符饶


摘要:有效的潜在好友推荐是促进社交网络不断增长的重要途径,基于位置的社交网络(LBSN)支持用户随时随地记录自己所处的位置以及分享身边发生的事,用户通过签到生成的地理位置信息构成了用户的行为轨迹。文章提出了一种利用用户签到信息的潜在好友推荐方法,不同于传统的只考虑签到位置信息的方法,文章中的方法还考虑了签到的时间以及签到的次数。方法首先将签到的时间信息及空间信息压缩,然后进一步通过计算用户之间的相似度来决定向目标用户推荐的潜在好友。相似度主要决定于用户之间的重合点数量、近似点数量以及签到点集大小。文章最后使用大型位置服务社交网络Gowalla的真实用户访问数据,以准确率与召回率作为评价标准,证明了本文使用的方法在效果上优于传统的使用位置信息的潜在好友推荐方法。
关键词:好友推荐;位置服务;用户相似度;签到数据
中图分类号:TP393
文献标识码:A
0 引言
随着移动智能终端的普及和移动互联网的发展,社交网络也在移动互联网上得到了迅猛的发展。用户可以以多种方式随时随地接入移动社交网络,用户之间可以方便地相互联系,分享自己身边发生的事情。
社交网络能够如此活跃的原因,除了能够帮助用户维护现实生活中的社交关系,更重要的是帮助用户发现与自己志趣相投的新朋友。因此,潜在的好友推荐功能是每个社交网站所必备的,并且该功能应该具备一定的准确性。
根据用户的好友网络拓扑进行推荐,算法首先通过用户好友之间的距离选出潜在好友候选人,然后再从候选人中选出与用户兴趣相同的人作为用户的潜在好友进行推荐。基于用户的兴趣特征计算设计了通用的潜在的好友框架。通过计算用户资料之间的相似性来推荐潜在的好友。以上的研究都利用了当前存在的好友网络拓扑图,为用户推荐的好友可以简单的概括为朋友的朋友或是有相同兴趣爱好的人。
基于位置的社交网络服务,是利用GPS、蜂窝网、WLAN等技术获得移动终端的地理位置信息,支持用户随时随地自由记录并分享地理位置等信息。用户可以通过任意类型的移动终端上的专用软件签到所处位置信息,并且告知朋友。签到行为的发生在用户行为的研究上引发了一个新的维度。用户与位置的交互数据第一次被引入到研究当中,提供了空前的机会来理解用户怎样动态的通过位置和线上的朋友交互。
1 相关工作
传统的推荐系统使用得最多的方法就是协同过滤,协同过滤是利用集体智慧的一个典型方法。该算法分析用户兴趣,在用户群中找到与指定用户有相似兴趣的用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。协同过滤算法主要是向用户推荐其可能感兴趣的物品。
对于潜在好友的推荐大致上可以分为两类,一类是“你可能认识的”,一类是“你可能感兴趣的”。第一类算法主要是通过分析目标用户的好友网络,社交网络用户之间主要存在两种关系:强关系和弱关系。强关系指一级人脉,即两个用户是好友关系。弱关系指二级人脉,即用户与用户的关系通过用户产生,也就是说两个用户有共同好友,即为弱关系用户。SNS中的弱关系往往具有长尾性,能够带来巨大的经济效益。把目标用户的弱关系用户推荐给他的强关系用户,但没有给目标用户进行弱关系用户的好友推荐。主要工作是对目标用户进行热点用户的推荐,没有考虑目标用户个人兴趣,对潜在的弱关系用户进行推荐。我们将弱关系用户看成是目标用户的候选推荐用户,根据目标用户与候选推荐用户的共同好友数量,确定两个用户相互关联的程度。共同好友数量越多,说明两个用户关联程度越高,就越有可能认识,因此我们按照这个关联程度向目标用户推荐好友。但是两个用户共同认识的好友数量多,只能说明两个用户在现实生活中有可能是认识的,却不能说明推荐的用户是目标用户感兴趣的用户。
第二类算法主要是通过分析用户资料当中的相似性,如两个用户就读于同一所学校,年龄相近,或是从用户的标签中提取出关键词,分析两个用户的兴趣爱好是否相似等以作为向目标用户推荐的依据。这种推荐算法是从全局的社交网络入手的,具有一定的参考价值,但由于用户所提供的内容有限,并且部分用户可能会提供虚假信息,因此这种推荐有一定的局限性。
随着基于位置的社交网络服务的兴起,用户可以随时随地的记录自己的位置以及分享身边的事。而用户签到的时间与地点是一个能反映用户行为的重要信息。目前已经有不少通过位置信息分析用户行为的研究。文献分析出用户的签到次数并不会随着用户好友数的增加而增加。主要分析位置服务社交网络当中用户的行为,这其中的用户行为包括用户喜欢在什么时间签到以及用户喜欢访问哪些地点。通常的基于位置信息的好友推荐算法都只考虑了用户之间签到位置的相似性,本文提出的算法不仅考虑了用户之间签到位置的相似性,还引入了签到时间及签到次数对好友推荐效果的影响。
2 好友推荐方法
本文使用大型位置服务社交网站Gowalla的真实用户访问数据,设计基于用户历史签到的地理位置信息的好友推荐算法。算法首先对用户签到的时间信息及空间信息进行压缩,进而将用户的历史签到数据映射到二维平面上,将求解两个用户之间的相似性问题转化为几何上求解两个点集之间的相似性问题。
2.1数据描述
研究大型的线上社交网络通常是件困难的事,因为用户的数据都被社交网络服务提供者有效的保护起来,一般人很难获取。因此随机化的爬虫仍然是目前唯一的有效获取数据的方式。我们研究的数据来自于大型位置服务社交网络Gowalla。
2.1.1数据集特征
在我们的数据集当中,并非每位用户都是活跃用户。所谓活跃用户就是至少有过一次签到行为的用户。数据集中共包含了107092位活跃用户。数据集的一些统计特性见表1。其中包括活跃用户总数、签到位置总数、签到总次数、每个位置平均被签到次数以及每个用户的平均签到次数。
2.2算法描述
从数据集中发现,当两个用户是好友时,往往他们之间的签到距离比较近,好友之间的共同签到地点与非好友之间的共同签到地点相比,好友之间的共同签到地点大约为14个,而非好友之间的签到地点大约为4个,前者大约是后者的三倍。由此可以看出,用户的地理特征和社交关系互为补充。由此可知,地理位置信息能够十分有效的反映用户之间的好友关系,进而可以有效的向目标用户推荐潜在好友。算法主要是从两个用户签到的次数以及签到的位置两个因素来评估两个用户是否有可能成为好友。
2.2.1时空信息预处理
若两个用户在相近的时间、相近的地点产生签到行为,并且发生该行为的次数越多,说明两个用户越有可能成为好友。然而,由于社交网络上用户规模非常大,若两个用户需要精确匹配每次发生签到的时间、地点,计算量是相当庞大的,因此,本文首先考虑对用户签到的时间、地点进行压缩,以减少计算量。
首先从时间上来说,我们只关心用户在几时几分产生了签到行为,但是不关心产生签到行为的具体日期。我们仅仅将日期划分成工作日与节假日两类,因为大部分用户的行为仅仅只在这两种类别的日期上有明显差异。
进一步,我们按照普通人的生活习惯将一天划分为7个时段,分别是:
(1)23:00~7:00,休息时间
(2)7:00~8:30,工作准备时间
(3)8:30~12:00,上午工作时间
(4)12:00~13:30,午休时间
(5)13:30~17:30,下午工作时间
(6)17:30~20:00,回家及晚饭时间
(7)20:00~23:00,夜晚生活时间
这样一来,我们就将时间信息划分成了14个类别,大大的压缩了时间维度的信息量,减少了计算量。在表2中我们统计了各个时间段的签到数量的分布。
可以看出签到时间最多的时间段是23:00~7:00,也就是休息时间,我们再进一步分解这个时间段发现,23:00~1:00签到的数量占比为47.4%,1:00~6:00签到的数量占比为16.1%,而6:00~7:00签到的数量占比为36.4%。可以看出大部分人都习惯于在睡前或起床时使用手机。
由于在某一地理位置附近,可能有很多不同的签到点,用户访问相近的地理位置时并不一定是在同一个签到点上签到,仅通过判断用户是否访问同一个签到点来计算得到用户间的相似性是趋近于零的。因此,需要对用户签到的位置进行聚类。
2.2.2用户相似度计算
我们基于上述讨论,使用一个量化的值来评估两个用户之间是否有可能成为好友,我们将这个值称为用户的相似度。对于用户的每一次签到,我们知道其签到时间及签到地点,可以将信息映射到二维空间当中,以时间作为横轴,以地点作为纵轴,每个用户的签到行为就可以看成是二维平面上的一个点集。我们需要做的就是评估两个用户签到点集的相似性。
定义1:签到点集(Checking Point Set,CPS),由用户的签到数据映射到二维平面形成的点集。
定义2:重合点(Common Point,CP),若两条签到记录发生的时间段及区域相同,则称这两条签到记录映射的点为重合点。
定义3:近似点(Similarity Point,SP),若两条签到记录发生的时间段不同,但区域相同,则称这两条签到记录映射的点为近似点。
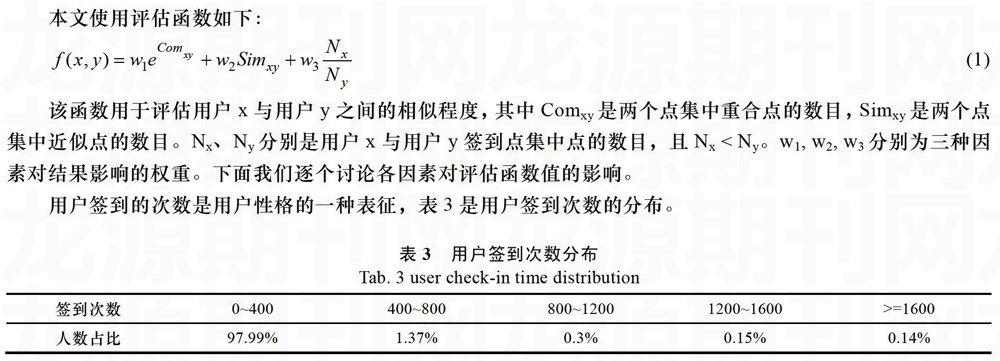
用户签到的次数是用户性格的一种表征,表3是用户签到次数的分布。
从表中我们可以看出,绝大部份用户两年时间仅仅签到不到400次,签到最多的一个用户共签到2175次,平均一天3次左右。因此,不同性格的人会在签到次数上有所不同。该项因素为相似度的一个弱影响项,所以有w3 重合点的数量是反映两个用户相似最重要的指标,因为每一个重合点都代表两个用户在同一个时间段,在同一个地点发生过一次签到行为,因此他们有可能在此时此刻发生了同样的行为。在这一项使用指数函数是基于下面这样的考虑,两个用户如果只有很少的几个重合点,那么这两个用户有可能只是偶然产生了相同的行为,但随着两个用户重合点的数量增多,两个用户就越有可能有着相似的生活习惯,因此相似度应该随着重合点数量的上升而上升,并且上升趋势是先慢后快。 近似点的数量也是相似度的一个强影响项,两个用户有较多的近似点,说明两个用户经常出现在相近的位置,但是这只能说明他们之间可能会受到相同环境的影响,但却不能说明他们之间的生活习性相近,因此该影响项没有重合点的影响力大,因此有w1>w2。 3 实验结果及分析 3.1评价指标 目前常用来评估推荐算法的指标有:准确率(precision)、召回率(recall)及F1指标。准确率指检索出的相关信息量占检索出的总信息量的百分比。召回率指检索出的相关信息量占相关信息总量的百分比。F1指标是根据准确率与召回率得出的一项综合评价指标。它们的定义如下: 3.2实验结果及分析 本文使用上述算法计算用户之间的相似度,并对目标用户进行Top-N推荐,随着N值的变化,所有用户的平均准确率、平均召回率及平均F1指标均会变化。下面将本文提出的算法与传统的只考虑用户签到位置的好友推荐算法进行比较。从图1与图2中可以看出,本文算法在准确率及召回率上都要优于传统算法。 4 结论 本文使用位置服务社交网络Gowalla的真实用户访问数据,提出了基于用户位置信息的潜在好友推荐算法。算法首先将时间信息及空间信息压缩,然后将用户的签到数据映射到二维空间中,将用户的相似度计算转化为求平面上两个点集的相似度。两个用户的相似度主要受重合点数量、相似点数量以及签到数据集大小的影响。文章最后使用准确率与召回率作为评价指标,将本文算法与传统的只考虑用户签到位置信息的好友推荐算法进行比较,证明本文算法在准确率及召回率上都优于传统算法。
- 人体经络的实质研究
- 耳穴治疗皮肤瘙痒症22例
- 头针治疗急性周围性面神经麻痹100例
- 针灸为主辨证施治不寐症120例
- 隔药饼灸治疗异位性皮炎20例
- 电针关刺法治疗颈肌筋膜炎32例
- 针刺血海促进小腿皮肤溃疡愈合75例
- 针刺致发热1例
- 电针疗法新发挥
- 如何消除穴位注射后疼痛的再探讨
- 当归维生素B12穴位注射致关节剧痛3例
- 针刺对急性黄疸型肝炎患者血浆胃动素的影响
- 针刺内关穴对正常人脉率调节作用的观察
- 针刺对急性脑梗塞鼠微血管壁ATP酶的影响
- 穴位注射对胆色素结石模型豚鼠肝脏部分酶类的影响
- 腧穴教学中6种记忆法的应用
- 针灸临床思维模式初探
- 金津玉液放血治疗急性扁桃体炎
- 针刺大肠俞治疗股神经痛26例
- 足三里穴位注射治疗哮喘60例
- 涌泉小切口割治治疗颈淋巴结核64例
- 针刺为主治疗踝关节骨折术后功能障碍
- 长圆针治疗腰椎骨痹60例
- 电针治疗原发性视网膜色素变性65例
- 中药穴位敷贴天突治疗急性咽炎
- boil down to
- boil down to/come down to
- boil down to sth
- boiled
- boiled over
- boiler
- boilerless
- boilerplate
- boiler room
- boilerroom
- boilers
- boiler suit
- boilersuit
- boiler suits
- boilersuits
- boiling
- boiling/boiling hot
- boiling hot
- boilingly
- boiling over
- boiling point
- boiling-point
- boilingpoint
- boiling points
- boiling/roasting
- 烂船还有三千钉
- 烂船还有三斤钉
- 烂芝麻
- 烂花
- 烂花花
- 烂若
- 烂若披掌
- 烂若披锦
- 烂若舒锦
- 烂草绳绊倒了癞象
- 烂萝卜——没有头儿
- 烂蒸
- 烂蒸去毛,莫拗折项
- 烂衫
- 烂袜子改背心——小人得之(志)
- 烂襟襟衣不蔽体
- 烂谷
- 烂败
- 烂账
- 烂货
- 烂贱
- 烂赌
- 烂赏
- 烂辉辉
- 烂边礼帽——顶好