黄楠

摘要:本文从节约成本和简化搭建过程出发,介绍了通过VMware Workstation和CentOS 6.5在单机环境下,搭建分布式Hadoop集群的方法,并给出了详细的搭建步骤,最后对搭建好的平台进行了测试,测试结果表明建立在虚拟机上的Hadoop集群已经可以正常运行,可在上面进行实验和应用开发。
关键词:Hadoop;VMware;虚拟化
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)25-0175-06
1 概述
目前,大数据已经成为研究的热点,大数据的解决方案种类繁多,其中Hadoop作为 Apache基金会的一个开源项目,已经积累了大量用户,在业界也得到了广泛的认可,一些知名企业如百度、阿里巴巴、 谷歌、腾讯和facebook等,纷纷将 Hadoop应用于商业领域。传统的Hadoop集群是基于物理节点搭建的,虽然理论上组建一个 Hadoop集群不需要昂贵的高性能计算机,仅需一些廉价的计算机即可[1,2],但如采用传统技术搭建Hadoop集群,就不得不面对一些问题:①构建集群需要大量的物理设备以及足够的实验场地②物理机的性能得不到充分利用;③基于物理机的Hadoop集群组建后,如需增加节点,就要增加新的物理机,需要更大的场地,而且集线器、交换机等物理设备也要相应增加,布置起来比较错综复杂。面对这些问题,如何在?本文对这个问题进行探讨,介绍一下在单机环境中,使用VMware Workstation 10和CentOS 6.5搭建Hadoop分布式集群并进行简单的测试。
2 Hadoop简介
Hadoop是一种分析和处理大数据的软件平台,是Apache的一个用Java语言所实现的开源软件框架,在大量计算机组成的集群当中实现了对海量数据进行分布式计算。Hadoop的框架最核心的设计就是:HDFS和MapReduce,HDFS为海量的数据提供了存储,而MapReduce为海量的数据提供了计算。大数据在Hadoop处理的流程可以参照图1来进行理解:数据是通过Hadoop的集群处理后得到的结果。[3]
Hadoop的集群主要由 NameNode,DataNode,Secondary NameNode,JobTracker,TaskTracker组成,如图2所示:
NameNode:记录文件是如何被拆分成block以及这些block都存储到了那些DateNode节点,同时也保存了文件系统运行的状态信息。
DataNode:存储被拆分的blocks。
Secondary NameNode:帮助NameNode收集文件系统运行的状态信息。
JobTracker:当有任务提交到Hadoop集群时,负责Job的运行,负责调度多个TaskTracker。
TaskTracker:负责某一个map或者reduce任务。
3 搭建Hadoop虚拟实验平台
3.1准备与安装环境
服务器准备:安装虚拟机和linux,虚拟机推荐使用vmware;PC可以使用workstation,配置低的话可选择Cygwin,模拟linux环境;服务器可以使用ESXi,在管理上比较方便。ESXi还可以通过拷贝镜像文件复制虚拟机,复制后自动修改网卡号和ip非常快捷。 如果只是实验用途,硬盘大约预留20-30G空间。
操作系统:CentOS 6.5 ,分区可以选择默认,安装选项默认即可,注意选项里应包括ssh , vi (用于编辑配置文件) , perl等(有些脚本里包含perl代码需要解析)。
JAVA环境:到Oracle官网下载java jdk安装包,并且进行安装。
3.2实验环境
硬件环境:Vmware 10 ,三台Linux虚拟机:CentOS 6.5, 安装介质:cdh5.4.0。
三台虚拟机配置如表1:
3.3安装与配置三台虚拟机
3.3.1准备三台虚拟机
打开虚拟软件VMware WorkStation。
点击“文件”->“打开”,找到虚拟机所在目录,打开装有CentOS6.5的虚拟机。
通过克隆生成新的虚拟机,如图3。
3.3.2操作系统网络配置
确认三台虚拟机为不同MAC地址,选择“NAT模式”的网络连接方式,如图4。
打开虚拟机,按照表1设置IP地址,然后通过“ifconfig”命令查看网络地址,如图5。
设置完后,root用户用“service network restart”命令重启网络。
根据表1修改三台主机的主机名,修改后系统需重新启动,编辑/etc/sysconfig/network,HOSTNAME=master或slave。
修改/etc/hosts,所有主机添加如下内容:
192.168.xx.101 master
192.168.xx.102 slave1
192.168.xx.103 slave2
3.3.3 ssh无密码登录配置
三台主机确保关闭防火墙,#chkconfig iptables,#services iptables stop。
关闭SElINUX,修改/etc/selinux/config中的SELINUX=””为disable。
在所有主机生成密钥并配置SSH无密码登录主机
#ssh-keygen -t rsa
在master生成认证文件,然后授权并将文件拷贝到slave1
#cat ~/.ssh/id_rsa.pub >>~ /.ssh/authorized_ keys
# chmod 600 authorized_keys
#scp ~/.ssh/authorized_ keys slave 1:~/.ssh/
在slave1上添加公钥信息,然后授权并将文件拷贝到slave2
#cat ~/.ssh/id_rsa.pub >>~ /.ssh/authorized_ keys
# chmod 600 authorized_keys
#scp ~/.ssh/authorized_ keys slave 2:~/.ssh/
在slave2上添加公钥信息,然后授权并将文件拷贝到master和slave1
#cat ~/.ssh/id_rsa.pub >>~ /.ssh/authorized_ keys
# chmod 600 authorized_keys
#scp ~/.ssh/authorized_ keys master:~/.ssh/
#scp ~/.ssh/authorized_ keys slave 1:~/.ssh/
测试是否实现三台主机间的无密码登录
#ssh master
#ssh slave1
3.3.4 配置JAVA环境
三台主机分别上传jdk文件到桌面并执行配置
mkdir /usr/java
mv ~/Desktop/jdk-7u71-linux-x64.gz /usr/java/
cd /usr/java
tar -xvf jdk-7u71-linux-x64.gz
在master配置环境变量,在/root/.bashrc文件添加如下内容
export JAVA_HOME=/usr/java/jdk1.7.0_71
export PATH=$PATH:$JAVA_HOME/bin
生效并发送到另外两台主机
#source .bashrc
#scp .bashrc slave1: ~
#scp .bashrc slave2: ~
验证
#java -version
3.3.5配置集群时间同步
选择master作为时间同步服务器,修改master的/etc/ntp.conf,添加
restrict 192.168.x.O mask 255.255.255.0 notrap nomodify
server 127.127.1.0 #local clock
启动服务
#service ntpd start
#chkconfig ntpd on
在slave1和slave2上添加定时任务,执行#crontab -e命令,添加如下内容
0 1 * * * root /usr/sbin/ntpdate master >> /root/ntpdate.log 2>&1
3.3.6 配置yum源
设置虚拟机master,使用ISO镜像文件,如图6。
在master上挂载光驱
#mkdir /media/cdh5
#mount -o loop -t iso9660 /dev/cdrom /media/cdh5
在master上创建文件/etc/yum.repos.d/cloudera-cdh5.repo,添加
[cloudera-cdh5]
name=Clouderas Distribution for Hadoop, Version 5
baseurl=file:///media/cdh5/cdh/5.4.0/
gpgcheck=O
enabled= 1
在slave1和slave2上创建文件/etc/yum.repos.d/cloudera-cdh5.repo,添加
[cloudera-cdh5]
name=Clouderas Distribution for Hadoop, Version 5
baseurl=http://master/media_cdh5/cdh/5.4.0/
gpgcheck=O
enabled= 1
在master上启动web服务
#service httpd start
#chkconfig httpd on
在master上创建相应软连接并测试
#ln -s /media/cdh5 /var/www/html/media_cdh5
#yum clean all
#yum list |grep hadoop-hdfs
3.3.7安装HDFS
在master上安装
yum install -y hadoop hadoop-hdfs hadoop-client hadoop-doc \
hadoop-debuginfo hadoop-hdfs-namenode \
hadoop-hdfs-secondarynamenode
在slave1和slave2节点上安装
yum install -y hadoop hadoop-hdfs hadoop-client hadoop-doc \
hadoop-debuginfo hadoop-hdfs-datanode
3.3.8安装YARN
在master上安装
yum install -y hadoop-yarn hadoop-yarn-resourcemanager
在slave1和slave2节点上安装
yum install hadoop-yarn hadoop-yarn-nodemanager hadoop-mapreduce -y
3.3.9配置HAdoop环境变量
在master配置环境变量,在/root/.bashrc文件添加如下内容
#HADOOP
export HADOOP_HOME=/usr/lib/hadoop
export HADOOP_HDFS_HOME=/usr/lib/hadoop-hdfs
export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=/usr/lib/hadoop-yarn
export HADOOP_LIBEXEC_DIR=${HADOOP_HOME}/libexec
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
执行如下命令使配置生效,并发送到slave1和slave2
#source .bashrc
#scp .bashrc slave1: ~
#scp .bashrc slave2: ~
Hadoop有两类重要的配置文件:
只读默认的配置文件:core-default.xml, hdfs-default.xml, yarn-default.xml,mapred-default.xml。
手工配置文件($HADOOP_HOME/etc/hadoop/目录下): core-site.xml,hdfs-site.xml,yarn-site.xml, mapred-site.xml。
另外,还有几个重要的Hadoop环境配置文件:yarn-env.sh,slaves。
在master上修改yarn-env.sh和slave文件,配置yarn的运行环境
#vi $HADOOP_HOME/etc/hadoop/yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_71/
#vi $HADOOP_HOME/etc/hadoop/slaves
slave1
slave2
修改core-site.xml文件
#vi $HADOOP_HOME/etc/hadoop/core-site.xml
修改hdfs-site.xml文件
#vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
在master节点手动创建dfs.namenode.name.dir的本地目录
#mkdir -p /data/dfs/nn
在slave1和slave2节点手动配置创建dfs.datanode.data.dir的本地目录
#mkdir -p /data/dfs/dn
在所有主机上修改所有者权限
#chown -R hdfs:hdfs /data/dfs
下面列出一些需要关注的资源分配参数,如表2。
配置yarn-site.xml文件
增加
修改
配置mapred-site.xml
复制配置到其他节点,复制.bashrc和hadoop配置文件到slave1和slave2
#scp .bashrc slave1: ~
#scp .bashrc slave2: ~
#scp -r /etc/hadoop/conf slave1:/etc/hadoop/
#scp -r /etc/hadoop/conf slave2:/etc/hadoop/
在master节点上进行格式化
#sudo -u hdfs hadoop namenode –format
3.3.10启动HDFS集群
在master上启动
#service hadoop-hdfs-namenode start
#service hadoop-hdfs-secondarynamenode start
在slave1和slave2上启动
#service hadoop-hdfs-datanode start
通过jsp命令查看进程,确认HDFS集群是否成功启动
登录web控制台,查看HDFS集群状态,http://192.168.6.101:50070,如图7
3.3.11创建HDFS目录
创建/temp临时目录,并设置权限为1777
#sudo –u hdfs hadoop fs –mkdir –p /tmp/hadoop-yarn
#sudo –u hdfs hadoop fs –chmod –R 1777 /tmp
创建/user用户目录,并设置权限为777
#sudo –u hdfs hadoop fs –mkdir /user
#sudo –u hdfs hadoop fs –chmod 777 /user
创建yarn.nodemanager.remote-app-log-dir目录
#sudo –u hdfs hadoop fs –mkdir –p /var/log/hadoop-yarn/apps
#sudo –u hdfs hadoop fs –chown yarn:mapred /var/log/hadoop-yarn/apps
#sudo –u hdfs hadoop fs –chmod 1777 /var/log/hadoop-yarn/apps
#sudo –u hdfs hadoop fs –chmod 1777 /tmp/hadoop-yarn
3.3.12启动YARN集群
在master上启动
#service hadoop-yarn-resourcemanager start
在slave1和slave2上启动
#service hadoop-yarn-nodemanager start
通过jsp命令查看进程,确认YARN集群是否成功启动
通过Web控制台,查看ResourceManager状态,http://192.168.6.101:8088,如图8。
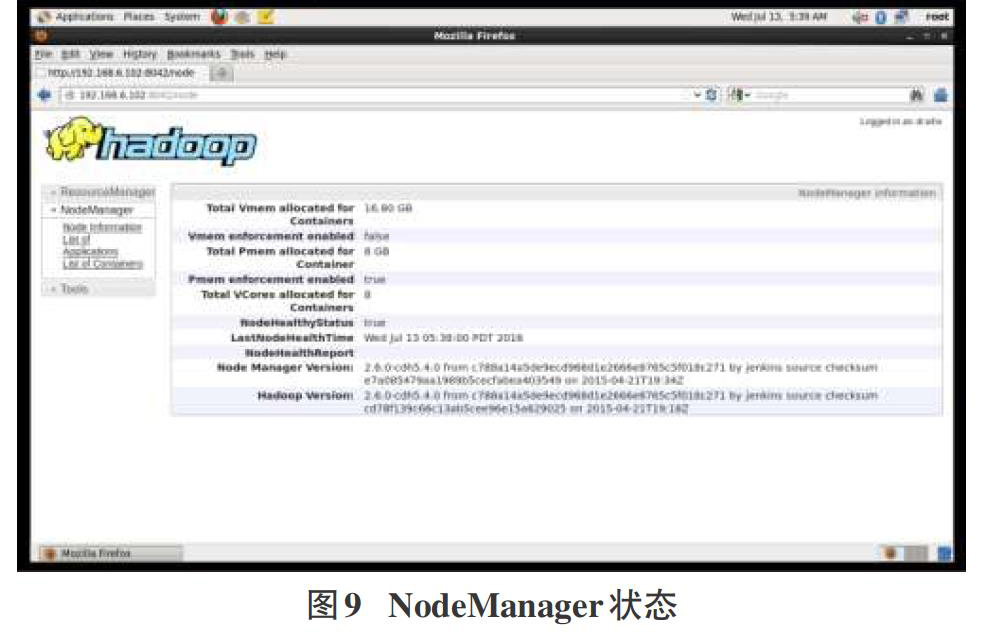
通过Web控制台,查看NodeManager状态,http://192.168.6.102:8042,如图9。
4 测试Hadoop集群
在master上执行
#sudo –u hdfs hadoop fs –mkdir –p /input/wordcount
#mkdir /tmp/input
#echo “hello hadoop hello word xiaonan” > /tmp/input/test1.txt
#sudo –u hdfs hadoop fs –put /tmp/input/*.txt /input/wordcount
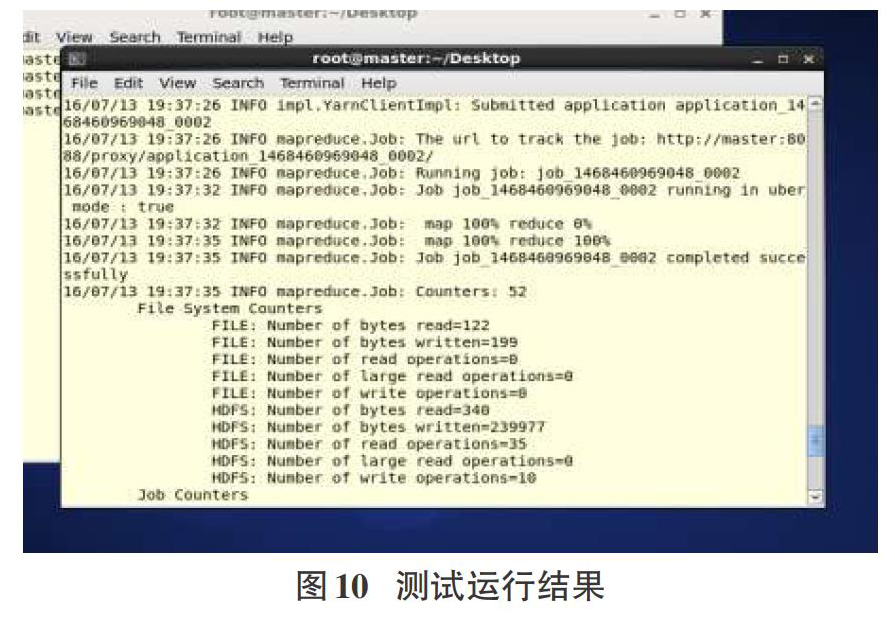
#sudo –u hdfs hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount /input/wordcount /output/wc01
执行结果如图10所示。
5 总结
测试结果显示,建立在虚拟机上的Hadoop集群已经可以正常运行,可在上面进行实验和应用开发。本文从简化搭建过程和充分利用机器性能出发,在单机上通过虚拟化软件,虚拟出三台Linux主机,搭建了分布式Hadoop集群。在搭建过程中,有几点需要注意:虚拟机安装时,就要配置好主机的静态IP和主机名,这样可以方便后面的操作;当安装或运行时发生错误,可以查看相应的log文件,这会对找出问题很有帮助。
参考文献:
[1] 付伟,严博,吴晓平.云计算实验平台建设关键技术研究[J].实验室研究与探索,2013(11):78-81.
[2] 张兴旺,李晨晖,秦晓珠.构建于廉价计算机集群上的云存储的研究与初步实现[J].情报杂志,2011(11):166-171,182.
[3](美)Tom White.Hadoop权威指南[M].2版.周敏奇,王晓玲,金澈清,等.译.北京:清华大学出版社,2011:9-12.
- 中小企业财务管理初探
- 营销人员关键绩效考核指标的设计分析
- 电力企业的会计责任与财务报告的改进分析
- 高校管理会计应用存在的问题及改进建议
- 提高乡镇卫生院会计工作质量的几点认识
- 煤炭企业财务风险控制创新措施探究
- 混合式教学在高职会计专业中应用探析
- 政府会计改革对于医院财务管理的影响研究
- 房地产企业会计内部控制措施探讨
- 浅谈会计核算风险的成因及防范措施
- 经济转型期我国外贸会计发展分析
- 新会计制度对事业单位会计核算的影响
- “互联网+会计”时代高职院校管理会计课程教学改革探究
- 财务会计在现代企业中发展方向的思考
- 论我国高校会计凭证档案信息化管理
- 现代企业内部审计问题及解决措施研究
- 大数据时代助力企业会计发展
- 新时期企业会计核算规范化管理的具体措施探讨
- “互联网+”时代管理会计人员能力分析
- 优化化工企业财务内部控制的措施探讨
- 建筑施工企业参与PPP项目的经济性遴选方案
- 基于胜任素质模型的新型职业农民素质提升路径研究
- 房地产经济与市场经济的协调发展
- 探究我国跨境电子商务的发展模式与策略
- 职业教育与区域经济协调发展研究
- cocreators
- cocultivate
- cocultivated
- cocultivates
- cocultivating
- cocultivation
- cocultivations
- coculture
- cocultured
- cocultures
- coculturing
- cocurator
- cocurators
- cod
- coda
- codable
- codas
- codded
- codding
- code
- coded
- co-defendant
- codefendants
- codeia
- codeias
- 铺搭
- 铺摆
- 铺摊
- 铺撒
- 铺放
- 铺放衬垫
- 铺敦
- 铺文
- 铺晒
- 铺条子
- 铺板
- 铺棻
- 铺植
- 铺模
- 铺殿花
- 铺沙的墓穴
- 铺泛
- 铺派
- 铺海
- 铺潦
- 铺炕
- 铺炕的席
- 铺牌
- 铺班
- 铺琼缀玉