张栖铭 袁瑞临 范凡 王峰

摘要:為了实现猪只不同状态下的自动检测,试验采用声音识别技术,设计了基于支持向量机算法(SVM)的声音识别方法,首先通过短时过零率和短时能量的端点检测,确定猪只不同状态的声音信号的起始点和终止点,然后提取声音信息的梅尔频率倒谱系数作为特征参数,使用SVM算法进行训练,建立声音的分类模型,最后对猪只不同状态进行识别。结果表明:猪只状态识别精度较高,达到了预期效果。
关键词:声音识别;SVM;MFCC;端点检测
中图分类号:TP391
文献标识码:A
文章编号:1009-3044(2017)10-0162-03
动物发声是动物行为的一种方式,可以通过叫声与其他成员进行有效交流,它能反映动物的生理状况如饥饿、疼痛、情绪状态等,因而基于动物声音的状态识别是有一定事实基础的。并且,随着计算机技术和数字信号处理技术的发展,声音识别技术已经取得了显著进步,动物的声音识别技术也得到了一定的发展。
因为猪只的声音信息可以很好的反馈猪只的状态,因此,本试验采用梅尔倒谱系数(MFCC)作为猪只声音的特征参数,然后将提取的特征参数,用来建立支持向量机(SVM)的分类模型,最后对不同状态的猪只声音进行识别,为规模化的养猪业提供客观的猪只状态监测。
1.算法介绍
1.1声音信号的端点检测
端点检测,声音处理中的一个重要方面,其作用是从包含声音的一段信号中确定出声音的起始点及终止点,区分声音和非声音信号。有效的端点检测不仅可以减少数据处理量,节约时间,而且能抑制无声段或噪声段的干扰,提高声音信号质量。利用短时能量和短时过零率进行双门限的端点检测。
短时能量是声音的一个重要的特性,对声音的能量分析主要集中在短时能量上。短时能量的定义如下:
1.2声音识别特征参数的提取(MFCC)
声音信号特征的梅尔倒谱系数(MFCC)法,是基于听觉特性的特征参数:不同频率的声音,在人耳内基础膜的不同位置振动。所以人耳就可以很容易辨别出各种状态的声音,此参数作为猪声音的识别参数能更好地反应各种声音信号的特性,从而极大地提高整个系统鲁棒性和系统的识别率。
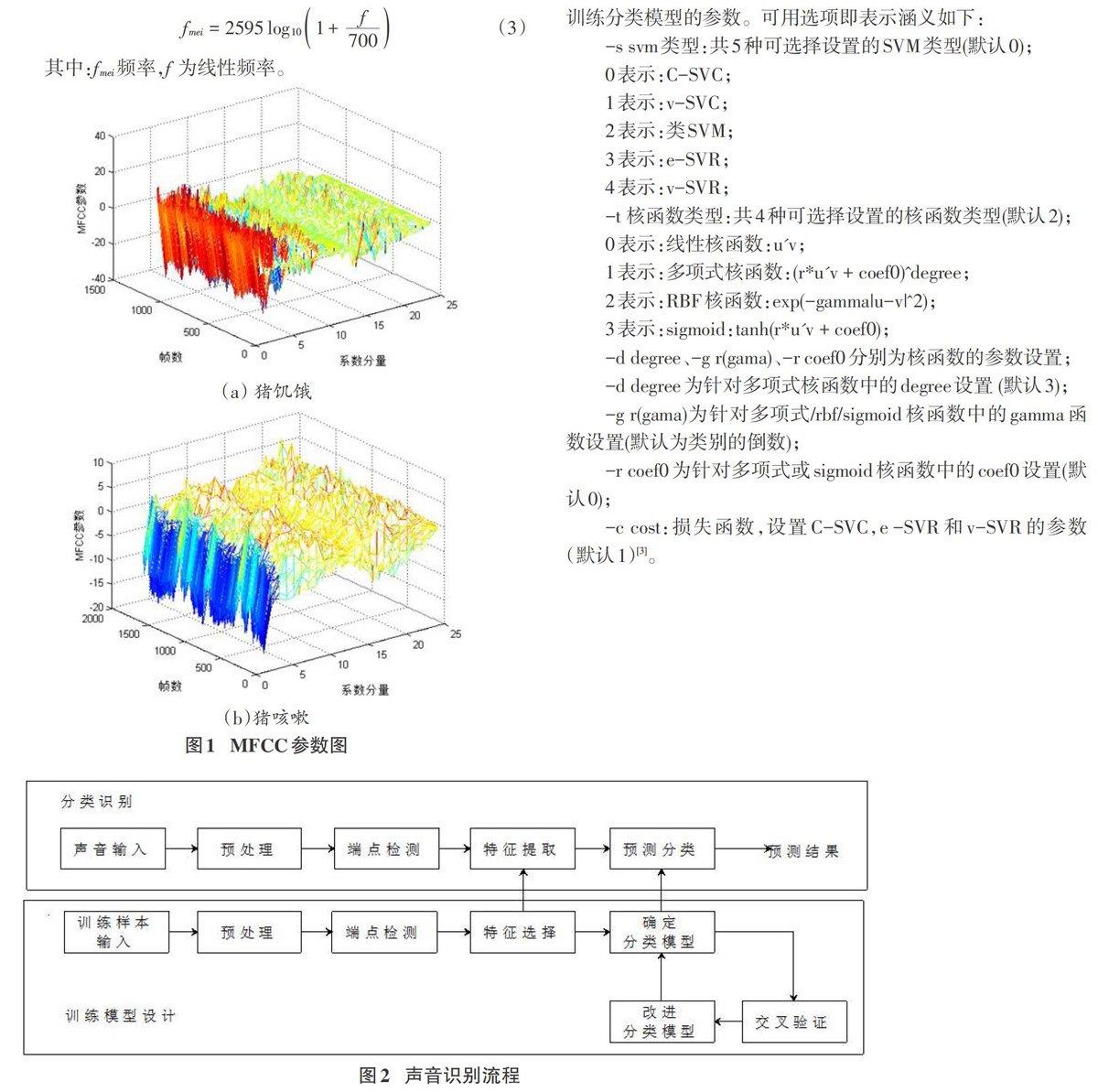
MFCC参数主要描述了声音信号在频域的能量分布,Mel频率的大小与实际频率呈对数分布。下式即为Mel频率与声音频(Hz)的关系式:
以两种猪只状态的声音为例,得到MFCC参数如图1,可以从图中看出,不同状态的猪只声音的特征参数有明显的区别,用此参数可以区别不同猪只状态。
1.3SVM算法
支持向量机(Support Vector Machine,SVM)是Vapnikm等人提出的一类新型机器学习方法。由于支持向量机在解决小样本问题、非线性问题及高维空间内的模式识别问题的时候有很多优点,所以其被广泛使用。
目前实行支持向量机的软件方法有Libsvm、Liblinear、mvs-VM、SVMlight等方法。中国台湾大学的林智仁(Chih-Jen Lin)教授等人设计了Libsvm软件,已经在多个操作系统平台上实现了支持向量机。该软件整合了交叉验证(Cross-Validation)的功能,能够方便地优化参数。利用Libsvm可以解决C支持向量分类机、v支持向量分类机、s支持向量回归机和v支持向量回归机等问题,以及基于1-v-1算法的多分类问题。
本试验中支持向量机采用的是Libsvm算法。Libsvm算法中的训练分类函数可以选择支持向量机的不同训练模式,其中,Option参数为训练分类模型的参数。可用选项即表示涵义如下:
2.实现猪只状态的识别
猪只的患病、争斗以及食欲情况都反映其生理健康状况。试验根据畜牧养殖从业人员的实际经验,选取了5种可以体现上述行为状态的猪只声音信息:小猪被压、猪打架、猪饥饿、猪吃料、猪咳嗽,作为本次试验的声音样本。
2.1猪声音识别流程
将采集到的五种猪只声音,一部分作为训练集,首先对声音信息进行预处理,即预加重、分帧、加窗;然后对声音进行双门限的端点检测,确定声音的起始点;将处理后的声音通过mel倒谱系数法提取声音特征值。将提取到的特征值通过SVM算法训练得到分类模型(model)。将其中一种猪只声音作为测试集,通过MFCC特征提取后,使用SVM算法分类预测出猪只状态。
图2是猪声音识别流程。
2.2程序分析结果
Option选项中,-c和-g决定了分类效果,通过交叉验证选择最佳参数-c和-g。我们得到的最佳参数是:
-c=0.125;-g=0.0078125。
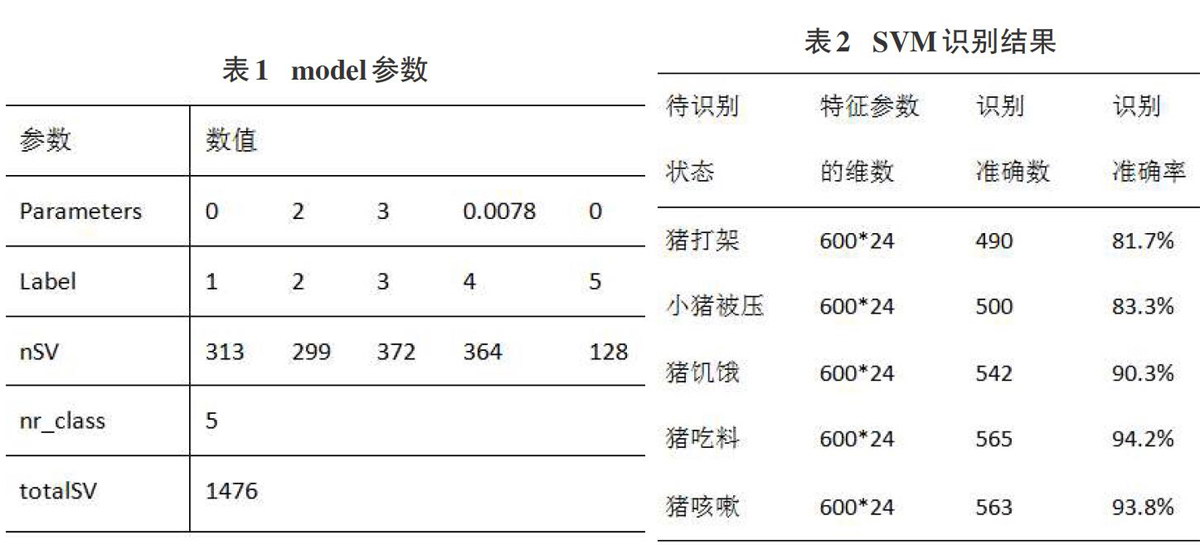
采用参数-c与-g对整个训练集进行训练获取支持向量机模型;训练得到的model参数:
分类模型(model)中主要参数说明:
(1)model.Parameters参数分别表示为:-s参数为0,为C-SVC函数;一t参数为2,采用RBF函数;-d参数为3;-gr(gama)为0.0078(优化得到的参数);-r coefO参数为0.
(2)model.Label表示训练数据的分类标签,本试验采用的是l,2,3,4,5。
(3)model.nr_class表示训练数据的分类个数,本试验是五分类。
(4)model.totalSV表示训练样本共有的支持向量数目,试验结果表明,共有1476个支持向量。
(5)model.nSV表示每类训练样本的支持向量的数目,分别是:标签为1的训练样本的支持向量数目有313个,标签为2的训练样本的支持向量数目有299个,标签为3的训练样本的支持向量数目有372个,标签为4的训练样本的支持向量数目有364个,标签为5的训练样本的支持向量数目有128个。
通过svmpredict函数对测试集进行识别预测。得表2识别结果,包含待识别猪只状态和识别准确率。
3.结论
试验设计了一种基于声音的猪只状态识别方法,通过短时能量和短时过零率的端点检测,选择梅尔倒谱系数作为声音特征参数,以SVM算法作为分类器识别预测5种状态下的猪只异常声音,识别准确率较高。但本试验训练数据不足,且预测环境较为理想,因此有很多地方需要改进。一方面需要增加训练数据量,另一方面,进一步研究现场环境中混杂在一起的各种猪声音以及噪音的问题,通过以上方法来提高系统的准确率及实用性。
- 京东商城网络营销策略 环境、问题及对策研究
- 浅析如何提升工商管理 在煤炭企业管理中的应用
- 电商网店营销策略及影响因素研究
- 关于大数据时代财务会计 向管理会计转型的若干思考
- “一带一路”背景下互联网 金融在多国贸易中的作用研究
- 浅谈如何开展地市供电公司班组减负工作
- 校园网络的搭建与设计
- 电子商务运营中的羊群效应主要特征研究
- 劳动仲裁中劳动者如何保护自身的合法权益
- 微信电商平台下大学生网购物流配送问题及对策研究
- 中国特色社会主义建设中协调发展的特色探究
- 试论项目管理在图书出版活动中的应用
- 创客空间环境设计中工业元素的应用
- 高质量融媒体新闻短视频的制作
- 对跨国公司研发国际化的认识
- 新居住时代,基于现代大学生住宿需求的新型发展模式
- 银行智能排队管理系统设计
- 新媒体环境下动漫产业现状及展望
- 从法律角度谈离婚冷静期
- 法学角度谈外观专利的相似性判断研究
- 亲属拒证制度研究
- 赤峰市旅游经济发展中 存在的问题及对策研究
- 基于经济学角度对期货模拟投资分析
- 电子商务对传统会计理论与实务的影响
- 试论商业银行个人金融业务转型发展的思考探究
- the big enchilada
- the big picture
- the big three, four, etc.
- the big time
- the birth of
- the blues
- the board/the board of directors
- the bomb
- the bottom
- the bottom drops/falls out of sth
- the bottom line
- the bourgeoisie
- the box
- the boys
- the boys/the girls
- the brainchild of sb
- the breadline
- the breadwinner
- the british isles
- the bronze age
- the bulk of
- the bulk (of sth)
- the burbs
- the butt of sth/sb
- the caribbean
- 一场空
- 一场空喜
- 一场空喜欢
- 一场空忙
- 一场空欢喜
- 一场美梦
- 一场虚惊
- 一场透雨
- 一坎子
- 一坐一起
- 一坐尽倾
- 一坐尽惊
- 一坐登天
- 一坐皆惊
- 一坐皆顺
- 一块
- 一块儿
- 一块土上的
- 一块地里能长五谷,也能长蒺藜和刺儿棵
- 一块好羊肉,落到狗口里
- 一块子
- 一块带肉馅儿的年糕——又黏又腻
- 一块带肉馅的年糕——又黏又腻
- 一块废铁
- 一块板