侯昶宇
【摘要】 本文主要讨论java实现声音识别程序,采用mfcc参数提取以及混合高斯模型方法。使用mfcc处理声音得到音频的特征参数后,通过混合高斯模型建模实现对音频的判别。最终通过JNI方法将windows下程序移植到Android端下运行。
【关键词】 梅尔倒谱系数 混合高斯模型 目标识别
一、背景及应用
对于声音识别技术来说,由于不需要过多接触以及实体间交互模式的认证,因此,它在使用中比其他种类的识别技术更加便利。而在配置过程中,由于当前多数电子数码产品都已经安装了声卡和话筒,因而构架上也可以节约更多的成本。此外,对于使用环境来说,由于不需要如视频监控设备那样对角度有着较高的要求,所以声音识别系统的使用环境无疑也会更加的随意和隐蔽。这些都是声音识别系统与其他安防设施相比更加独特的优势。
除了常见的安防系统应用以外,其实日常生活中一些身份识别也采用声音识别模式。现在,很多银行都采用了声音识别的模式进行保险箱的控制;或者在一些远程的服务中,也采用声音识别的模式,对客户的身份进行定位。此外,作为智能化技术的重要一环,声音识别同样可以用于智能家电。尽管这种全新的模式在短时间之内普及,无论是在技术上还是理念上都会遇到不小的阻力。但从长远来看,这种技术的出现以及民用化的普及,对于未来实现个人信息的全方位保护将起到标志性作用。
二、声音识别程序概述
首先将音频文件读作浮点数数组指针采样点,之后将数组建立混合高斯模型,再将读取的结果和已经保存的混合高斯模型做比较,从而得出与高斯模型中最接近的结果。
2.1高斯模型
高斯模型就是用高斯概率密度函数(正态分布曲线)精确地量化事物,将一个事物分解为若干基于高斯概率密度函数(正态分布曲线)形成的模型。
2.2统计学习模型
我们常用所谓统计模型的学习分为概率模型和非概率模型。概率模型指的是模型训练方式为P=(Y|X)的类型。输入X后得到的不是具体值,而是一系列的概率,我们选取概率最大的作为判决对象。与之相对的,非概率模型的形式是y=f(x)。输入x后得到唯一结果y,并以其作为判决对象。
2.3梅尔频率倒谱系数
由于不同的人有不同的特异性特征,所以先采用预加重技术,即插入一个高通滤波器,从而加强声道部分特征。高通滤波的传递函数如下:
H(Z)=1-αZ-1
因声音在短时间内呈现平稳性,所以之后进行分帧和加窗。同时为了避免丢失信息,相邻帧之间还应存在重叠。
再对分帧加窗后的各帧信号进行FFT变换得到各帧的频谱。并对语音信号的频谱取模平方得到语音信号的功率谱。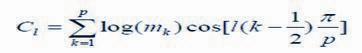
最终通过滤波和离散余弦变换得到的Ci即为所需提取的特征参数。
2.4混合高斯模型的建立
建立混合高斯模型,及对样本的概率密度分布进行估计,估计采用的模型是几个高斯模型的加权和,每个高斯模型作为一个类,将样本数据分别投影到几个高斯模型时,就能得到在各个类上的概率。最终选取概率最大的类作为判决结果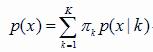
上式中,K卫模型个数,πk为第k个高斯模型的权重,p为第k个高斯模型的概率密度。求出p(x)后,求和的各项结果分别代表x属于各个类的概率。
通过上述方法,可以进行训练在资料库中加入新的声音训练得到的gmm模型,还可以通过与已知的gmm模型进行比对从而识别声音种类。
三、Android实现
Android上层的Application和Application Framework都是使用Java编写,底层包括系统和使用众多的LIiraries是C/C++编写的。所以上层Java要调用底层的C/C++函数库必须通过Java的JNI来实现。
在进行JNI操作时,首先,使用eclipse得到一个app文件,此处,eclipse会自动编译此java文件。编译后的文件在bin目录下,通过javah命令生成一个c++的头文件。在根据这个头文件编写c++程序。将windows下运行成功的程序中的函数编译为.so文件作为java编译时的库函数。在进行java编程时,只需要对c++函数进行合理调用即可。
四、实验结果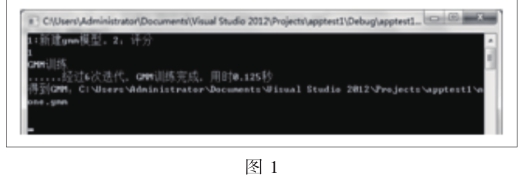
通过六次迭代后得到gmm模型并添加进数据库,见图1。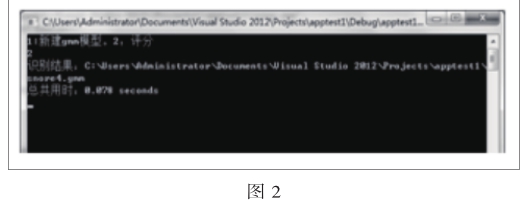
得到gmm模型后與数据空内已有模型进行比较,从而选出最接近的声音是已有声音模型中的一个,见图2。
在Android端实现声音识别, 见图3。
四、总结
一个完整的声音识别模块应该有一下几部分组成:前段处理、声音建模、声音数据库、匹配判决。根据以上流程,本文所设计的声音识别程序从过mfcc对声音进行处理,之后建立高斯混合模型,在添加足够的声音种类进入数据库后可以对声音进行识别。通过JNI方式移植到java平台后,使其应用更加广泛。
参 考 文 献
[1] C library for computing Mel Frequency Cepstral Coefficients (MFCC)
[2] Freeman H. On the Encoding of Arbitrary Geometric Configurations. IRE Trans. Electronics and Computers, 1961, 10:260-268
[3] Ballard D H. Generalizing the Hough Transform to Detect Arbitrary Shapes [J]. Pattern Recognition, 1987, 13(81):111-122.
- 高校教师政治理论学习调查与对策初探
- 转型发展背景下地方本科高校的教师队伍建设
- 小学数学教师基础素养培养研究
- 创新创业教育背景下 通信原理课程改革与实践
- 翻转课堂教学模式在医学教育中的现状研究
- 高职院校空中乘务专业人才培养方案建设初探
- 机场工程试验中心信息化管理系统的开发探索
- 机械专业对口学生人才培养研究
- 数理类专业“理工融合”人才培养路径探索与实践
- CDIO模式下高职工程造价专业创新 创业意识和能力培养课程体系重构
- 基于SPSS的军校学员综合素质评价分析研究
- 论培养法语研究生科研创新能力的途径
- 初探病理切片技术 在病理解剖学实验教学中的应用
- 浅谈医学生科学素养的培养
- 基于TEE-CDIO理念的新工科毕业设计改革研究
- 高职院校邮政通信管理专业 人才需求现状及培养策略
- 问题规约法在解决刚体动力学问题中的应用
- “00后”大学生的网络认识及利用状况调查
- 城区公共自行车投放和使用状况调查与分析
- 医学院校大学生创新创业训练 计划项目实施效果调查分析
- 高校创建学生公寓“党员工作站”的实践与思考
- 应对方式对职校生网络使用的影响
- 提升研究生就业能力的对策研究
- “机械测试技术”实验教学改革尝试
- 高职“工程材料”课程改革实践探索
- be in danger
- be in debt
- be indebted to
- be in demand
- be independent/lead an independent life
- be indicative of
- be in dire straits
- be in doubt
- be in earnest
- be in fashion
- be infatuated
- be in favour
- be in favour of
- (be) in favour (of sb/sth)
- be infected with
- be in flames
- be in flux/be in a state of flux
- be in for
- be-in-for
- be in full swing
- being
- being-as
- being-as-how
- beingness
- be in good condition
- 淫辞邪说
- 淫辟
- 淫辱
- 淫辱妇女
- 淫迷
- 淫逸
- 淫逸,纵欲放荡
- 淫遊
- 淫道
- 淫邀艳约
- 淫邪
- 淫邪之声
- 淫邪的乐声
- 淫邪的欲望
- 淫酒
- 淫酗
- 淫醟
- 淫长
- 淫隈
- 淫雨
- 淫雨成灾
- 淫雨连绵
- 淫雨霏霏
- 淫霖
- 淫靡