张乐玫
摘要:如何能提供更高精度、更短预测时间、更少成本花费和更强实用性的应用是当下室内定位的研究热点。针对提高定位精度,同时缩短定位预测时间的问题,本文将特征选择算法引入到传统的指纹定位法中,应用主成分分析法,将终端收集的数据进行空间变换、特征压缩,从而去除数据噪声,在实测过程中达到更高定位精度,降低定位模型复杂度,缩短预测时间的目的。同时,本文引入提升算法,通过结合并优化决策树算法,重点关注错分样本,达到优化模型训练过程,增强模型实测泛化能力的目的。特别的,将提升算法与特征选择相结合,能够提供更精确、实用能力更强的定位方法。
关键词:模式识别与智能系统;提升算法;特征选择;室内定位
中图分类号:TP311
文献标识码:A
0 引言
近年来随着Google、苹果等公司对室内定位技术投入越来越多的关注和支持,国内外各领域对室内定位技术的研究再一次掀起了新的高潮。位置信息主要应用于基于移动端的LBS(Location Based Services)服务中,例如大型商贸城的推送业务,医院的导航,机场循迹,在大型娱乐场所或博物馆向游客提供当前的位置信息和相应设施资料等。
随着全球定位系统(GPS,Global Positioning System)的发展,室外环境中的定位服务已满足人们的需求。然而,GPS定位系统在空旷的室外,视距传播(LOS,Line-of-Sight)信道环境中使用才能达到较高精度。而室内环境中,摆放设施、建筑物墙壁等的遮挡而造成信号在传播过程中的反射、衍射现象使得室内信道呈现多径传播、非视距传播等特点,从而限制了GPS在室内环境下的使用。因此,室内环境的位置服务,特别是在精度、可靠性、实时性等方面,仍需要进一步的提升。
参照现有室内定位技术的一系列研究结果,许多室内定位算法和系统分类都有所提及。按照室内定位使用的信号的差别可以将室内定位系统分为红外室内定位系统、射频识别定位系统(RFID)、超宽带(UBW)定位、蓝牙定位系统和基于WiFi/WLAN室内定位系统等。相比较,基于WiFi/WLAN室内定位系统最大的优势是基础设施成本低,无需额外提供定位标注等多余硬件设备,定位精度高,系统易于维护,用户体验好及操作方便等。而基于WiFi/WLAN室内定位系统依赖的算法可以分为室外定位常用的三边定位法、三角测量定位法及位置指纹法(LocationFingerprinting)。前两种技术使用的最佳场景均为视距传播环境,而位置指纹法以模式识别理论为基础,重点关注每一参考点的指纹特点,只要传播环境没有大幅度的变动,接入点的信号发射功率没有大幅度的波动,就可以通过识别位置指纹来确定位置。
从室内定位精度、定位成本和定位实时性出发,本文提出了一种基于提升算法的位置指纹算法,能有效提高定位精度。另外,定位系统大规模部署时需要考虑效率问题,本文在位置指纹法中引入了特征选择,能有效降低特征维度,提升定位性能。
1 位置指纹定位法
基于WLAN系统的位置指纹法定位分为两个步骤,离线训练阶段和在线预测阶段,离线阶段通过收集各个参考点的接收信号强度(RSS,Received Signal Strength),并使用一定的定位算法,例如决策树、K近邻和支持向量机等进行模型训练,在现阶段将采集到的数据放入预测模型得到最终的定位结果。本章首先介绍了位置指纹法的信号模型,并基于此模型介绍了决策树算法,引入了对决策树进行改进之后的提升算法。
1.1室内信号传播模型
1.2决策树算法
决策树的学习过程包括三部分:特征选择、树的构建和树的剪枝过程。建树过程可以按照自顶向下的顺序,开始时所有样本均在根节点中,而后再根据一定的特征选择算法将各个样本往下细分,直到满足一定的停止条件。这些条件包括:当叶子节点的样本数量小于某一规定阈值时,当前的节点可以当作叶子节点,不必往下继续分割;当当前节点错分样本的误差小于某一规定阈值时,当前节点可以停止分割;当在某一节点处存在于该节点的特征已用尽,则通过举手表决的形式选择该节点的标志参考点;当树的深度达到一定高度值时,当前节点可不需在分;当某一节点钟的样本均属于同一类时,算法停止。
决策树算法的优势在于:
1.树模型可以用可视化的方式实现,也就是说内部的模型形成方式可以直观的观察到,这样利于模型的理解和解读;
2.不需要过多的训练数据,但训练数据需要尽量包含各种特征,且样本的分布应尽量均匀;
3.对于数值型的样本和类别型的样本均可处理。
1.以列向量的形式表示数据,组合并形成M×N矩阵X;
2.计算数据矩阵X的均值向量;
3.计算数据集X的协方差矩阵SX;
4.计算SX的特增值及对应的特征向量;
5.将特征值按照降序排列,并根据排列顺序将对应的特征向量组合成矩阵,并取前k维特征,按照需要使所取特征的能量占总能量的85%或以上,最终的矩阵为P;
6.使用矩阵P将原数据集X转换成新数据集Y。
如上所述,PCA存在一些限制条件:
1.PCA对于数据呈线性相关的强假设并不符合大部分的数据分布特性,因此,使用PCA的到的新的数据分布只能在一定程度上近似达到去噪和去除冗余的目的;
2.PCA假设使用均值和方差这两种统计学特征足以表示数据的概率分布,只有高斯分布满足这个条件,因此,其他的分布都会弱化PCA的结果。也正是在这个强假设条件下,信噪比及协方差矩阵才能完全表示数据的噪声和冗余。但是根据中心极限定理,在数据量充分的情况下,大部分数据分布都呈现高斯分布特性。
PCA的一个假设条件是线性假设,另一假设条件是在协方差矩阵中,大的方差值对应重要的特征。数据特征的主成分之间相互正交。这种假设使得PCA的求解过程可以依赖线性几何的降解方法(SVD分解)。
4 定位算法性能测试及结论分析
本章主要针对上述介绍的定位算法及特征选择算法设计搭建了一套完整的实验平台,并在该平台上对算法进行测试仿真,将实验结果数据用表格的形式表现出来,并对实验结果进行分析。
4.1实验方案设计及环境搭建
针对传统的室内定位算法、提升算法和特征选择算法,实验时设计了一套完整的客户端和服务器模块进行实际的测试和仿真。客户端模块是基于Android手机编程实现,主要完成的功能包括使用手机自带的传感器进行手机周围环境AP的MAC地址收集、对应接收信号强度RSS收集和定位参考点设置,再将收集到的对应信息传输到服务器进行处理。服务器模块通过接收移动端传来的数据先进行数据清洗,对失踪的数据进行补充,删除异常的数值,之后将数据结果转换成对应的dBm值存储在SQL数据库中,并通过编程调用适当的算法进行模型训练。当需要定位时,客户端程序收集到的数据上传服务器之后,服务器会调用以训练好的模型进行预测,并将预测结果显示在服务器端的地图上。
4.1.1实验方案设计
图1是整个定位系统结构的简化图,大致流程可以概括为,手机等移动设备采集收集信号,并将数据通过WLAN网络传送给中央服务器,有服务器来进行集中处理,包括数据清洗、特征选择、定位建模、预测数据等操作,再将定位好的目标节点信息显示在服务器的地图上,从而完成训练和预测定位过程。
4.1.2实验环境选择
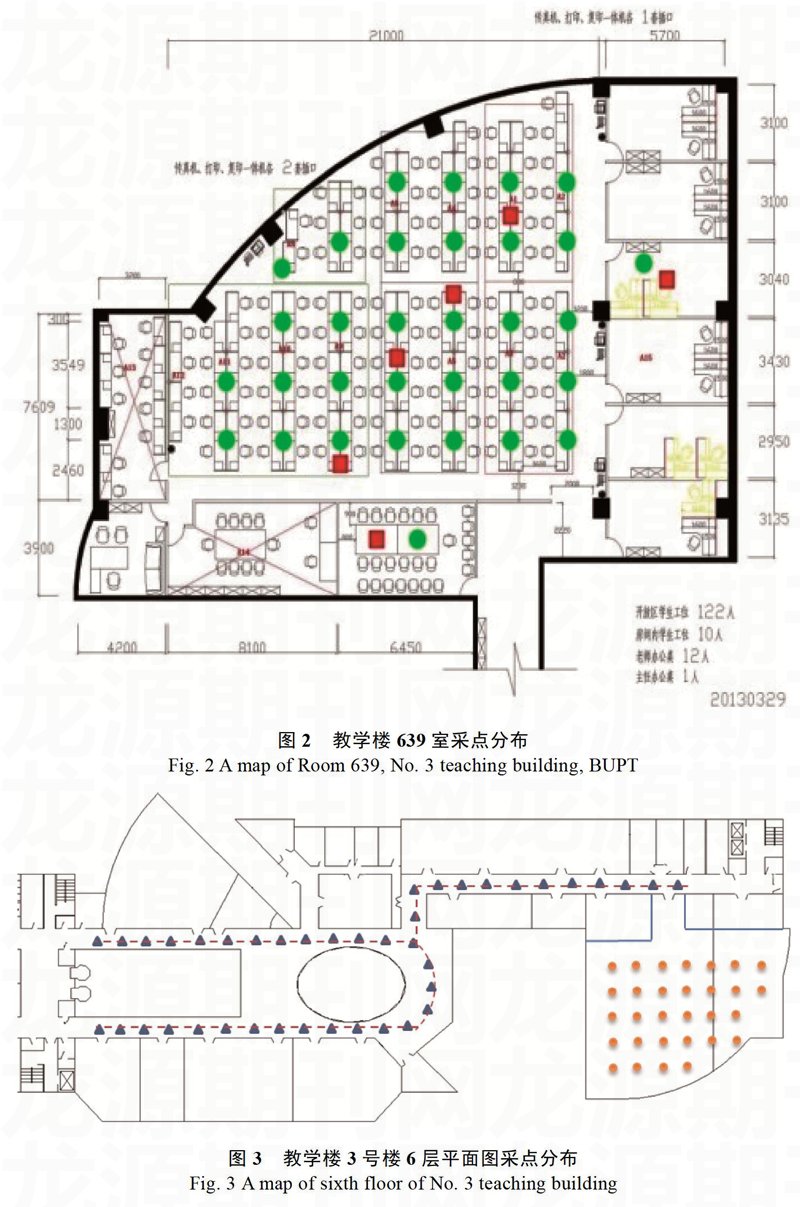
论文实验的物理环境选择在北京邮电大学教三楼6层639室及6层楼道内。局域网为北京邮电大学内部教育网。实验时将实验室的平面分为32个长为2.7m,宽为2.4m的cell,粒度为6.48m2。走廊被分为241个区域,设置了41个参考点,没个参考点之间相距3.6m。实验室内参考点的设置如图2所示,用绿色圆点标注。另外定义了6个预测参考点,它们与原定的参考点间有一定的距离。预测点在图中用红色实心方块标注。走廊之间的间隔较为分散,因为走廊环境下的AP点不易改变,且除了上下课时走廊中的人流量较大外,走廊的信号分布较为稳定。图3给出了6层平面图以及参考点采集区域,楼道内的信号采集策略采用的是每个cell内均匀采集样本点,图中的三角形大致表示的是每个cell的中心位置。
每个参考点总共采集500组数据,采集间隔为1s。
3号教学楼楼道内的采样点用实心三角形表示,639室内的采样点用实心圆形表示。
4.1.3实验数据收集
实验所适用的硬件设备移动端采用的是IBM生产的5台相同的测试机,型号为MFLD GI。空间中总共收集到177各不同的AP地址。另外,两台型号为E14118的Sony笔记本电脑作为服务器进行信号处理、模型训练、参数选择和性能评估,所用的系统为Ubuntu 12.04,编程语言为shell和python2.7。数据收集方式在划分好楼层平面图之后,在每个cell的中心点采集500组数据作为训练数据。
4.2实验结果及分析
4.2.1实验结果
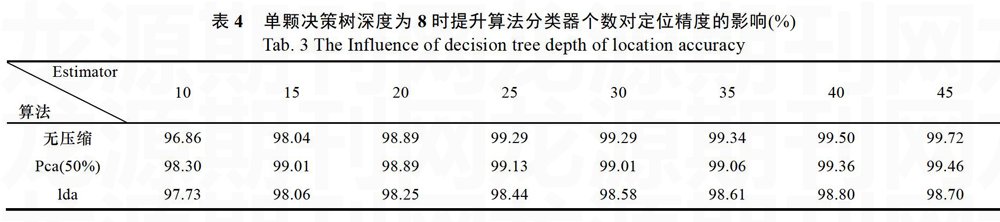
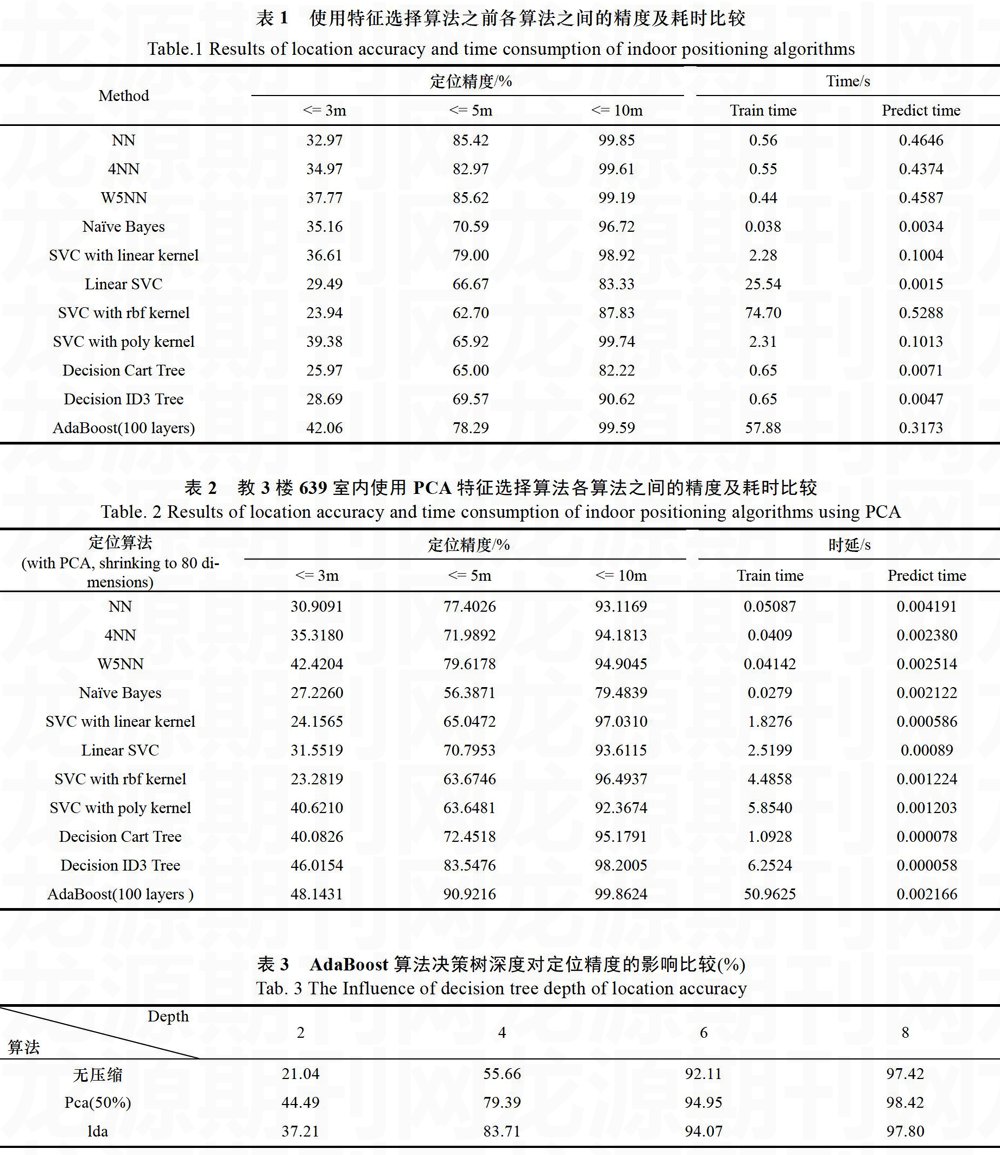
本节给出实验结果及相关说明。其中,表1给出了使用特征选择算法之前各个定位算法的定位精度、模型训练时间及定位时延的比较结果,表2是使用PCA降维到80维特征之后各个算法的比较,表3为交叉验证阶段针对AdaBoost算法中单个树的深度对算法精度的影响,表4 AdaBoost算法中弱分类器数量对算法精度的影响。
通过表1和表2结果比较,结论显示经过特征选择过程处理之后的数据除了缩短模型的训练时间外,也可以增强模型的鲁棒性和泛化能力,降低模型的复杂度。特别是AdaBoost算法在结合PCA特征选择算法之后,不仅定位精确度得到显著提升,预测时延也相应缩短,更加适合实际使用。
从上表3可以看出,随着单个二叉决策树深度的增加,无论是经过特征选择算法还是未经过特征选择筛选的算法定位精度都呈现提高的趋势,但是当单个决策树的深度进一步增加时,有于决策树本身的特点,训练时间更长,模型更加复杂,更容易出现过拟合。因此,单一决策树的深度需要实验折衷选择。
表4表示当单一决策树的深度设定为8时,决策树的棵树的变化对定位精度的影响。由表中可以看出,虽然定位精度相差不大,偶尔呈现波动的状态,但是总体变化趋势仍然是随着决策树棵树的增加,定位精度对应提高。
4.2.2实验结论分析
根据上一节的数据结果比较,分析如下:
1.提升算法AdaBoost:提升算法通过将多个弱分类器乘以权值并级联的形式,用启发式的算法增强了模型对错分样本的关注度,提高了算法的泛化能力。提升算法也可以非线性分布的样本进行分类,但不同与支持向量机算法的是,后者对不同核函数的使用导致最终的分类超平面呈现核函数类型的分布,而AdaBoot却可以模拟任何形状的分类平面。由于提升算法是建立在决策树桩这种弱分类器基础上的算法,因此,该算法也具有决策树的一系列优点,即预测效率较高等。
2.LDA特征选择算法分析:LDA算法的优势是在模型的训练阶段同时考虑到类内间距和类间距离。LDA有时需建立在PCA算法的基础上先进行特征压缩,然后再根据类别信息进行进一步特征压缩。虽然该算法属于监督性算法,考虑到类别之间的差异,但LDA最终的压缩维数小于类别种类数,因此,对于有些需要高维特征进行决策的数据集合,往往压缩维数过高导致信息损失严重反而不利于分类。
3.PCA特征选择算法分析:主成分是指较大的特征向量所对应的特征值,该算法考虑去除数据特征之间的线性相关性,从而更有利于找出同类和不同类别的样本,达到降低特征空间维度,防止维度灾难的目的。该方法不仅适用于图像处理,在很多领域均可应用来提取样本的主成分。对于超高维的情况可以采用SVD分解来求出举证的特征值和特征向量。这种方法适用于信号内有用信息能量大于噪声,但若是信号的噪声大于有用信息的情况下,该方法保留的主成分很可能是噪声。
5 总结与展望
5.1总结
论文首次在室内定位邻域引入提升算法,并分析出提升算法的优势和缺陷。另外,由于实际采集的样本中存在很多噪声样本和异常值,因此,首先对数据进行清理是必要的。除了在采集数据之后对都是指的处理,本文引入了特征选择算法去噪和压缩特征,这样做的目的即避免了“维度灾难”,同时去除了不重要和多余的特征,从而达到增强模型鲁棒性和泛化能力、降低训练成本、缩短训练时间的目的。在实验的过程中发现,PCA主成分分析算法配合AdaBoost使用,既避免了过拟合的问题,也使提升算法最大程度的发挥了它的优势,且在一定程度上提高了定位精度。
5.2下一步研究展望
虽然本文的算法使定位精度得到了提升,但基于RSS的指纹定位法仍存在许多问题:
1.首先是前期样本准备的阶段仍然需要额外人力的投入,且随着时间的推移,随着AP的老化或周围环境的改变会影响相同参考点的指纹图谱,这使得隔段时间需要重新训练模型,因此如何进一步减少人力的投入和训练周期是下一步需要研究的课题。
2.另外,由于不同的硬件设备在同意参考点处的指纹图谱均不相同,也就是说不同手机移动端存在异构性,如何解决硬件之间的异构问题也应成为下一步研究的课题。
- 浅谈新课标下初中数学课堂教学中提问情境的设置策略
- 初中语文写作教学问题研究
- 数形结合在初中数学教学中的运用例谈
- 高中通用技术教学中核心素养的构建探讨
- 提升高中思想政治课教学实效性的思考
- 基于学困生转化的初中数学解题错误减少策略初探
- 论提问策略在高中数学教学中的应用
- 基于社会工作学科建设问题的分析
- 在新形势下高等院校思想政治教育模式创新的探讨
- 独立学院“双一流”建设过程中学科基础课教师结构分析
- 《泵与泵站》课程思政教育的实践与思考
- 基于民汉合校理念下高中生英语学习资源开发与利用
- 微课在初中英语活动课中的应用分析
- 打开生活之窗 数学就在身旁
- “立德树人”视野下新高中体育与健康课程标准的德育透视
- 小学美术课堂创意教学策略分析
- 语文课堂中的问题设置
- 微课在教学中的合理应用
- 扬起爱的风帆
- 在语文活动中,培养创新能力
- 提高学生问题解决能力,构建高效优质数学课堂
- 数学计算对学生的重要性
- 基于互联网金融概论课程的高职“教学做”一体化教学模式应用研究
- 丰富学生语言 学会语言表达
- 四年级几何微课的应用策略研究
- deck¹
- declaration
- declarations
- declare
- declare an interest (in sth)
- declares
- declare war
- declaring
- declassification's
- declaw
- declawed
- declawing
- declaws
- declension
- declensions
- decline
- declined
- decliner
- decliners
- declines
- decline²
- decline¹
- declining
- decliningbalancemethod
- decliningstock
- 至治
- 至洽至协
- 至深
- 至清
- 至熟
- 至爱
- 至爱亲朋
- 至理
- 至理名言
- 至理名言能医国
- 至理绝言
- 至痛
- 至矣尽矣
- 至知
- 至祈摄卫
- 至策
- 至精者
- 至纤至悉
- 至纫交谊
- 至罢
- 至胙
- 至至
- 至艺
- 至节
- 至若