharging
- hard-code
- 酒缗
- 酒缶
- 酒缸
- 酒罐子
- 酒肆
- 酒肆嘲酒
- 酒肉
- 酒肉之交
- 酒肉兄弟
- 酒肉兄弟千个有,落难之中无一人
- 酒肉兄弟,柴米夫妻
- 酒肉弟兄
- 酒肉弟兄千个有,落难之中无一人
- 酒肉摊场吃,王条依正行
- 酒肉朋友
- 酒肉朋友千个有,落难之时一个无
- 酒肉朋友多多有,落难之中半个无
- 酒肉朋友好找,患难之交难逢
- 酒肉朋友相邀吃喝玩乐
- 酒肉朋友短,患难夫妻长
- 酒肉朋友,柴米夫妻
- 酒肉极多,生活奢侈
- 酒肉穿肠过,佛在心中坐
- 酒肉穿肠过,佛在心头坐
- 酒肉穿肠过,佛祖心中留