徐宏博+赵文涛+孟令军

摘要:中文分词方法都属于串行分词方法,不能处理海量数据。提出一种基于MapReduce的并行分词方法。Mapreduce编程模型默认使用TextInputFormat文本输入方式,该方式不适合处理大量文本文件。首先基于CombineFileInputFormat父类,自定义文本输入方式MyInputFormat,并在实现createRecordReader方法过程中返回RecordReader对象。其次自定义MyRecordReader类来说明读取文本
关键词:MapReduc;分片;TextInputFormat;CombineFileInputFormat
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)22-0171-05
Abstract: Method of word segmentation is a serial process and it fails to deal with big data. We put forward a parallel word segmentation based on MapReduce. TextInputFormat is the default input class when preprocessing in the programming model of Mapreduce, while it fails to process datasets which is made up of many small files. Firstly, we define a new class named MyInputFormat based on the class of CombineFileInputFormat,and return an object of RecordReader class. Secondly, we declare MyRecordReader class , by which can we write a new logic method to read and split the original data to
Key words: MapReduce; split; TextInputFormat; CombineFileInputFormat
中文分词是中文文本处理的基础, 具有十分重要的理论和应用意义[1]。目前中文分词算法主要有3类:基于词典的分词方法,基于概率的分词方法和基于人工智能的分词方法。国内一些大的科研机构都对中文分词做了研究工作,比如,北京航空航天大学计算机系于设计实现CDWS中文分词系统[2],中国科学院组织开发了基于多层隐马尔科夫模型ICTCLAS分词系统[2]。国外成熟的中文分词工具包是IKAnalyzer,它是一个开源基于JAVA语言的轻量级的中文分词第三方工具包[3],采用了特有的“正向迭代最细粒度切分算法”,支持细粒度和智能分词两种切分模式。IKAnalyzer是以开源项目Lucene[4]为应用主体的,结合词典分词和文法分析算法的中文分词组件。Lucene是Apache基金会下的一个非常优秀的全文检索工具软件包,它可以嵌入在Java系统中,通过建立倒排链表结构,建立索引实现信息检索,具有高性能、可扩展的特点。
但是这些分词方法都是传统的串行分词方法,不足以处理海量数据,例如微博数据[5],它是一种社会化媒体,包含了丰富的特征信息,具有规模大、实时性强、内容口语化、特征属性多和噪声大等特征[6]。
由Google实验室提出的Mapreduce并行分布式计算模型主要针对海量数据的处理,它能组织集群来处理大规模数据集,成为云计算平台主流的并行数据处理模型[7-8]。本文基于Mapreduce框架,通过结合使用IKAnalyzer和Lucene实现并行分词。
Mapreduce框架中默认使用TextInputFormat文本输入方式[8],该方式的对行文本的切分方法不适合处理由大量小文本组成的文件。本文基于CombineFileInputFormat父类,自定义文本输入方式MyInputFormat,继承父类getSplits方法,重写isSplitable方法,并通过定义MyRecordReader类实现createRecordReader方法,改进文本分片切割方式。实验证明,基于改进后的MyInputFormat文本切片方式比默认的TextInputFormat切片方式,更能高效地处理大量文本文件。
1 相关工作
1.1 MapReduce实现框架
MapReduce是一种分布式开发的编程模型[9-10],用户可以根据多种语言来进行应用程序的编写。它提供了简洁的编程接口,底层框架可以自动并行化基于这些接口开发的程序。由于用户不需要处理与并行化相关的工作,可以其中精力编写业务逻辑,开发效率较高。
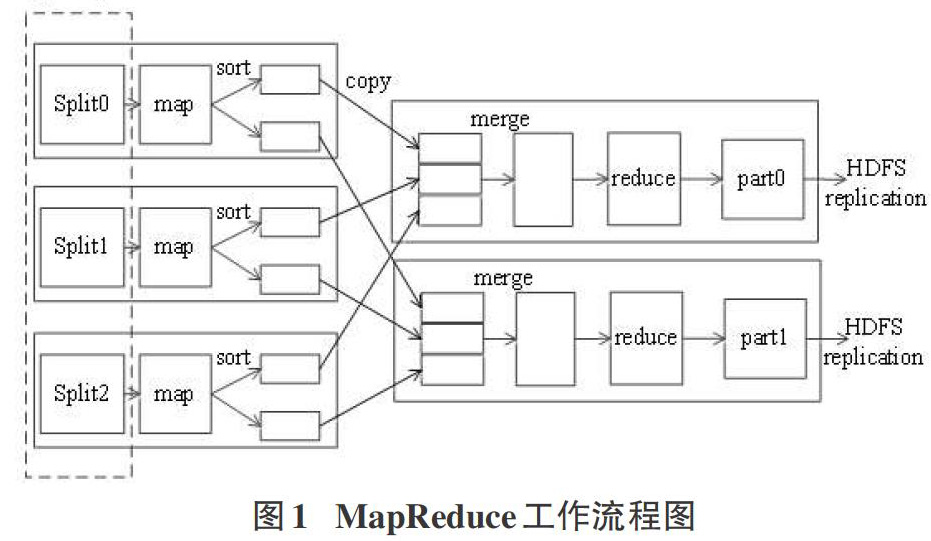
MapReduce作为Hadoop的核心计算模型[11-13],它通过将输入数据切割为若干个InputSplit来实现并行化。其工作流程如下图1所示:
1.2 默认TextInputFormat输入方式实现并行分词
InputFormat类是MapReduce框架中输入方式的最顶级的抽象类,该类从两个不同的角度设定定义了getSplits和createRecordReader两个方法。 getSplits方法负责切分输入文件,它把很多的输入文件切割成很多的输入分片InputSplit,每个InputSplit分片都将被交给一个单独的Mapper处理; createRecordReader方法提供了一个RecordReader对象,该对象从InputSplit分片中解析出
FileInputFormat抽象类继承于InputFormat类,用来专门处理文件类型的数据。该类只实现了getSplits方法,并没有实现createRecordReader方法。getSplits方法返回的分片类型是FileSplit。FileInputFormat在默认情况下为文件在HDFS上的每一个block(128MB)都生成一个分片,可以通过设置作业的配置参数mapred.min.split.size和mapred.max.split.size来设置分片大小的最小值和最大值,但是一个分片只能包含来自于一个文件的block。
TextInputFormat 类继承于FileInputFormat类,是MapReduce框架默认的文件输入格式。它继承了父类getSplits方法。因此,它的分片内容只能来自于一个文件的block。如果输入文件有上万个,那么就会产生上万个分片,进而需要调用至少上万个Mapper,这对于大量小文件而言是工作效率极其低下。该类实现了createRecordReader方法,该方法返回的是lineRecordReader对象,该对象将输入数据每行都解析成一条
每个分片都只包含来自于一个文件的block。每个split分片都将交由Mapper处理,Mapper端的run方法通过调用TextInputFormat方法中返回的lineRecordReader对象,将分片解析成
2 改进数据输入方式实现并行分词
TextInputFormat的切分方法默认情况下为文件在HDFS上的每一个block(128MB)都生成一个分片,并且一个分片包含的block只能来自一个文件。当数据集由大量的小文件组成时,这种输入格式是极其低效的。
2.1 自定义MyInputFormat类
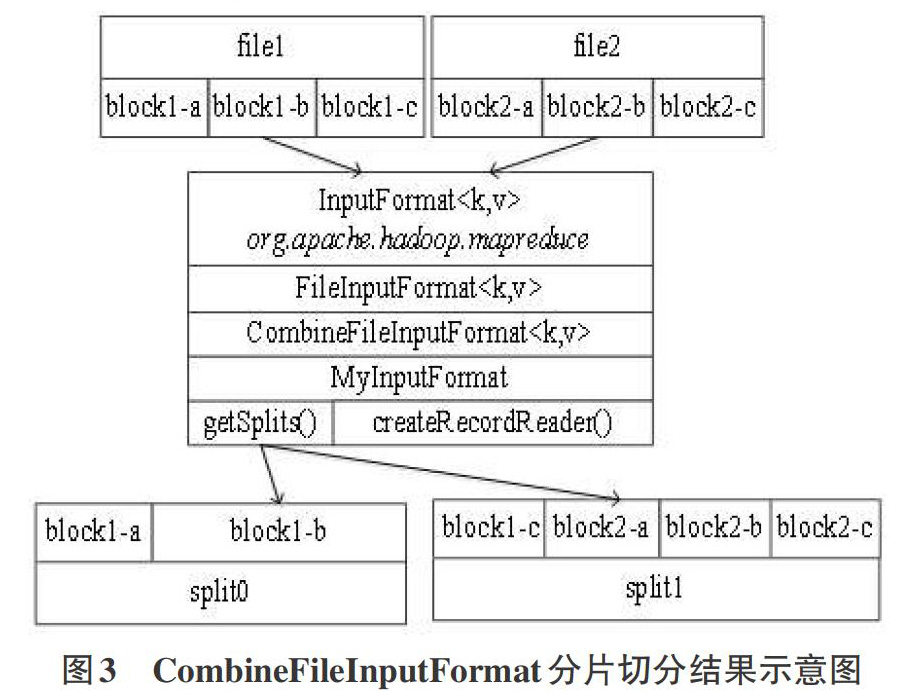
首先,自定义继承于CombineFileInputFormat抽象类的MyInputFormat类。CombineFileInputFormat类继承于FileInputFormat类,它重载父类的getSplits方法,返回的分片类型是CombineFileSplit。CombineFileSplit类中定义的paths数组用来记录每一个文件的路径,即它可包含多个文件的路径,这是与TextInputFormat类在分片逻辑上的最大不同之处。MyInputFormat继承父类的getSplits方法,使得一个分片可以包含多个文件的block内容。假如file1,file2两个文件各有3个数据块组成,则这两个文件的切分结果示意图如图3所示:
其次,MyInputFormat重载父类的isSplitable方法,返回false值来保证文件不被分割。
第三,MyInputFormat实现父类createRecordReader方法并返回CombineRecordReader对象,在该对象类的构造函数中,定义MyRecordReader来处理分片内的每个文件。输出的每条
2.2 自定义MyRecordReader类
CombineFileRecordReader是Hadoop中继承于RecordReader的可以遍历包含多个文件的分片内容的框架[9],在其构造函数的中声明自定义MyRecordReader类来说明将文件解析成
首先,在MyRecordReader类中,定义的变量如表1,重载的方法如表2:
其中,nextKeyValue方法是将文件解析成
2.3 自定义并行分词MyMapper类
Mapper端的run方法通过调用MyInputFormat方法中返回的MyRecordReader对象,将分片解析成
MapReduce最终实现文本文件的分词。文本分词是特征项提取中最关键的一步,鉴于中英文编码格式的不同,两者的分词格式也不一样,本文结合使用IKAnalyzer2012和Lucene实现分词。设置输出Key为输入Key,定义StringBuilder对象存储分词结果,并作为输出Value.
由于自定义的MyRecordReader的解析逻辑是将文件的类别作为key,文件内容作为value,因此分词过程只需要经过一个map方法就可以得到结果,MapReduce流程图如下所示:
3 实验
3.1 实验环境
本文实验环境:联想Z470机器,Intel Core i3-2410M,2.3 GHz CPU,2GB内存,200 GB硬盘,Windows xp 操作系统, JAVA编程语言,Eclipse-4.3.2开发环境,虚拟机vmware workstation 10,Centos 6.4,jdk1.6.0_24,Apache Hadoop 1.1.2。在单机伪分布式环境下即可证明该实验的有效性,Hadoop具体环境如图7:
3.2 文本数据准备
本文使用的实验数据集是从搜狗实验室提供的中文文本分类语料库(http://www.sogou.com/labs/dl/c.html),该库提供有mini版,精简版和完整版的文本预料库。在精简版中包含共计9个类别,每个类别含1990篇文章,从精简版数据集中选择不同数量的文本组成大小不同的数据集,具体数据集信息如下表:
3.3 并行分词
步骤1:分别将在Eclipse上编写的两种并行分词程序打成jar包,使用TextInputFormat方式的jar包命名为TextInputFormat.jar,使用MyInputFormat方式的jar包命名为MyInputFormat.jar,并都存放在/usr/local/目录下;
步骤2: 在终端执行命令”hadoop fs –put /usr/local/sogou /sogou”将数据集上传至hadoop的sogou目录下;
步骤3: 在终端执行命令
”hadoop jar /usr/local/TextInputFormat.jar /usr/local/sogou /sogou /usr/local/sogou /seg1”对数据集按照TextInputFormat方式并行分词;
步骤4: 在终端执行命令
”hadoop jar /usr/local/MyInputFormat.jar /usr/local/sogou /sogou /usr/local/sogou /seg2”对数据集按照MyInputFormat方式并行分词;
4 结果对比与分析
4.1 分词结果对比
在刚开始执行时,记录job总共的Input Paths,并通过web界面(mlj:50030)查看job的工作状态,记录Job运行时间,实验结果如下表4:
图7是两种输入方式并行分词时间对比柱状图,横坐标表示数据集,纵坐标表示运行时间,由于两种方式花费时间相差较大,纵坐标采用对数坐标。由图7可知,运行时间与数据集的大小成正相关,体育和军事数据集花费时间增加相对较少,说明Hadoop更能处理较大的数据。
4.2 结果分析
默认输入方式对输入数据产生至少与文件个数相等的分片,每个数据分片都交给一个Mapper处理,而且在进行过map之后需要合并到reduce端,这会大大增加网络拥堵。因为每个Job从建立、 处理、 提交到写到本地都需要一定的时间,并且在单机环境下只有一个Mapper, 它只能顺序地执行每一个Job。这样分片的数目越多,Job需要花费的时间也就越长。因此处理大量小文件的速度就会非常慢。
而MyInputFormat文件输入格式则将所有文件作为一个分片进行处理,输入方式则允许一个分片包含多个文件块,大大减少了Map个数,并且改进后并不需要reduce合并处理,省去了建立多个Job所消耗的时间,这大大提高了并行分词的效率。
5 结束语
由于Mapreduce默认的TextInputFormat输入方式非常不适合处理大量小文件组成的数据。本文首先基于CombineFileInputFormat父类,自定义文本输入方式MyInputFormat,继承父类getSplits方法,重载父类的isSplitable方法保证文件不被分割,并在重载createRecordReader方法时返回一个CombineFileRecordReader对象。第三,自定义MyRecordReader类,指明解析文件的
参考文献:
[1] 韩冬煦, 常宝宝. 中文分词模型的领域适应性方法[J]. 计算机学报, 2015, 38(2).
[2] 曹勇刚, 曹羽中, 金茂忠, 等. 面向信息检索的自适应中文分词系统[J]. 软件学报, 2006, 17(3).
[3] 中文分词库 IKAnalyzer[EB/OL].http://www.oschina.net/p/ikanalyzer/.
[4] Apache Lucene [EB/OL].http://lucene.apache.org/.
[5] 张晨逸, 孙建伶, 丁轶群. 基于MB_LDA模型的微博主题挖掘[J]. 计算机研究与发展, 2011, 48(10).
[6] 申国伟,杨武,王巍,于淼.面向大规模微博消息流的突发话题检测[J].计算机研究与发展, 2015, 52(2).
[7] 王晓华. MapReduce 2.0源码分析与编程实战[M]. 北京: 人民邮电出版社, 2014.
[8] 应毅,刘亚军. MapReduce 并行计算技术发展综述[J].计算机系统应用,2014,23(4).
[9] Eric Sammer.Hadoop技术详解[M]. 刘敏, 麦耀锋, 李冀蕾,等,译.北京:人民邮电出版社, 2013.
[10] Chuck Lam.Hadoop实战[M]. 韩冀中,译.北京:人民邮电出版社, 2011.
[11] Boris Lublinsky,Smith K T, Alexey Yakubovich. Hadoop高级编程[M]. 穆玉伟, 靳晓辉,译. 北京: 清华大学出版社, 2014.
[12] Owens J R, Jon Lentz, Brian Femiano. Hadoop实战手册[M]. 傅杰, 赵磊, 卢学裕,译. 北京: 人民邮电出版社, 2014.
[13] 张红蕊, 张永, 于静雯. 云计算环境下基于朴素贝叶斯的数据分类[J]. 计算机应用与软件, 2015, 32(3).
- 浅谈英语社团活动对英语口语教学的作用
- 分层教学法在初中英语教学中的应用
- 初中英语口语教与学的方法浅探
- 初中英语听力训练教学反思
- 初中英语读写结合教学优化策略探究
- 浅谈英文歌曲对英语教学的作用
- 小学英语渗透数学多元化教学策略探讨
- 基于核心素养的高中英语阅读教学探究
- 任务型教学法在初中英语复习课中的应用
- 探析英语口语教学活动的组织策略
- 体验式教学对初中英语阅读教学改进的探究
- 语境理论下的初中英语阅读教学策略
- 新课标下提高学生英语学习兴趣的实践研究
- 以读促写背景下的初中英语写作教学有效性探究
- 新课程背景下高中英语合作学习研究
- 思维导图在高中英语阅读教学中的应用及探究
- 任务型教学法在高中英语阅读教学中的有效应用
- 词汇组块化在初中英语任务型阅读中的应用
- 初中英语学科教学中学生核心素养的培养方法浅谈
- 以阅读文本为基础的初中英语写作教学策略
- 高中英语学习方式优化研究
- 高中英语阅读教学中批判性思维培养的探究
- 优化高中英语词汇检测的策略研究
- 新形势下开展好初中英语教学的策略探究
- 论分层教学模式在初中英语写作教学中的应用
- stakes
- stake sth on
- stake sth out
- stake sth ↔ out
- stake your claim
- stake²
- stake¹
- staking
- stalactital
- stalactite
- stalactited
- stalactites
- stalactitically
- stalagmite
- stalagmites
- stalagmitically
- stale
- staled
- stalely
- stalemate
- stalemated
- stalemates
- stalemating
- staleness
- stalenesses
- 黝蔼
- 黝贲
- 黝赤
- 黝面
- 黝颜
- 黝驹
- 黝黑
- 黝黑黝葱
- 黝黝
- 黝黭
- 黝黯
- 點
- 黟
- 黟山
- 黟然
- 黟黑
- 黟黟
- 黠
- 黠人
- 黠健
- 黠卒
- 黠小
- 黠巧
- 黠悍
- 黠惠