黄静 官易楠

摘要:随着智慧农业的发展,农业生产中海量数据不断涌现。在海量数据中难免存在噪声数据,这些数据不仅难以提供有效价值,还会影响信息挖掘。针对该问题,采用基于密度的DBSCAN聚类算法进行异常数据处理。鉴于DBSCAN算法对参数敏感,结合数据集本身特性与统计学思想以绘制各点之间的距离升序曲线,预估出DBSCAN的Eps参数。仿真实验结果表明,改进算法平均准确率达到99.6%,较传统算法提高了1.7个百分点,并且在10次检测中,改进算法只有3个数据判定错误,证明该参数设置方法对异常数据处理准确率更高,稳定性也更好。
关键词:智慧农业;聚类算法;DBSCAN;异常数据
DOI: 10. 11907/rjdk.191763
开放科学(资源服务)标识码(OSID):
中图分类号:TP39
文献标识码:A
文章编号:1672-7800(2020)004-0219-05
0 引言
在现代农业发展过程中,智慧农业越来越受到重视,其突出表现是人们通过数据采集设备获取农作物生长信息,从而更实时精确地了解农作物生长状况,较好地摆脱了传统仅依靠经验种植的不足[1]。但是在采集到的海量数据中,由于外界干扰或者设备异常等原因会存在噪声数据。这些数据不仅不能反映农作物真实情况,可能还会影响农作物生长状况分析,导致分析结果出现偏差甚至错误[2]。
针对异常数据处理,依据异常数据在数据集中数量较少且离散分布的特点[3],在统计学中有标准差法和t一检验法等异常数据检验方法[4]。这些方法通过分析数据分布情况,判断数据点在数据集中出现的概率,当数据出现概率特别低时,判定该数据为异常数据。此类方法在一定程度上可识别出异常数据,但不能较好地对数据进行处理[5]。
数据挖掘中常用聚类工具可以对异常数据进行检测和处理。通过对数据集进行聚类分析,将相似数据点归为一个聚类簇,出现单个数据为一类或者极少数数据为一类的数据点可以判定为异常数据。聚类算法有许多种类,其中基于密度的聚类算法[6]可以通过聚类密度划分聚类簇,分析聚类密度,密度较为密集的被认定为一个簇,密度特别稀疏的可以被认定为噪声数据。基于密度的噪声应用空间聚类(Densitv-Based Spatial Clustering of Applicationswith Noise,DBSCAN)[7]是其中具有代表性的一种算法。DBSCAN算法在异常数据处理中得到了广泛应用。马世欣等[8]利用DBSCAN算法能够对异常数据进行筛选的特点,对局部背景像元中的杂乱点进行过滤,以降低异常数据点对协同探测算法结果的干扰;潘渊洋等[9]利用DBSCAN算法进行传感器网络测量数据的异常检测,提出通过提取环境数据的特征集,根据特征集进行异常数据监测,达到对测量数据实时监测的效果。
DBSCAN算法虽然能够识别并处理异常数据,但是由于算法对参数比较敏感,不同的参数对结果影响较大。针对此问题,宋金玉等[10]提出了Eps和MinPts两个参数的配置方法,通过将数据集本身统计特性与图表可视化展示相结合,为算法确定合适的参数;夏鲁宁等[11]通过对数据集进行统计分析自动确定Eps和MinPts参数,从而避免了聚类过程的人工干预,实现聚类过程的全自动化,提高算法的准确率和稳定性。
以上方法都能够在一定程度上实现对异常数据的检测和处理,但是大多数方法检测出异常数据后都是将数据直接删除,这样会造成信息丢失。因此,在处理异常数据时,将噪声数据与其距离较近的聚类簇中心值进行替换[12]。本文依据以往研究成果,提出将DBSCAN算法与统计学思想相结合,通过对数据集中对象的距离值进行统计分析,预估出Eps参数。由于传感器采集数据变化较为平缓,在以往研究中MinPts的值一般较为固定,因而MinPts采用经验进行确定。本文采用统计思想与经验判断相结合的参数设置方式,在提高异常数据检测准确率的同时,还减少了计算量和时间,同时采用聚类簇中心值替换噪声数据的异常数据处理方式,一定程度上保留了数据信息。
1 DNSCAN算法
1.1 算法原理
DBSCAN算法是一种通过数据对象密度进行查找相似属性的聚类算法[13]。该算法不需要提前确定聚类簇的数量,不仅能够对任意数据进行聚类,还能识别数据中的噪声点,因而可以用来对异常数据进行处理[14]。其中DB-SCAN算法关键定义如下:
(7)簇。所有密度相連的点组成的集合。
在一个数据集中,并不是所有数据对象都是核心对象,还有边缘对象和噪声对象。边缘对象表示数据对象不是核心对象,但是存在于某个核心对象的8-邻域中;噪声对象表示该数据对象不是核心对象,也不存在于任何核心对象的ε-邻域中。
1.2 算法流程
通过以上定义可知,DBSCAN算法的核心在于参数Eps和MinPts,通过这两个参数确定每个点的邻域和核心对象,继而通过核心对象寻找密度可达点,从而实现数据对象聚类。
DBSCAN算法流程如下:
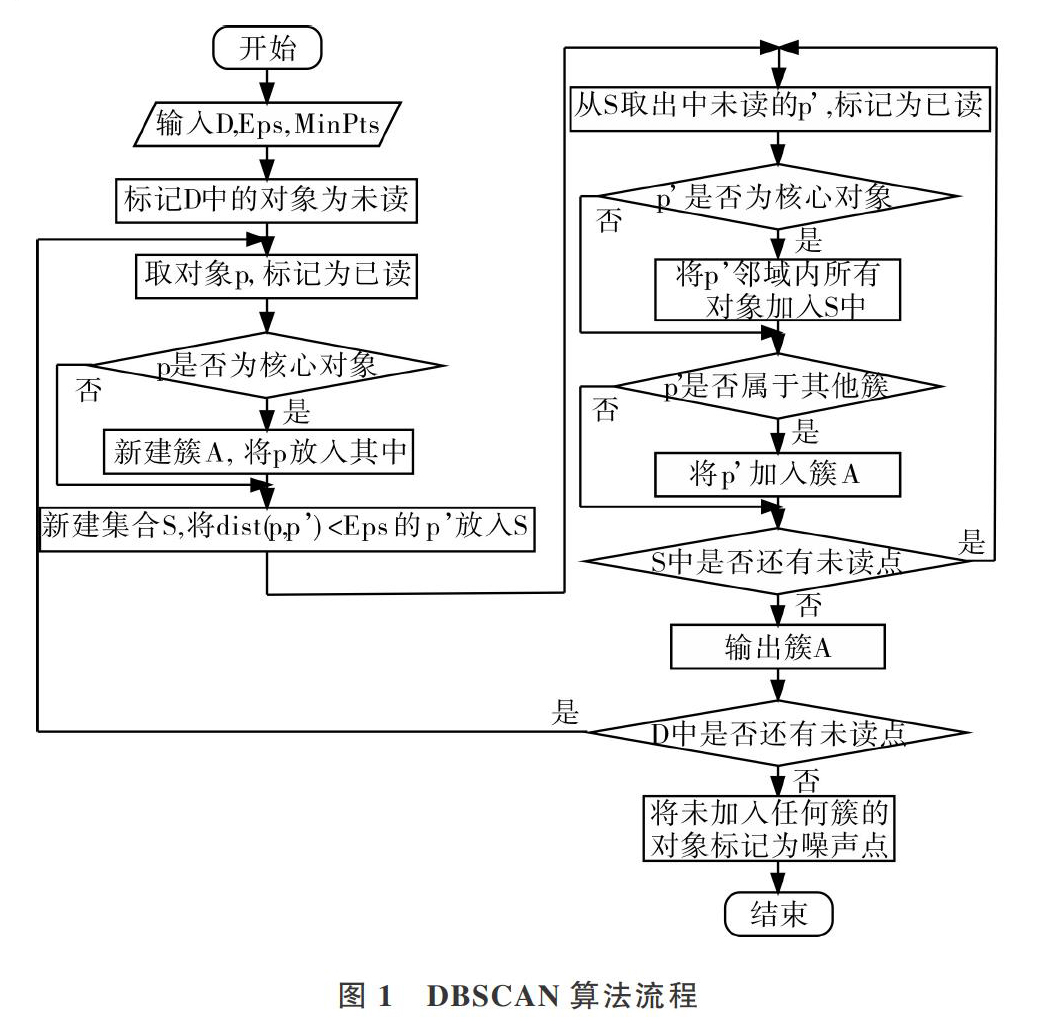
Stepl:输入的数据集D={x1,x2,…,xn},ε为半径参数,MinPts为最小对象参数,将数据集D中所有对象标记为未读。
Step2:从数据集D中取包含任意个数据对象p的数据集Di,其中Di∈D,i=1,2,3-,并将Di标记为已读。
Step3:通过ε和MinPts参数对p进行判断,如果p为核心对象,找出p的所有密度可达数据对象,并标记为已读。若p不是核心对象,且没有哪个对象对p密度可达,将p标记为噪声数据。
Step4:在满足Di∩ Di=1.∈⑦的条件下,重复Step2和Step3,直至所有数据都标记为已读。
Step5:将其中一个核心对象作为种子,将该对象的所有密度可达点都归为一类,形成一个较大范围的数据对象集合,也称为聚类簇。
Step6:不断循环Step5直至所有核心对象都遍历完,剩下没有归为一类的数据便为噪声点。
DBSCAN算法流程如图1所示。
DBSCAN算法有众多优点,比如:算法可以聚类任意形状的集群,能够较好地发现噪声点[15]。但是DBSCAN参数Eps不同,对聚类效果会产生很大影响[16],当Eps选择过小时,会使得很多点被定义为噪声点,影响数据信息;当Eps选取过大时,会把几个聚类簇合在一起,并且有许多噪声点将无法很好地被识别出来[17]。针对DBSCAN中另一个参数MinPts,由于农业数据变化较为平缓,因而通常在算法执行过程中该值较为固定,可以依據经验进行判定[18]。
2 DBSCAN算法改进
针对DBSCAN中参数Eps值对结果影响较大的问题,对数据集中各点之间的距离进行计算,得出各点之间的距离值。由于噪声点具有数量少且离散分布的特点,利用统计学思想,寻找一个Eps值,能够将大量正常分布的数据和少部分离群分布的数据分割出来[19-20],较好地提高算法异常数据寻找准确率。
按照式(2)取参数p=2的欧式距离公式,计算每个点之间的距离用并用d(i,j)表示,并将所有d(i,j)构造成一个Dist n×n矩阵,表示如式(3)所示。
Distn×n=(d(i ,j)|1≤i≤n,1
(3)
矩阵Dist n×n中,每一行表示某个点到所有其它点的距离。将Dist n×n矩阵每一行中的值按升序进行排列,排列之后矩阵第i列表示距离每个点第i近的点。每一行矩阵表示每个点到其它点的距离由小到大排列,由此可通过数值统计方法得出每一行数据的距离升序曲线如图2所示,通过判断图中陡峭点位置,确定参数Eps最优值范围。其中,数据集采用之后实验使用的含噪声原始数据。
图2是由7条按距离升序排列绘制的图形,且最下面的那条曲线为距离参考点最近的距离升序图,最上面的那条曲线为距离参考点最远的距离升序图。由图2可知,图像在前中期比较均匀,趋势也较平缓,当图形到达接近距离为0.35-0.45时,在图中箭头标注的位置出现较为密集的陡峭点,因此可以预计DBSCAN的最优Eps参数在0.35-0.45。依据经验MinPts的值选取6,通过观察图2可以发现从下往上第6条曲线的陡峭点接近0.4,可以将最优的Eps设置为0.4。
其原理为:针对异常数据量少并且分散的特点,当曲线比较平缓时,说明此时在该距离范围内,数据量的数量仍然较多。当出现陡峭点时,之后距离范围内所含的数据量较少。因此,可以利用该陡峭点对应的距离大小较好地区分出异常数据,且将极大减少正常数据误判几率[21]。
3 实验验证
3.1 实验设计
为了验证设置参数的有效性,选取缙云县某处茶园空气温度传感器在某一时间段采集到的140组茶园空气温度数据,并向其中随机添加25组离散点,以此数据作为实验数据。由于传感器采集数据属于一维数据,进行聚类时效果不好,在聚类之前首先将一维数据转化为二维。可以将相邻的两个值一个归为X坐标值,另一个归为Y坐标值,即将数据变为二维。比如数据D={ d1,d2,d3,…,dn}转化为D={ (d1,d2),(d3,d4),…,(dn-1,dn)},140组一维数据可以转化为70组二维数据。对数据使用DBSCAN算法进行处理,寻找核心对象及其密度可达的每个对象点作为一个类。另外一些密度不够且不为任何核心对象点的密度可达的点,被判定为噪声,将由距离较近聚类中所有核心对象均值替代。通过统计分析可知,Eps参数最优值为0.4,再取Eps参数分别为0.35、0.38、0.4、0.45,MinPts参数为6进行实验分析,通过识别出的异常点个数、误判的异常点个数和去除异常数据后数据变化情况判断异常数据处理效果。
3.2 实验结果与分析
分别将Eps参数设定为0.45,0.4,0.38,0.35,MinPts设定为6,采用DBSCAN进行聚类,得到聚类簇,并求出各聚类簇中心点的值,将各噪声点采用距离最近簇的中心值进行替代,得出去除噪声数据的滤波效果图,通过Matlab进行仿真实验,实验结果如图3所示(彩图扫描OSID码可见,下文同)。
图3-图6为取不同Eps参数的聚类效果和滤波效果。其中,聚类效果图中黑色圆圈为算法识别出的噪声数据,其余颜色为聚类簇;滤波效果图中粉红色为原始实验数据,蓝色为滤波后的数据。
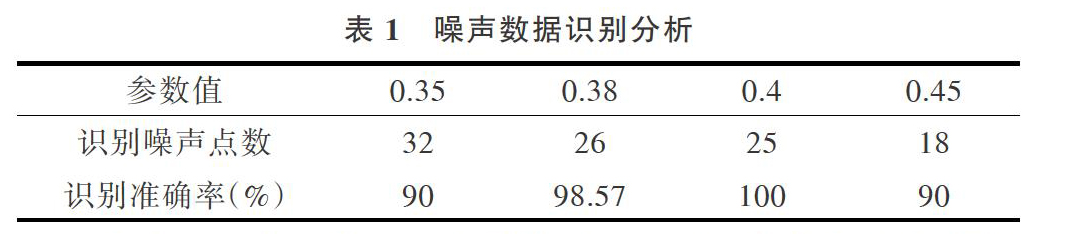
通过以上实验可知,各参数识别出的噪声点情况如表1所示。
由表1可知,当Eps参数设为0.4时,将噪声点全部识别出来,且与0.4较为接近的参数0.38,其准确率达到98.57%,比距离0.4较远的参数0.35和0.45准确率高,证明采用此方法进行参数预估效果可行。且从实验结果中的滤波效果看,通过采用聚类簇中心值代替噪声点数据的方式,较好地降低了数据偏离程度,从而可以减少异常数据对于结果分析的影响。
为了避免实验的偶然性,随机选取茶园10个时间段的140组空气温度数据进行测试,并向每组数据中随机加入25个噪声点。按照以上方法进行仿真实验,在10次检测中,有3个数据判断错误,准确率达到99.6%。按照传统方法,由于不能确定哪个Eps参数较优,通常选取之前某个Eps作为固定值,此处选取0.4作为10次固定的Eps值,在10次检测中,有15个数据判断错误,准确率为97.9%。可以看出,改进算法提升了异常数据识别准确率与稳定性。
4 结语
本文为解决农业传感器采集数据中异常数据处理问题,采用基于密度的DNSCAB算法进行异常数据检测与处理。针对DBSCAN算法参数敏感的特点,采用统计学中的图表对数据集中各点相互距离进行统计分析,预估出参数Eps的值。实验验证表明,该方法获取的参数识别异常数据准确率较高。同时,针对直接将噪声数据删除导致信息丢失的问题,采用聚类簇中心点对噪声数据进行替代,通过此方法可以减少离散点偏移。
目前,虽然采用该方法对数据集中各点相互距离值统计分析可确定参数的一个范围,但参数值的具体取值仍需人为估计,导致参数并不是十分精确,需作进一步研究。
参考文献:
[1]刘亚东.物联网与智慧农业[J].农业工程,2012,2(1):1-7.
[2] 张永峰.对数据采集器等受雷击情况的分析及对策[J].电子科技,2004(7):58-60.
[3]刘云,袁浩恒,数据挖掘中并行离散化数据准备优化[J].四川大学学报(自然科学版),2018,55(5):103-109.
[4] 康团结.多傳感器数据处理的列车环境监测系统[D].成都:西南交通大学,2018.
[5]毛李帆,姚建刚,金永顺,等.中长期负荷预测的异常数据辨识与缺失数据处理[J].电网技术,2010,34,(7):148-153.
[6] 孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008(1):48-61.
[7]ESTER M. KRIECEL H P,XU X.A density-based algorithm for dis-covering clusters a density-based algorithm for discovering clusters inlarge spatial datahases with noise [Cl. International Conference onKnowledge Discovery& Data Mining, 1996.
[8]马世欣,刘春桐,李洪才,等.基于空谱联合聚类的改进核协同高光谱异常检测[J].光子学报,2019,48(1):0110003.
[9]潘渊洋,李光辉,徐勇军.基于DBSCAN的环境传感器网络异常数据检测方法[J].计算机应用与软件,2012( 11):69-72.
[10] 宋金玉,郭一平,王斌.DBSCAN聚类算法的参数配置方法研究[J].计算机技术与发展,2019(5):1-8.
[11] 夏鲁宁,荆继武.SA-DBSCAN:-种自适应基于密度聚类算法[J].中国科学院大学学报,2009,26(4):530-538.
[12] 朱振国,冯应柱.基于数据场的类簇中心选取及其聚类[J].计算机工程与应用,2018.54(8):131-136.
[13] 针对非均匀密度环境的DBSCAN自适应聚类算法的研究[D].重庆:重庆大学,2015.
[14] 多密度聚类算法研究[D].无锡:江南大学,2018.
[15]吴伟民,黄焕坤.基于差分隐私保护的DP-DBScan聚类算法研究[J].计算机工程与科学,2015,37(4):830-834.
[16]SHAH G H.An improved DBSCAN.a density based clustering algo-rithm with parameter selection for high dimensional data sets [C].Nirma University International Conference on Engineering, 2013.
[17]SUN X, ZHENCH,HUI LI,et aI.Bad data identification for leakagereactance parameters of transformer based on improved DBSCAN Al-gorithm [Jl. Automation of Electric Power Systems, 2017, 41(9):96-101。
[18] 石鸿雁,马晓娟.改进的DBSCAN聚类和LAOF两阶段混合数据离群点检测方法[J].小型微型计算机系统,2018,39(1):74-77.
[19] 侯雄文.浅析DBSCAN算法中参数设置问题的研究[J].科教导刊(电子版),2017( 30):266-266.
[20]王兆丰,单甘霖,一种基于k-均值的DBSCAN算法参数动态选择方法[J].计算机工程与应用,2017,53(3):80-86.
[21] 曹科研.不确定数据的聚类分析与异常点检测算法[D].沈阳:东北大学,2014.
(责任编辑:孙娟)
作者简介:黄静(1965-),女,博士,浙江理工大学信息学院教授、硕士生导师,研究方向为嵌入式系统、专用测试设备、电子功能材料计算设计及独立分析软件设计;官易楠(1993-),男,浙江理工大学信息学院硕士研究生,研究方向为农业数据挖掘与计算机应用,本文通讯作者:黄静。
- 基于“自主发展”的小学数学有效情境创设的思考
- 游戏化教学法在小学数学课堂教学中的应用研究
- 小学数学教学中提高学生计算水平的策略
- 小学生数学自主学习能力的提升策略
- 基于生活化的小学数学计算教学思考
- 高中篮球教学优化措施
- 项目化课程教学视角下中职校企合作模式的实施现状与对策
- 对高校教学管理信息化路径的几点思考
- 润物细无声,美育求共赢
- 初中信息技术教学提升教学效率的方法
- 高中生物学课堂教学的有效变式教学
- 语文教学中实施审美教育的途径
- 西藏高中汉语古诗文吟诵教学初探
- 高中语文文学作品中人物语言得体性探微
- 观察生活 依托教材 捕捉细节
- 信息技术背景下的高中语文教学
- 培养农村小学低年级语文阅读习惯的策略探析
- 落实三维目标 创新语文教学
- 工匠精神在高职学生思想政治教育中的渗透探讨
- 浅谈项目教学法在小学信息技术教学中的运用
- 爸爸,妈妈,我爱妹妹,你们也爱我吗?
- 运用小学科学课,培养学生的读写能力
- 利用沙水建构游戏,促进幼儿能力发展
- 论新课程标准下心理学在中小学教学中的应用
- 核心素养背景下搞好农村学校校园文化建设的实践探索
- loop¹
- loos
- loo's
- loose
- loosecannon
- loose cannon
- loose cannons
- loosed
- loose end
- loose ends
- loose-fitting
- loose leaf
- loose-leaf
- loose-leaf binder
- loose leaf binder
- loosely
- loosen
- loosened
- loosened up
- loosener
- looseners
- looseness
- loosenesses
- loosening
- loosening up
- 耽溺
- 耽爱
- 耽独
- 耽玩
- 耽疾
- 耽病
- 耽研
- 耽禅
- 耽耽
- 耽色
- 耽话
- 耽误
- 耽误一夜眠,十夜补不全
- 耽误一船人
- 耽误了庄稼是一季,耽误了孩子是一代
- 耽误了庄稼是一季,误了孩子是一代
- 耽误事情
- 耽误 拖延
- 耽误授课
- 耽误掉
- 耽误时机
- 耽误,荒废
- 耽读
- 耽迟
- 耽迟不耽错