郭淑敏 朱蓉 王品品 胡胜 陈佳辉


摘要:随着互联网行业的迅速发展,电子邮件营销得到快速发展,但垃圾邮件的日趋严重浪费着网络资源,因此过滤垃圾邮件刻不容缓。该文通过介绍朴素贝叶斯算法的原理及它在垃圾邮件过滤这方面的应用,基于朴素贝叶斯算法的分类模型设计了一个文本广告邮件过滤系统,能够有效实现垃圾邮件过滤。该系统的特点是在中文分词部分添加了当前的网络热词,从而进一步提高了系统的实用性。本系统通过在包含合法邮件与垃圾邮件的数据库上进行实验测试,针对垃圾邮件的分类获得了较高的正确率。
关键词:垃圾邮件;贝叶斯算法;过滤器
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2017)13-0171-03
伴随着互联网时代的到来,利用科学技术传递消息的方式多种多样,电话、QQ、电子邮件、微信、微博等都成了人们日常生活中不可缺少的交流平台。与之诞生的还有相应的电子营销手段,如今人们发送电子邮件取代传统邮件,成为一些电商进行宣传和推广产品的重要手段,但与此同时来势汹汹的垃圾邮件使得整个网络不堪重负。面对垃圾邮件的猖獗,技术人员开发各种阻止垃圾邮件的方法。例如:黑名单技术,它将经常发送垃圾的IP地址范围、域名等属性都列入一个黑名单,凡是从黑名单所包含的IP地址发送来的邮件都被判定为垃圾邮件,但这种方法也会误屏蔽IP地址,导致正常的通信无法进行。另一种技术就是过滤技术,它根据某种算法或规则,来判断垃圾邮件,最先出现的是基于模式匹配的算法规则,它通过关键词检索来判断垃圾邮件,然后是支持正则表达式的模糊匹配。随着信息技术的发展,基于分类算法的过滤成为现在最流行的技术,其中:基于贝叶斯算法的分类能够获得良好的垃圾邮件过滤效果受到广泛研究者的关注。这种方法用先验概率对邮件进行判断,并且可以在分类算法中添加自学功能,通过不断地校正先验概率来提高垃圾邮件过滤的准确性。
1贝叶斯定理
条件概率P(TIC)是指事件C已经发生的前提下,事件T发生的概率。基本求解公式如下:
条件概率P(CIT)J就是事件T发生条件下事件C的概率P,贝叶斯定理就是利用式1计算P(CIT),然而在实际应用中经常会遇到这种情况:容易求解P(TIC)而P(CIT)求解困难,但是P(CIT)可根据P(TIC)求出。下面给出贝叶斯公式:
贝叶斯定理即当已知事件C的概率P(Ci)和事件C已发生条件下事件T的概率P(T|Ci),则可运用贝叶斯定理计算出在事件T发生条件下事件Ci的概率P(Ci|T)。将贝叶斯定理应用于分类问题时,用集合c={c1,c2…|表示类别,把事物的众多属性看做一个向量,用向量T=(t1,t2,…,tn)来代表这个事物。所谓将事物分类,即将T归类为C中的一个类别。T被称为属性集。一般T与C的关系是不确定的,你只能说在某种程度说T属于类c1的可能性是多大,这时可以把T和C看做是随机变量,P(CIT)称为C的后驗概率,与之相对的,P(C)称为C的先验概率。
在训练阶段,根据从训练数据里收集的信息,我们对T和c的每一种组合计算后验概率P(CIT)。在分类的时候,对于新来的一个实例t,我们就要从在之前训练得到的一堆的后验概率里找到所有的P(Clt),计算C值,在这些C值中找到最大的那个C,它就是t被判定的可能的所属分类。根据贝叶斯公式,后验概率为:
(3)
由于在结果比较不同的C值的后验概率的时候,分母P(t)总是常数,因此可以被忽略不计。而先验概率P(C)则可以通过计算训练集中属于每—个类的训练样本所占的比例容易地被估计。
2朴素贝叶斯分类器
朴素贝叶斯分类器在估计类条件概率时,假设各属性之间是条件独立的。在进行文本分类时,对于某一个文本可以用一个文本特征向量来表示:t=(t1,t2,…,tn)。一般在文本中,各个单词之间根据语义理解是具有一定的上下文联系的,并不是相互独立的。为了采用朴素贝叶斯对文本进行分类,假定单词之间没有联系。将输入t分到后验概率最大的类C。公式如下:
(4)
当训练集合比较小时,概率计算P(tj|ck)的结果不会很合理,因为概率值需要经过大量的统计规律而得。本文采用另外一种近似方法来计算,这种方法被称作拉普拉斯变换。故后验概率计算公式如下:
(5)
3系统的设计与实现
3.1系统流程介绍
为了验证本文中提出的方法,开发了一个基于贝叶斯分类器的邮件过滤系统。由于本文研究对象主要针对网络营销类垃圾邮件,故所有垃圾邮件都指的是营销类垃圾邮件,合法邮件是指除营销类垃圾邮件以外的所有邮件。邮件过滤系统主要包含:邮件样本收集、邮件预处理、中文分词、邮件过滤四个部分,系统流程如下图所示:
在邮件过滤系统中,中文分词的好坏影响系统有效性。中文分词是中文信息处理的前提,词库是中文自动分词的基础。中文分词是将一句话分解成一个一个的单词,这些单词可以作为特征项来对文本进行区分。只有建立适当的字典,系统才能够依赖于特征项对文本进行合理理解和过滤。常用的分词算法分为三大类:基于字符串匹配、基于理解和基于统计的分词方法。
在基于理解的方法中,分词系统是由词库、知识库和推理机三个部分组成。推理机制利用词库和知识库提供的大量数据和知识,来模拟语言学家的逻辑思维过程,以此实现自动分词。基于字符串匹配的分词方法(机械匹配算法)主要利用字符串匹配的原理,将文档中的字符串和词典中的词条进行逐一的匹配,如果在词典中匹配到一个字符串,则可以切分。基于统计的分词法的原理是根据字符串在语料库中出现的频率来判断它是否构成单词,字与字相邻共现的频率能够较好地反映它们成为词的可信度。本文中采用的就是基于统计的分词方法。
3.2特征选择
特征选择算法可以降低文本特征向量的维度、去除冗余特征、保持分化特性。在垃圾邮件过滤中,足够的训练样本和高覆盖的单词有利于垃圾邮件的有效分类。如果特征选择做得不好,特征库的维度就变大,向量维数过高会造成文本向量计算困难问题。高维文本向量不仅存在冗余信息,导致误判,而且影响分类器性能。因此需要经过特征选择的步骤。文档频度是指一个特征项在语料库中出现的文档数量的统计,可以通过设定一个特定阈值来实现,如果某一个特征项的文档频度小于给定阈值则被过滤掉,这样不仅可以从训练集特征词典中过滤掉一些相对意义不大的特征项,而且可以降低特征项空间维度。通过实验数据表明,中文语料库的最佳特征集合大小范围为1200-1800。
3.3添加热词
本文中使用的词库来源于从网络上下载的SDIC.txt文件,包括词条43970条,基础词汇量丰富。然而,由于互联网的快速发展,近期网络热词传播速度极快,传播范围广,且被网友广泛接受并使用,将热词添加入词库对于提高中文分词的准确度有帮助。因此,本系统在中文分词模块中,对原有基础词库进行了扩充,如加了当前一些广为人知的热词。部分新增词条比如“壁咚、网红、Duang、屌絲、小清新、元芳、重口味、吐槽、你妹、正能量、卖萌、点赞、HOLD住、学生党、考研狗、单身狗、且行且珍惜、画面太美我不敢看、我爸是李刚、么么哒、打老虎、上天台、也是醉了、也是蛮拼的、神马、造、臣妾做不到”等等。
3.4实验结果与分析
假定被判定为垃圾邮件的营销类邮件中垃圾邮件个数为A、合法邮件个数为B;被判定为合法邮件的营销类邮件中垃圾邮件个数为C、合法邮件个数为D。总营销邮件的个数N为:N=A+B+C+D。
其中:召回率(Recall):R=(A/(A+C))*100%;即垃圾邮件检出率。该指标反映了过滤系统发现垃圾邮件的能力,召回率越高,“漏网”的垃圾邮件就越少。
正确率(Precision):P=(A/(A+B)*100%;即垃圾邮件检对率。该指标反映了过滤系统“找对”垃圾邮件的能力,正确率越大,将合法邮件误判为垃圾邮件的可能性越小。
精确率(Accuracy):A=((A+D)/N)*100%;即对所有营销邮件(包括垃圾邮件和合法邮件)的判对率。
错误率(Error rate):E=1-A;即对所有营销邮件(包括垃圾邮件和合法邮件)的判错率。
F值:召回率和正确率的调和平均值,它将召回率和正确率综合成一个指标。
除此之外,还可以采用虚报率(Fallout)、漏报率(Miss rate)等指标。
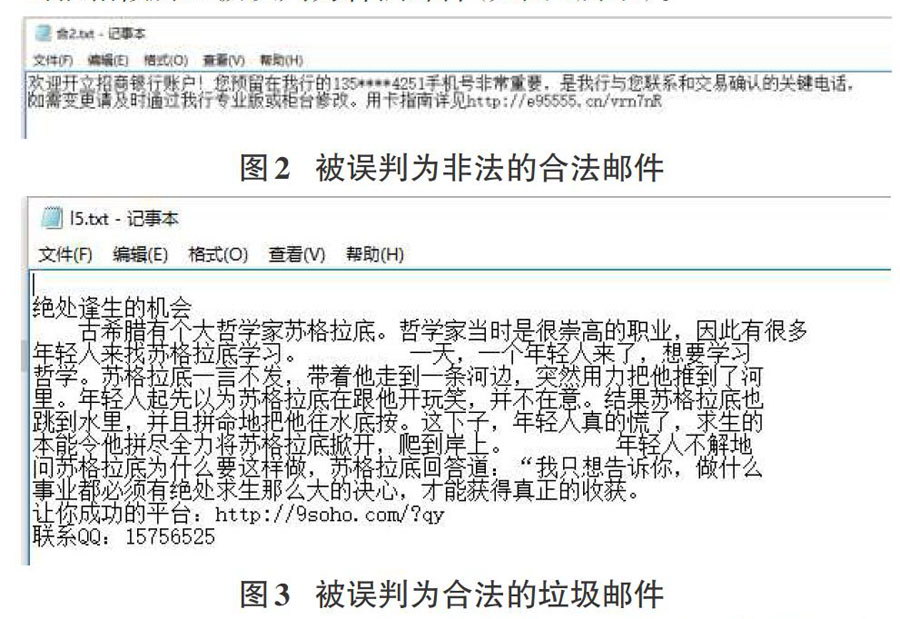
本实验的训练集和测试集采用了相同数量的合法邮件和垃圾邮件,当被测邮件为传统的垃圾邮件时,测试结果为94.2%的正确率,这证明了朴素贝叶斯分类器的确准确又快速。尽管相比于传统的垃圾邮件过滤无法解决网络热词,本系统能够较好地处理包含设定网络热词的邮件,但是当被检测的邮件变成时下热门的修改账号密码的门户网站发来的回执文档,或者成功注册成为某网站会员的提醒邮件、网上购物订单号的告知邮件等邮件时(如图2所示),一些应当被认为是合法邮件的邮件被分类器判定为非法邮件。还有一些利用哲学故事传播信息或者假借某平台传递消息的垃圾邮件等,由于与合法邮件关键词很相似所以被误判为合法邮件(如图3所示)。
需要说明的是,在实验中训练集与测试集中邮件的数量比例设置为1:1。若训练集与测试集的数量比例过高,会导致训练数据过拟合,无法正确对测试邮件进行分类;反之,若训练集与测试集的数量比例偏小,分类器学习的程度不能达到预期效果。这时由于采集的特征值数量过小的话,根据少量特征值去判断大容量的邮件,就会导致学习获得的分类器失效,出现机器的“主观臆断”现象。
4结束语
本文介绍了基于贝叶斯算法过滤垃圾邮件的主要方式,设计了一个简单的基于朴素贝叶斯方法的纯文本垃圾邮件过滤系统,并通过实验验证了朴素贝叶斯方法在垃圾邮件分类上有着快速且有效的作用。除此之外,本系统存在的不足之处有针对的对象是纯文本邮件,然而随着时代发展,邮件中多带有链接、附件、图片等非文本内容,为了提升分类器分类性能,后续应该将邮件中的非文本内容解析出来并作为特征值存在向量空间模型中。这样,对于文本内容为空但是带有附件的邮件,对于带有特大型附件并且文本内容特别长的这些具有明显特征的邮件,分类器也能自动将其正确分类。
- 标准化护理策略在急性缺血性脑卒中机械取栓绿色通道中的应用价值
- 针对性急救护理在小儿高热惊厥急诊护理中的应用
- 风险管理在神经内科护理工作中的应用
- 心理护理干预对冠心病患者负性情绪和生活质量改善的临床价值研究
- 小儿急性化脓性扁桃体炎护理干预措施
- 探讨专科特色护理在耳鼻喉科患者自护水平中的应用
- 轻度胆结石的预防及日常护理注意事项
- 小儿肺炎合并心力衰竭的临床护理措施分析
- 关于重症监护室护理人文关怀的思考
- 门诊导诊优质护理服务的实践观察
- 人性化护理在传染病护理工作中的应用
- 护理质量持续改进在子宫肌瘤护理中的应用体会
- 健康教育在高血压护理中的应用评价
- 康复护理对老年高血压合并动脉粥样硬化患者的护理效果
- 数字化病案管理系统在病案管理中的应用
- 街道社区疾病预防控制管理的强化分析
- 从承德市《出生医学证明》应用实际出发分析其社会作用及监管服务对策
- 心血管疾病治疗时他汀类药物使用护理策略
- 提升卫生行政档案管理人员素质的策略
- 理化检验质量控制在突发公共卫生事件中的意义
- 细节管理在医院消毒供应中心中的应用效果
- 浅析分类管理在科研档案资料管理中的应用
- 门诊药房处方实时审核强化管理的应用效果分析
- 医疗设备管理中近距离无线通讯技术的整合运用分析
- 细节管理在心内科护理管理中的应用
- it's snowing
- it's sprinkling
- it's swings and roundabouts/it cuts both ways
- it's/that's a good idea
- its/their place
- it's/there's no use
- it sticks/stands out a mile
- it sticks/stands out like a sore thumb
- it's touch and go
- it's true that
- it's unfortunate
- it support
- it's worth
- it transpires that
- it-up
- itv
- it wasn't long before
- it won't break the bank
- it won't do you any good/it won't get you anywhere
- iud
- iuds
- iv
- i've
- ivier
- ivies'
- 贾傅
- 贾儿
- 贾元春
- 贾充香
- 贾公彦
- 贾兰
- 贾其余勇
- 贾利
- 贾勇
- 贾勇争先
- 贾勇有余
- 贾化
- 贾区
- 贾后
- 贾售
- 贾商
- 贾国
- 贾奇
- 贾女偷香
- 贾女香
- 贾妻含笑
- 贾娘
- 贾子贾女
- 贾宅
- 贾官