宗小忠

摘要:提出一个智能网络课程系统模型,采用B/S结构,系统的智能核心是智能预测推荐系统。该模型采用了离线部分挖掘与在线部分挖掘相分离思路,重点论述了基于Web挖掘的智能网络课程系统模型的体系结构,并对算法进行了验证分析。
关键词:Web挖掘;Web日志;关联规则;数据预处理
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2017)30-0027-02
Research and Application of Web Data Mining on Intelligent Network Course System
ZONG Xiao-zhong
(Shazhou Polytechnical Institute of Technology, Zhangjiagang 215600, China)
Abstract:Based on web mining theory and technology,introduced the process of the web mining.the article proposed a module of intelligent network course system, adopts B/S model, mainly includes two problems:the first, is intelligent forecast of students visited the curriculum resources; secondly, is dig out the hot course; Finally in the form of visualization relayed to the students. System of intelligent core is intelligent forecast recommend system. This model used offline part of mining and the on-line partial mining phase separation mentality, discusses the intelligent network Based on Web mining system structure of curriculum system model, and verified algorithm by analysis.
Key words: web mining;web usage;association rule;data preprocessing
1 概述
随着信息技术的日益发展,信息逐步数字化,人们正面临“数据丰富而知识贫乏”的问题。八十年代末兴起的数据挖掘( data mining )技术为解决此问题提供了方法。数据挖掘是在大量的看似无序的数据中发现潜在的、有价值的模式和数据间关系(知识)的过程。随着Internet和计算机技术的快速发展,基于Web的网络教育已经成为现代教育的一种重要方式。利用网络,可以进行在线学习、辅导、答疑、交流等,为师生提供丰富的教学资源,创造了一个无障碍交流互动平台。
数据挖掘是从大量数据中提取或“挖掘”知识[1]。从Web文档和访问数据中发现并抽取信息,可以从海量的Web访问数据中发现学生的学习兴趣、方向、访问习惯等,并可以给同学推荐合适的课程内容和学习资料。数据挖掘为网络课程系统的智能化、个性化提供了重要的手段。挖掘用户访问行为的潜在模式,预测用户可能访问的结果,智能地选择、推荐与用户兴趣接近的网络信息。
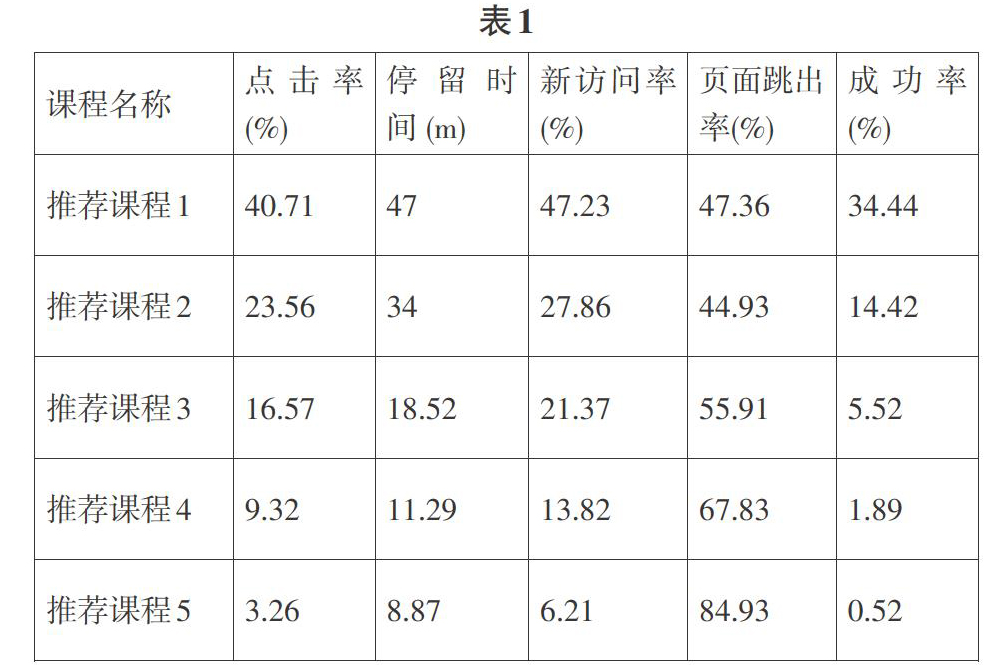
2 Web挖掘
2.1 基本概念
Web挖掘的概念:Web挖掘是在大量的文档收集C中识别潜在的模式p的一种活动,其中C和p的关系可以用映射:[ξ:C→p表示][3]。
Web信息的具体结构如图1所示:
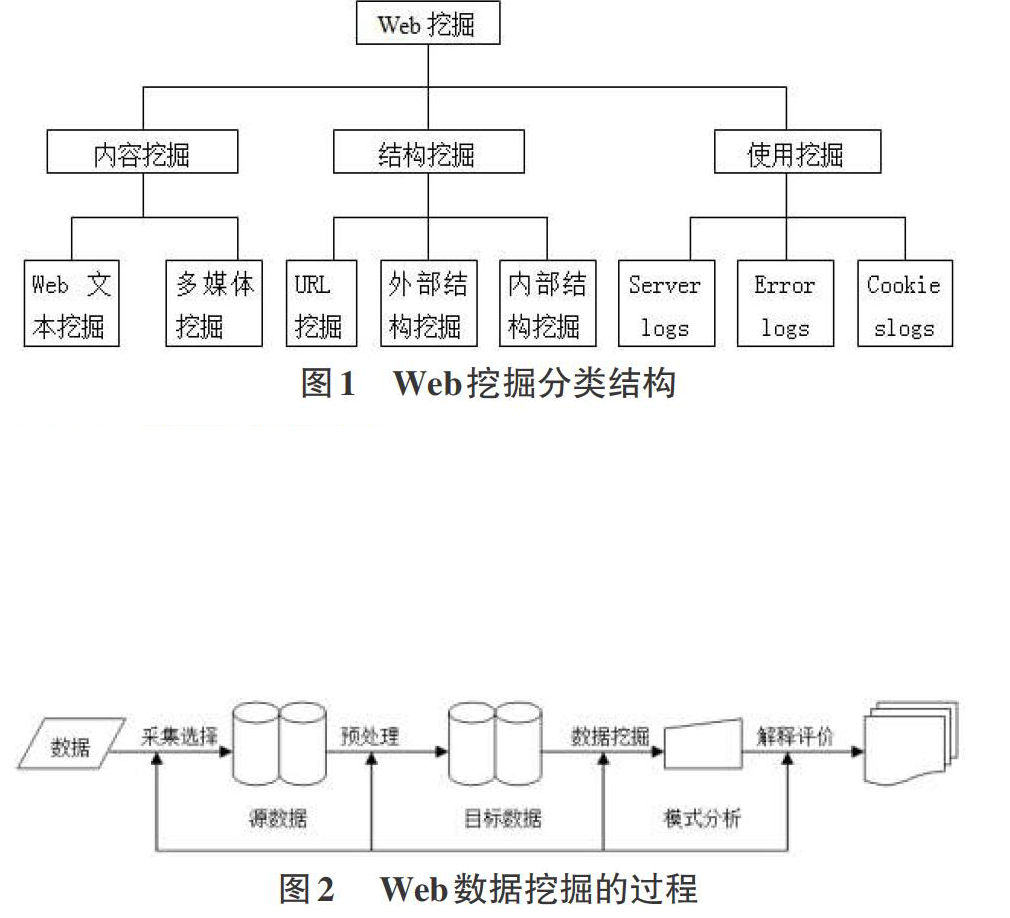
2.2 Web数据挖掘的过程
与传统数据库和数据仓库相比,Web上的信息是非结构化或半结构化的、动态的、并且是容易造成混淆的,所有很难直接对Web网页上的数据进行挖掘,而必须经过必要的数据处理。典型Web挖掘的处理流程如图2所示[4]。
3 基于Web挖掘的智能课程系统模型设计
3.1 体系结构功能
智能课程系统主要想实现两个方面的问题:一是对学生访问课程资源的智能预测;二是挖掘出热点课程;最后以可视化的形式传递给学生。本系统采用B/S模型,系统的智能核心是智能预测推荐系统。其模型结构如图3所示:
本智能课程系统课程类型主要有两类:视频和HTML格式。课程大约有3000门。在校学生人数大約为8000千人。
在图3中,数据挖掘的主要数据来源有课程基本信息、学生的基本信息和学生访问记录等。通过图3可以看出,离线模块进行特征抽取和规则生成,预测推荐系统在线把推荐结果反馈给学生,达到个性化教学的目的。采用挖掘技术,可以提高系统的智能化,使系统具有自主性、自适应性和合作性等特点[4]。
3.2 实现思路
1) 先测算某人访问某一个课程的访问率
如果以[fi]表示第[i]访问该课程的访问度,即:第一次访问[f1=1],第二次访问[f2=2]…,以[xi]表示第[i]次访问这个课程时间长度,则可以通过加权平均法计算一个课程的访问率,即:
[x=f1x1+f2x2+…+fkxkf1+f2+…+fk=i=1kfixii=1kfi=fxf]
2) 在本月若有N个人访问过该课程,按照上述公式,则可以分别计算出这N个人对该课程的访问率,然后计算出这个课程的平均访问率,即:
[X=x1+x2+…+xNN]
3) 在多個课程中,如何测算出哪些课程受欢迎程度呢?则可以以一个月时间进行内测,通过计算每个课程的平均访问率,然后排名,就可以得出结论。
4) 第二个月开始,我们就可以按照以下方式进行课程筛选了。
为了准确地表示每个课程的访问率的变异程度,可以考虑以第一个月的内测平均访问率为标准,求出本月各个课程的平均访问率与内测平均访问率的离差,即([X-X]),称为离均差。离均差能表达一个观测值偏离平均数的性质和程度,因为离均差有正、有负。显然,离均差越大,说明这个课程受欢迎程度越大。
4 仿真结果与分析
根据挖掘的结果,我们在线给每个登陆系统的同学预测了5课程。为了验证该模型的可行性,我们设置系统的权重h=1.8,并对推荐给学生的课程点击率、停留时间、新访问率、页面跳出率、进行了统计,进行了手工计算,得出的结果如表 1所示。
从表1中所示,我们手工设置通过对访问时间和访问次数进行加权平均法计算,则可以得出对学生访问课程资源的智能预测;预测成功率可达56.80%。
5 结束语
本文通过在课程平台中应用Web挖掘技术,并对学生访问记录进行分析和数据挖掘,发现数据间的内在规律,理解用户的行为,并据此为依据进行有针对性的信息提取,为用户提供个性化的服务或改善站资源提供的内容,提高用户搜索的准确率。
本文研究的问题是利用Web使用挖掘动态的引导用户选择适当的课程,基于以往的访问记录,立即推荐给下次合适的课程。本文给出了模型的具体结构及主要思路,为同类研究提供了一种有益参考。实践证明基于Web挖掘技术在精品课程系统中的应用提高了精品课程系统的个性服务水平,为系统的决策分析提供了智能的辅助手段。
参考文献:
[1] Jiawei Han,Micheline Kamber. 数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2006.
[2] 朱志国.Web使用模式挖掘系统的框架设计[J].信息系统,2010,33(4):97-101.
[3] 申丽君,孟凡荣.基于XML的Web文本挖掘模型的研究与设计[J].计算机工程与设计,2007,28(10):2287-2230.
[4] 付文兰,杨国林. Web数据挖掘在个性化搜索引擎中的研究与应用[J].内蒙古农业大学学报,2009,30(4):223-226.
[5] 杨锟,孟波. 一种基于XML的Web数据挖掘方法[J].计算机应用,2003,23(6):160-161.
[6] 吴学治,张景,李军怀,等.一种基于日志挖掘的自适应缓存调试优化算法[J].计算机工程,2006,32(11):116-118.
[7] 郭秋萍,王全兰.一种基于Web挖掘的图书馆服务推荐模型及其算法研究[J].图书馆杂志,2010,29(6):53-54.
[8] 罗兴文,闫友彪,蔡海滨.基于Web挖掘的个性化远程教育系统研究[J].计算机工程与设计,2007,28(12):3016-3022.
[9] 许晓东,李柯,朱士瑞. Web 使用挖掘Apriori算法的改进研究[J].计算机工程与设计,2010,31(3):539-541.
- 浅析毛泽东诗词中的人民性
- 景县后留名府乡:以“三个狠抓”助推“三创四建”活动开展
- 邯郸冀南新区林坛镇:种养循环有甜头 脱贫致富有奔头
- 党旗下的美丽蝶变
- 加强公立医院作风纪律建设探析
- 地方高校少数民族大学生社会主义核心价值观教育现状及对策思考
- 试论教师党支部在高校青年教师思想政治工作中的作用
- 浅析教育扶贫面临的问题与不足
- 弘扬南泥湾精神 建设现代化强国
- 关于《论持久战》一文的若干思考
- 领导干部当多些“亲历亲为”
- 改革开放与中国特色社会主义
- 高校学生党建工作精准化的困境与突破
- 新时代党员质量评价指标体系的构建与应用
- 践行新时代党的组织路线的路径思考
- 社会组织参与精准扶贫的现状与展望
- 高举中国特色社会主义伟大旗帜
- 马克思经济周期理论视角下的中国经济新常态
- 我国高校研究生教育资源优化配置路径选择
- 王化一与东北中学的抗战教育
- 社会主义核心价值观引领当代大学生价值取向路径选择
- 创建国家卫生城市与提升城市品质
- 沈阳锡伯家庙与民族认同重构
- 网络文化时尚对大学生的影响及引导措施
- 胡世宗诗集《雪葬》的历史意识
- e-number
- e-numbers
- enumerability
- enumerate
- enumerated
- enumerates
- enumerating
- enumeration
- enumerations
- enumeratively
- envelop
- envelope
- enveloped
- enveloper
- envelopers
- envelopes
- enveloping
- envelopment
- envelopments
- envelops
- enverdure
- enviability
- enviable
- enviableness
- enviablenesses
- 担迟弗担差
- 担送伤病员的活动床
- 担针桥
- 担险
- 担隔夜忧
- 担雪塞井
- 担雪塞井空用力,炊砂作饭岂堪食
- 担雪填井
- 担雪填井——没个满的日子
- 担雪填井——没有个满的日子
- 担雪填井——白费力
- 担雪填井——误人不浅
- 担雪填河
- 担雪填深井
- 担雪往井里填
- 担风握月
- 担风袖月
- 担风险
- 担饥受冻
- 担饥受馁
- 担饥忍饿
- 担饶
- 担鬼胎
- 担鼓
- 拆