王庆福+王兴国
摘要:互联网时代人们检索信息的方式主要通过搜索引擎完成。不管是通用的全文搜索引擎还是分类别的垂直搜索引擎都需要面临的问题是作弊行为,网站站长会通过多种作弊行为来提高在搜索引擎上的排名,作弊行为的方式也千差万别。搜索引擎需要通过不断优化和完善内部的排序算法来杜绝作弊行为。
关键词:搜索引擎;内容排序;作弊和反作弊
中图分类号: TP391 文献标识码:A 文章编号:1009-3044(2016)15-0202-02
Abstract: In the Internet age, the way of searching information is mainly through the search engine. Whether it is general full text search engine or classification other vertical search engine in the face of problems is cheating, webmaster will through a variety of cheating in the search engine ranking increases, the cheating behavior in different ways. Search engines need to constantly optimize and improve the internal sorting algorithm to eliminate cheating.
Key words: search engine; content ranking; cheating and anti cheating
搜索引擎通过提取网页中主要信息进行索引构建,用户的检索请求提交给搜索引擎后,搜索引擎通过索引系统筛选出符合条件的待选集,然后根据内部的排序算法对待选集进行排序输出。网站的盈利模式主要通过流量,网站流量越大意味着网站可以拉到更到广告投放从而实现大面积盈利。因此存在一些网站站长为了提高自身网站的流量进行作弊,通过非正常的手段来提升自身网站搜索引擎内部的排名,搜索引擎出于公平性的考虑保证排名的合理性需要对网站站长这些作弊行为进行检测并极大程度上降低因作弊行为而导致的排名不正确性。
搜索引擎的排名的依据很大程度上依赖于用户的输入字符串和网站内容的匹配程度,网站站长在自身网站上堆砌大量的关键词从而期望提高网站的排名,实际诸如此类的关键词堆砌没有实际的含义,甚至和网站内容无任何关联,这极大的拉低了网站本身的质量,搜索引擎在内容识别时需要识别当前是否存在无关关键词的大量无关使用,对此类作弊行为需要打压查询字符串和网站本身内容之间的相似度。另外还有如链接作弊等,本文主要就网站作弊中常用手段进行分析,阐释搜索引擎反作弊中常用手段。
1 搜索引擎排序策略
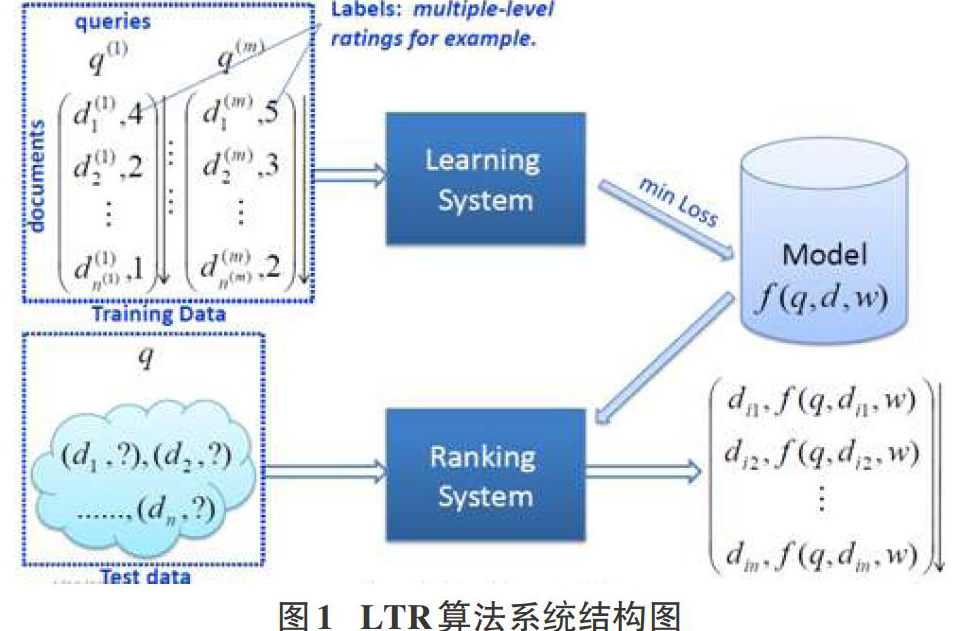
搜索引擎排序中常用的做法是LTR(learning to rank) 算法,LTR算法是一种机器学习算法,它在传统相似度算法的基础上融合多种排序时的相关特征进行排序学习,LTR算法如图1所示。LTR是一种基于有规则性的学习监督(supervised learning)排序方法。LTR已经在诸多领域有着大量的应用,以文本挖掘领域为例,搜索引擎的返回结果排序、IR中召回文档的排序、推荐系统中对候选商品的选择以及机器翻译中文字的顺序等。
早期的信息检索系统在排序时方法比较单一,通常按照用户检索字符串和网页内容的匹配度来排序,这样在很大程度上只能采用单一的相似度计算方式,实际上有多种因素会影响排序的效果,如经典的 TF-IDF, DL等,VSM和布尔模型都可以完成这些功能,这些传统的排序方式是无法融入多种排序因素,假设用向量空间模型来表征对象,向量空间模型中各个维度以TF-IDF来计算权值,相应的无法再利用其他额外的信息了,如果模型参数过多对模型本身的参数调节也是一个很大的挑战,参数过多也会导致过拟合和现象。则自然地联想到采用机器学习的手段来解决上述的问题,于是就产生了LTR(learning to rank)。机器学习很容易拟合多种特征来进行模型训练,而且具有非常丰厚的理论基础,有着成熟的理论和技术来解决稀疏和过拟合的问题。
模型训练的过程实际上一个参数学习的过程,选定合理的真实数据作为训练数据集合,对于特定的模型,选择合适的损失函数,通过对损失函数进行优化可以得到当前模型下最优的参数,这即是模型训练的过程,预测的过程即将需要预测的数据作为输入数据传入到模型得到模型预测分,利用该结果分即可进行相关的排序分析。
LTR一般说来有三类方法:单文档方法(Pointwise),文档对方法(Pairwise),文档列表方法(Listwise)。
2 网站作弊行为
网站站长通过排序作弊的方式来提高自身网站的排名,作弊的方式主要有以下几类:
· 增加目标作弊词词频来影响排名;
· 增加主题无关内容或者热门查询吸引流量;
· 关键位置插入目标作弊词影响排名;
详细来说,可以分为如下几种方式:
2.1关键词重复
关键词重复是作弊中常用的手段,通过设置大量的关键词在网站中。关键词的词频信息是排序时重要的排序因子,关键词重复的本质就是通过关键词的词频来影响网站在展现时的排列顺序。
2.2无关查询词作弊
为了提高网站在搜索时的展现次数,尽可能多的通过增加关键词来提高和用户搜索时的匹配度,作弊时增加很多和当前网站页面主题无关的关键词也是一种词频作弊,即将原来词频为0的单词词频增加为词频大于等于1,通过提高来搜索时的匹配度来吸引流量。
有些网站站长则会在网页的末尾处以隐藏的方式加入一些关键词表,也有一些作弊者在正文内容中插入一些热搜词。更有甚者,有些网站页面的内容完全是采用机器的方式生成毫无阅读性可言。
2.3图片alt标签文本作弊
alt标签作为图片的描述信息,通常不会在用户浏览网页时展示,当用户鼠标点选获得焦点时才会展示,搜索引擎会利用这一信息进行分析,因此部分网站作弊人员会利用这一信息用关键词进行填充,从而达到吸引流量的目的。
2.4网页标题作弊
网页本身的标题信息作为网站内容的重要的组成部分,对于判断一个网页的主题具有非常重要的意义,搜索引擎在计算相似度时增大这一部分的比例,作弊作者会利用这一特点,将与网站无关的关键词堆砌在网站标题处达到作弊的行为。
3 反作弊研究
搜索引擎作弊手段五花八门,层出不穷,但是从最根本的作弊技术进行分析,还有能够发现一些共通的内容。从基本的思路角度,可以将反作弊手段大致划分为以下三种:“信任传播模型”、“不信任传播模型”和“异常发现模型”。其中前两种技术模型可以进一步抽象归纳为“链接分析”中“子集传播模型”。
“信任传播模型”就是在海量的数据集合中通过一定的技术手段和半人工的方式筛选出能够完全信任的网页,可以理解为这些网页是完全不会作弊,可以称这些网页为白名单网页,搜索算法以这些白名单网页为起点,赋予白名单网页的链向网页以较高的权值,在搜索过程中判断其他网页是否存在作弊行为要看其和白名单内网页的链接关系来确定。白名单内的网页通过链接关系将信任度向外散播,如果中间的某个网页信任度低于给定的阈值,则认为该网页存在作弊行为。
“不信任传播模型”从整体的技术程度上来说和“信任传播模型”是类似的,区别在于“信任传播模型”起始点是信任节点,“不信任传播模型”起始点是不信任节点,即确定的作弊行为的节点,可以理解为是黑名单网页集合。赋予黑名单的各个网页节点一定的不信任度,通过网页之间的链接关系将不信任度向外传播,如果最后链向的页面节点的不信任阈值大于给定的值,则认为该页面节点存在作弊行为。总体来说,“信任传播模型”和“不信任传播模型”都可以认为是基于链接分析的方式来实现,都是通过对链接传播的扩散性来评判搜索页面是否存在作弊行为。
“异常发现模型”是区别于“信任传播模型”和“不信任传播模型”的链接分析模型,其主要基于一种假设:作弊网页必然存在某些特征有别于正常网页,这些特征可能是内容上,也可能是链接上的,通常先抓取一些作弊网页的集合,分析这些作弊网页存在的异常特征,然后利用这些异常特征来识别作弊网页。
4总结
本文主要分析了当前人们在信息检索时的主要方式,搜索引擎通过提取网站信息进行索引分析,将最匹配用户的网页推荐给用户。网站站长为了提高自身网站在搜索时的排名会采用多种作弊行为来干预排序,通过关键词堆砌和链接作弊等方式来恶性破坏公平性,本文试图从技术的角度分析各种作弊的行为的技术实现,并从实际出发来遏制此类作弊行为。
参考文献:
[1] 李智超,余慧佳,刘奕群,马少平. 网页作弊与反作弊技术综述[J]. 山东大学学报(理学版),2011(5):1-8.
[2] 肖卓磊. 搜索引擎作弊及反作弊技术探究[J]. 阜阳师范学院学报(自然科学版),2011(4):74-78.
[3] 王利刚,赵政文,赵鑫鑫. 搜索引擎中的反SEO作弊研究[J]. 计算机应用研究,2009(6):2035-2037.
[4] 赵静. 搜索引擎优化的作弊与防范[J]. 办公自动化,2010(22):8+19.
[5] 申华. 一种对抗社交网络链接作弊的算法[J]. 计算机与现代化,2015(7):1-4.
- 基于“双一流”建设的河北高校教师激励机制优化策略研究
- 生物制药厂废水处理技术分析
- 基于Mann-Kendall检验和小波分析的南昌降水变化特征研究
- 高校绿色发展的内涵及意义研究
- 市政污泥的处置及资源化利用综述
- 环境检测的作用与环境保护措施分析
- 生物絮凝技术在海产循环水养殖除氮中应用的可行性探究
- 生态农业发展中植物保护核心技术浅析
- 无砟轨道路基上拱偏移原因分析及整治措施
- 针对结构可靠度的分析与研究
- 基于主成分分析的致密砂砾岩储层岩性识别方法
- 大断面煤巷快速掘进施工工艺分析
- 基于绿色环保理念的建筑施工管理研究
- 测绘新技术在测绘工程测量中的应用分析
- 基于挠度差值影响线的简支梁桥损伤识别研究
- 计算机仿真学在足球领域的应用
- 城市轨道交通综合监控系统布局研究
- 云计算技术在高校计算机基础教学中的应用分析
- 城市治理体系和“数字政府”创新科技现代化问题研究
- 电气自动化控制中AI技术的应用
- 医用墙壁式负压吸引器的检测与数据分析
- 信息技术环境下农村语文教师如何构建智慧课堂
- 网络环境下高职辅导员工作模式优化研究
- 基于蓝色激光的氧化铟太赫兹透射特性研究
- 浅析GeoGebra软件在物理教学的应用
- performance apˌpraisal
- performanceassessment
- performance asˌsessment
- performancebond
- performance bond
- performanceevaluation
- performance evaluˌation
- performance fund
- performancefund
- performance indicator
- performanceindicator
- performancemanagement
- performance management
- performancerelatedpay
- performancereview
- performance reˌview
- performances
- performatory
- performed
- performer
- per-former
- performers
- performing
- per-forming
- performing arts
- 赍志以殒
- 赍志以没
- 赍志没地
- 赍志而殁
- 赍志而没
- 赍志重泉
- 赍志长逝
- 赍恨
- 赍恨九幽
- 赍恨入冥
- 赍恨泉壤
- 赍持
- 赍捧
- 赍擎
- 赍敕
- 赍汩
- 赍盗粮
- 赍盗食
- 赍秽
- 赍粮借寇
- 赍粮藉寇
- 赍装
- 赍议
- 赍貣
- 赍贷